Hunyuan Video | Texte en Vidéo
Hunyuan Video est un modèle de base vidéo open-source développé par Tencent. Il offre des performances de génération de vidéo comparables, voire supérieures, aux modèles fermés de premier plan. En tirant parti de techniques avancées telles que la curation de données, l'entraînement conjoint image-vidéo et une infrastructure optimisée, Hunyuan Video permet une génération de vidéos de haute qualité et à grande échelle.Flux de travail ComfyUI Hunyuan Video
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI Hunyuan Video
Description ComfyUI Hunyuan Video
est un modèle de base vidéo open-source innovant qui offre des performances en génération de vidéo comparables, voire supérieures, aux meilleurs modèles fermés, développé par Tencent, une entreprise technologique de premier plan. Hunyuan Video utilise des technologies de pointe pour l'apprentissage du modèle, telles que la curation de données, l'entraînement conjoint du modèle image-vidéo et une infrastructure efficace pour l'entraînement et l'inférence de modèles à grande échelle. Hunyuan Video possède le plus grand modèle génératif vidéo open-source avec plus de 13 milliards de paramètres.
Les fonctionnalités clés de Hunyuan Video incluent
- Hunyuan Video offre une architecture unifiée pour générer à la fois des images et des vidéos. Il utilise une conception spéciale de modèle Transformer appelée "Dual-stream to Single-stream". Cela signifie que le modèle traite d'abord séparément les informations vidéo et texte, puis les combine pour créer le résultat final. Cela aide le modèle à mieux comprendre la relation entre les visuels et la description textuelle.
- L'encodeur de texte dans Hunyuan Video est basé sur un Modèle de Langage Multimodal (MLLM). Comparé à d'autres encodeurs de texte populaires comme CLIP et T5-XXL, MLLM est meilleur pour aligner le texte avec les images. Il peut également fournir des descriptions plus détaillées et un raisonnement sur le contenu. Cela aide Hunyuan Video à générer des vidéos qui correspondent plus précisément au texte d'entrée.
- Pour gérer efficacement les vidéos à haute résolution et à haute fréquence d'images, Hunyuan Video utilise un Autoencodeur Variationnel 3D (VAE) avec CausalConv3D. Ce composant compresse les vidéos et les images dans une représentation plus petite appelée espace latent. En travaillant dans cet espace compressé, Hunyuan Video peut s'entraîner et générer des vidéos à leur résolution et fréquence d'images d'origine sans utiliser trop de ressources informatiques.
- Hunyuan Video inclut un modèle de réécriture de prompt qui peut adapter automatiquement le texte d'entrée de l'utilisateur pour mieux s'adapter aux préférences du modèle. Il existe deux modes disponibles : Normal et Master. Le mode Normal se concentre sur l'amélioration de la compréhension des instructions de l'utilisateur par le modèle, tandis que le mode Master met l'accent sur la création de vidéos de qualité visuelle supérieure. Cependant, le mode Master peut parfois négliger certains détails du texte au profit d'une meilleure apparence de la vidéo.
Utilisez Hunyuan Video dans ComfyUI
Ces nœuds et les flux de travail associés ont été développés par Kijai. Nous rendons tout le crédit dû à Kijai pour ce travail innovant. Sur la plateforme RunComfy, nous présentons simplement ses contributions à la communauté.
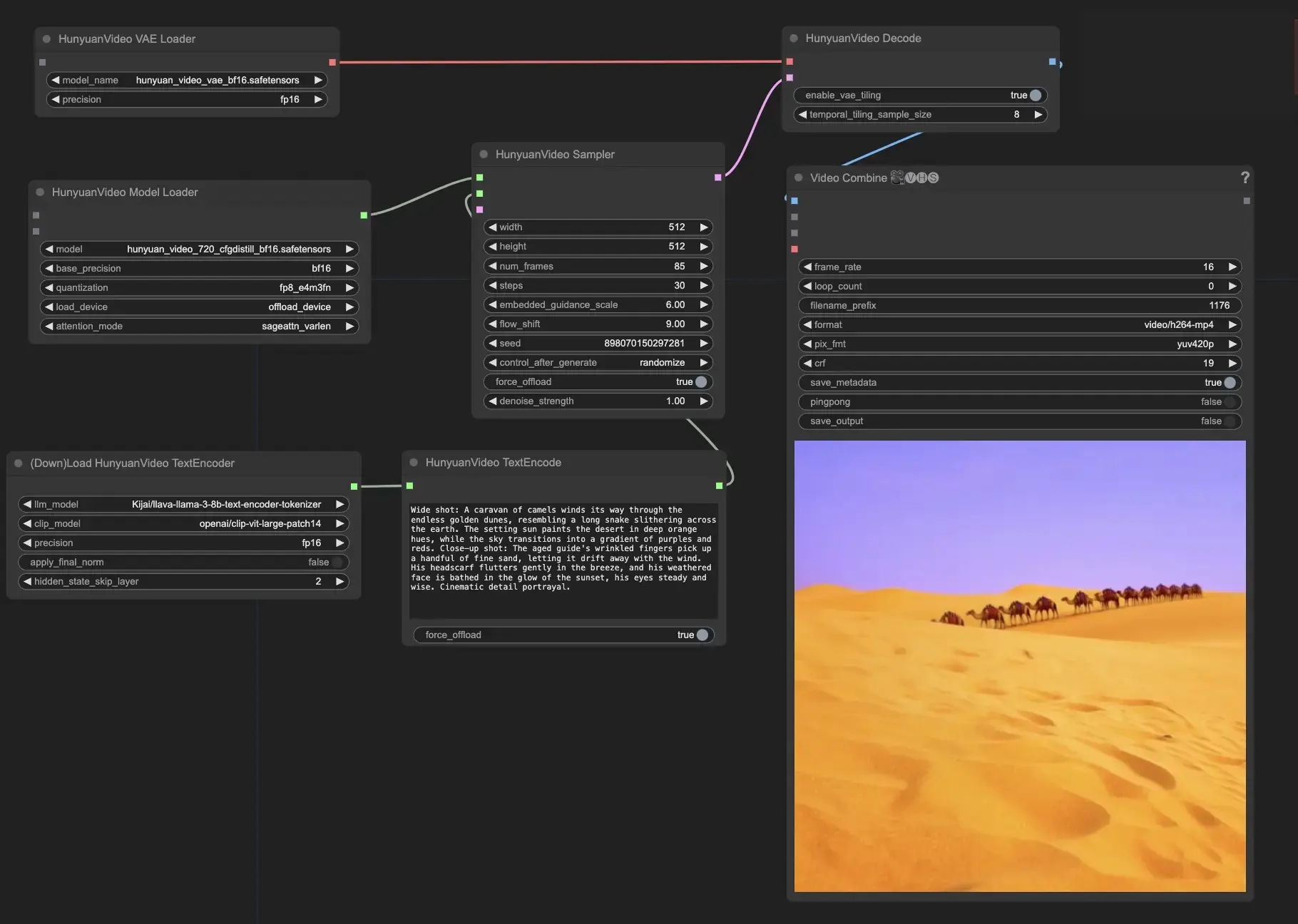
- Fournissez votre texte de prompt : Dans le nœud HunyuanVideoTextEncode, entrez votre texte de prompt souhaité dans le champ "prompt". sont quelques exemples de prompt pour votre référence.
- Configurez les paramètres de sortie vidéo dans le nœud HunyuanVideoSampler :
- Réglez la "largeur" et la "hauteur" à votre résolution préférée
- Réglez le "num_frames" à la longueur de vidéo souhaitée en images
- "steps" contrôle le nombre d'étapes de débruitage/échantillonnage (par défaut : 30)
- "embedded_guidance_scale" détermine la force de l'orientation du prompt (par défaut : 6.0)
- "flow_shift" affecte la longueur de la vidéo (des valeurs plus grandes donnent des vidéos plus courtes, par défaut : 9.0)

