Stable Diffusion 3.5
Stable Diffusion 3.5 (SD3.5) est un nouveau modèle open-source qui génère des images variées et de haute qualité à partir d'invites textuelles. SD3.5 excelle à créer divers styles et à respecter les invites. Malgré certaines limites en anatomie et résolution, SD3.5 est un outil puissant pour la création visuelle. Explorez SD3.5 dans ComfyUI pour créer des visuels époustouflants avec facilité.Flux de travail ComfyUI Stable Diffusion 3.5
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI Stable Diffusion 3.5




Description ComfyUI Stable Diffusion 3.5
Stability AI a dévoilé , un modèle d'IA génératif multimodal open-source qui inclut plusieurs variantes telles que Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo et Stable Diffusion 3.5 (SD3.5) Medium. Ces modèles sont hautement personnalisables, capables de fonctionner sur du matériel grand public. Les modèles SD3.5 Large et Large Turbo sont immédiatement disponibles, tandis que la version Medium sera publiée le 29 octobre 2024.
1. Comment fonctionne Stable Diffusion 3.5 (SD3.5)
À un niveau technique, Stable Diffusion 3.5 (SD3.5) prend une invite textuelle en entrée, la code dans un espace latent à l'aide de codeurs textuels basés sur des transformateurs, puis décode cette représentation latente en une image de sortie à l'aide d'un décodeur basé sur la diffusion. Les codeurs textuels de transformateur, tels que le modèle CLIP (Contrastive Language-Image Pre-training), mappent l'invite d'entrée en une représentation compressée sémantiquement significative dans l'espace latent. Ce code latent est ensuite débruité de façon itérative par le décodeur de diffusion sur plusieurs étapes pour générer l'image finale. Le processus de diffusion consiste à éliminer progressivement le bruit d'une représentation latente initialement bruyante, conditionnée par l'embedding textuel, jusqu'à ce qu'une image nette émerge.
Les différentes tailles de modèles dans Stable Diffusion 3.5 (SD3.5) (Large, Medium) se réfèrent au nombre de paramètres entraînables - 8 milliards pour le modèle Large et 2,5 milliards pour le Medium. Plus de paramètres permettent généralement au modèle de capturer plus de connaissances et de nuances de ses données d'entraînement. Les modèles Turbo sont des versions distillées qui sacrifient une certaine qualité pour des vitesses d'inférence beaucoup plus rapides. La distillation implique l'entraînement d'un modèle "élève" plus petit pour imiter les sorties d'un modèle "enseignant" plus grand, visant à conserver la plupart des capacités dans une architecture plus efficace.
2. Points forts des modèles Stable Diffusion 3.5 (SD3.5)
2.1. Personnalisabilité
Les modèles Stable Diffusion 3.5 (SD3.5) sont conçus pour être facilement ajustés et développés pour des applications spécifiques. La normalisation Query-Key a été intégrée dans les blocs de transformateurs pour stabiliser l'entraînement et simplifier le développement ultérieur. Cette technique normalise les scores d'attention dans les couches de transformateur, ce qui peut rendre le modèle plus robuste et plus facile à adapter à de nouveaux ensembles de données via l'apprentissage par transfert.
2.2. Diversité des sorties
Stable Diffusion 3.5 (SD3.5) vise à générer des images représentatives de la diversité mondiale sans besoin d'invites extensives. Il peut représenter des personnes avec des tons de peau, des caractéristiques et des esthétiques variées. Cela est probablement dû au fait que le modèle a été entraîné sur un ensemble de données large et diversifié d'images provenant de l'internet.
2.3. Large gamme de styles
Les modèles Stable Diffusion 3.5 (SD3.5) sont capables de générer des images dans une grande variété de styles, y compris des rendus 3D, du photoréalisme, des peintures, de l'art en ligne, de l'anime, et plus encore. Cette polyvalence les rend adaptés à de nombreux cas d'utilisation. La diversité des styles émerge de la capacité du modèle de diffusion à capturer de nombreux motifs visuels et esthétiques différents dans son espace latent.
2.4. Forte adhérence aux invites
Surtout pour le modèle Stable Diffusion 3.5 (SD3.5) Large, SD3.5 réussit bien à générer des images qui s'alignent sur le sens sémantique des invites textuelles d'entrée. Il se classe hautement par rapport à d'autres modèles sur les métriques de correspondance d'invites. Cette capacité à traduire précisément le texte en images est alimentée par les capacités de compréhension du langage du codeur textuel de transformateur.
3. Limitations et inconvénients des modèles Stable Diffusion 3.5 (SD3.5)
3.1. Difficultés avec l'anatomie et les interactions d'objets
Comme la plupart des modèles texte-image, Stable Diffusion 3.5 (SD3.5) a encore des difficultés à rendre une anatomie humaine réaliste, en particulier les mains, les pieds et les visages dans des poses complexes. Les interactions entre les objets et les mains sont souvent déformées. Cela est probablement dû au défi d'apprendre toutes les nuances des relations spatiales 3D et de la physique à partir des seules images 2D.
3.2. Résolution limitée
Le modèle Stable Diffusion 3.5 (SD3.5) Large est idéal pour les images d'un mégapixel (1024x1024), tandis que le Medium atteint un maximum d'environ 2 mégapixels. Générer des images cohérentes à des résolutions plus élevées est un défi pour SD3.5. Cette limitation découle des contraintes computationnelles et de mémoire de l'architecture de diffusion.
3.3. Bugs et hallucinations occasionnels
En raison de la capacité des modèles Stable Diffusion 3.5 (SD3.5) à permettre une grande diversité de sorties à partir de la même invite avec différentes graines aléatoires, il peut y avoir une certaine imprévisibilité. Les invites manquant de spécificité peuvent entraîner l'apparition d'éléments défectueux ou inattendus. C'est une propriété inhérente au processus d'échantillonnage de diffusion, qui implique de l'aléatoire.
3.4. Ne correspond pas aux tout derniers modèles de pointe
Selon certains premiers tests, en termes de qualité et de cohérence d'image, Stable Diffusion 3.5 (SD3.5) ne correspond pas actuellement à la performance des modèles texte-image à la pointe comme Midjourney. Et les premières comparaisons entre Stable Diffusion 3.5 (SD3.5) et FLUX.1 révèlent que chaque modèle excelle dans différents domaines. Alors que FLUX.1 semble avoir un avantage dans la production d'images photoréalistes, SD3.5 Large a une plus grande compétence pour générer des œuvres d'art de style anime sans nécessiter de réglages ou de modifications supplémentaires.
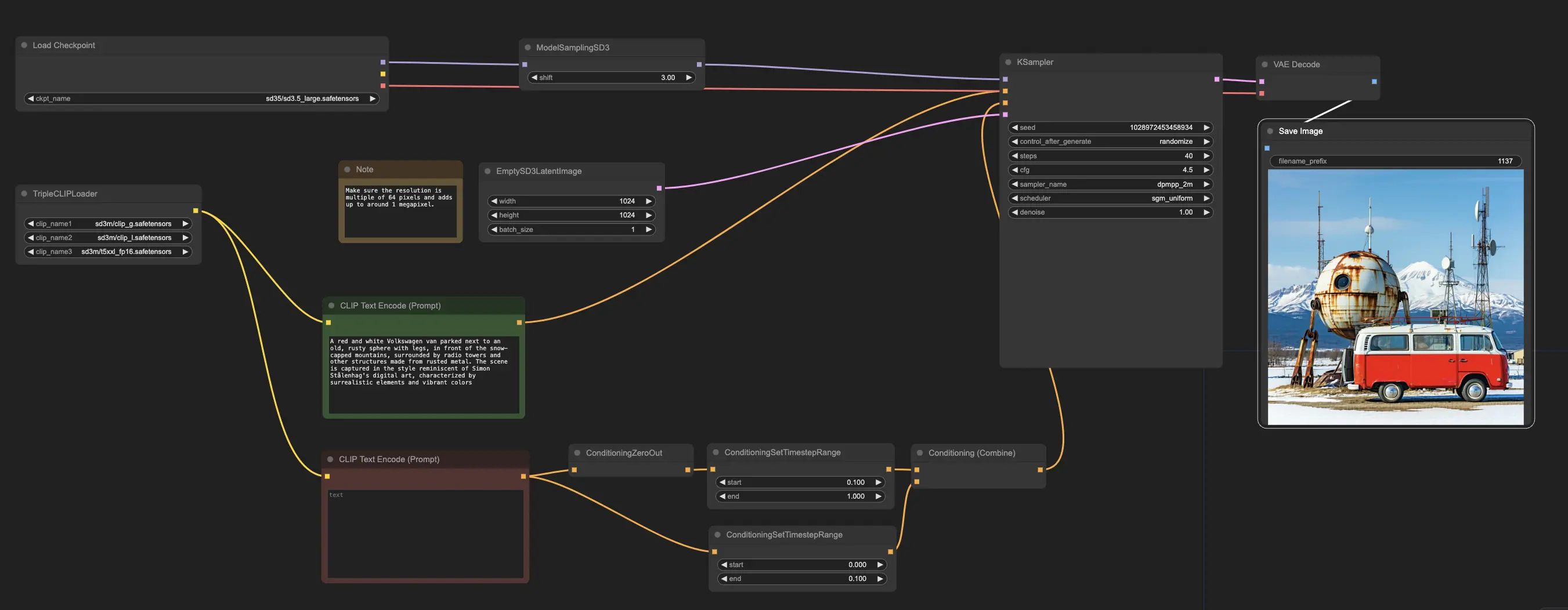
4. Stable Diffusion 3.5 dans ComfyUI
Chez RunComfy, nous avons facilité l'utilisation des modèles Stable Diffusion 3.5 (SD3.5) en les préchargeant pour votre commodité. Vous pouvez vous lancer directement et exécuter des inférences en utilisant le flux de travail d'exemple
Le flux de travail d'exemple commence avec le nœud CheckpointLoaderSimple, qui charge le modèle Stable Diffusion 3.5 Large pré-entraîné. Et pour aider à traduire vos invites textuelles dans un format que le modèle peut comprendre, le nœud TripleCLIPLoader est utilisé pour charger les codeurs correspondants. Ces codeurs sont cruciaux pour guider le processus de génération d'images basé sur le texte que vous fournissez.
Le nœud EmptySD3LatentImage crée ensuite une toile vierge avec les dimensions spécifiées, généralement 1024x1024 pixels, qui sert de point de départ pour que le modèle génère l'image. Les nœuds CLIPTextEncode traitent les invites textuelles que vous fournissez, en utilisant les codeurs chargés pour créer un ensemble d'instructions pour le modèle à suivre.
Avant que ces instructions ne soient envoyées au modèle, elles subissent un raffinement supplémentaire à travers les nœuds ConditioningCombine, ConditioningZeroOut et ConditioningSetTimestepRange. Ces nœuds éliminent l'influence de toute invite négative, spécifient quand les invites doivent être appliquées pendant le processus de génération, et combinent les instructions en un ensemble unique et cohérent.
Enfin, vous pouvez affiner le processus de génération d'images en utilisant le nœud ModelSamplingSD3, qui vous permet d'ajuster divers paramètres tels que le mode d'échantillonnage, le nombre d'étapes et l'échelle de sortie du modèle. Enfin, le nœud KSampler vous donne le contrôle sur le nombre d'étapes, la force de l'influence des instructions (échelle CFG), et l'algorithme spécifique utilisé pour la génération, vous permettant d'obtenir les résultats souhaités.

