LatentSync| Modello di Lip Sync
LatentSync ridefinisce il lip syncing con modelli di diffusione latente condizionati dall'audio, bypassando le rappresentazioni di movimento intermedie per un allineamento audio-visivo senza soluzione di continuità. Sfruttando Stable Diffusion, cattura complesse correlazioni garantendo la fluidità temporale. A differenza degli approcci basati sui pixel, LatentSync assicura una superiore coerenza temporale con il suo innovativo modulo di Allineamento della Rappresentazione Temporale (TREPA). Il modulo TREPA aiuta a fornire precisione e realismo senza pari.ComfyUI LatentSync Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI LatentSync Esempi
ComfyUI LatentSync Descrizione
LatentSync è un framework all'avanguardia end-to-end per il lip sync che sfrutta la potenza dei modelli di diffusione latente condizionati dall'audio per la generazione realistica del lip sync. Ciò che distingue LatentSync è la sua capacità di modellare direttamente le complesse correlazioni tra componenti audio e visivi senza fare affidamento su alcuna rappresentazione di movimento intermedia, rivoluzionando l'approccio alla sintesi del lip sync.
Al centro del pipeline di LatentSync c'è l'integrazione di Stable Diffusion, un potente modello generativo rinomato per la sua eccezionale capacità di catturare e generare immagini di alta qualità. Sfruttando le capacità di Stable Diffusion, LatentSync può apprendere e riprodurre efficacemente le complesse dinamiche tra l'audio del discorso e i movimenti corrispondenti delle labbra, risultando in animazioni di lip sync altamente accurate e convincenti.
Una delle sfide principali nei metodi di lip sync basati sulla diffusione è mantenere la coerenza temporale tra i fotogrammi generati, cruciale per risultati realistici. LatentSync affronta questo problema direttamente con il suo rivoluzionario modulo di Allineamento della Rappresentazione Temporale (TREPA), progettato specificamente per migliorare la coerenza temporale delle animazioni di lip sync. TREPA impiega tecniche avanzate per estrarre rappresentazioni temporali dai fotogrammi generati utilizzando modelli video auto-supervisionati su larga scala. Allineando queste rappresentazioni con i fotogrammi di verità a terra, il framework di LatentSync assicura un alto grado di coerenza temporale, risultando in animazioni di lip sync straordinariamente fluide e convincenti che corrispondono strettamente all'input audio.
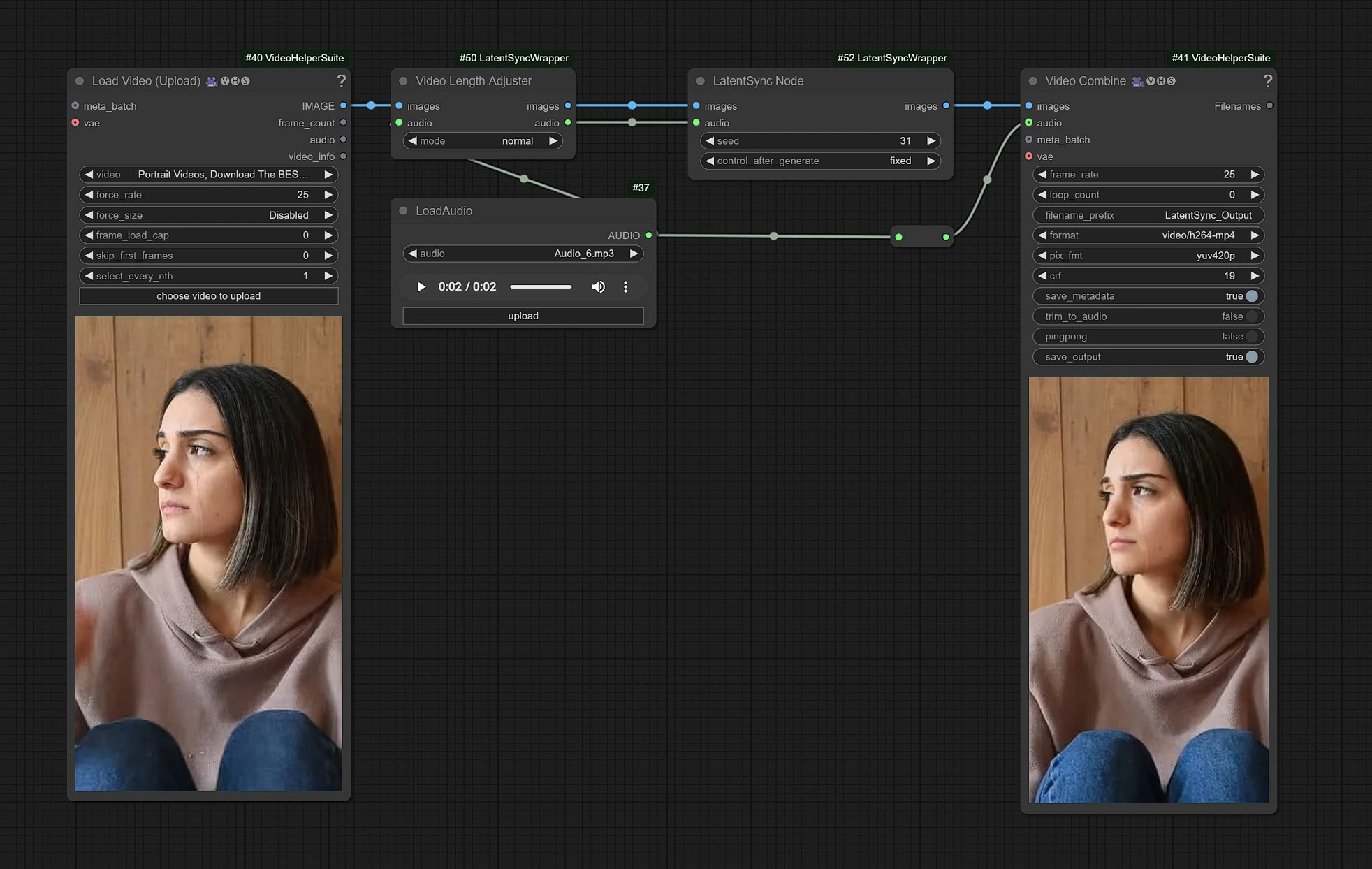
1.1 Come Usare il Workflow di LatentSync?
Questo è il workflow di LatentSync, i nodi sul lato sinistro sono gli input per caricare il video, il centro è il nodo di elaborazione di LatentSync e a destra è il nodo di output.
- Carica il tuo Video nei nodi di input.
- Carica il tuo input Audio dei dialoghi.
- Clicca su Render !!!
1.2 Input Video
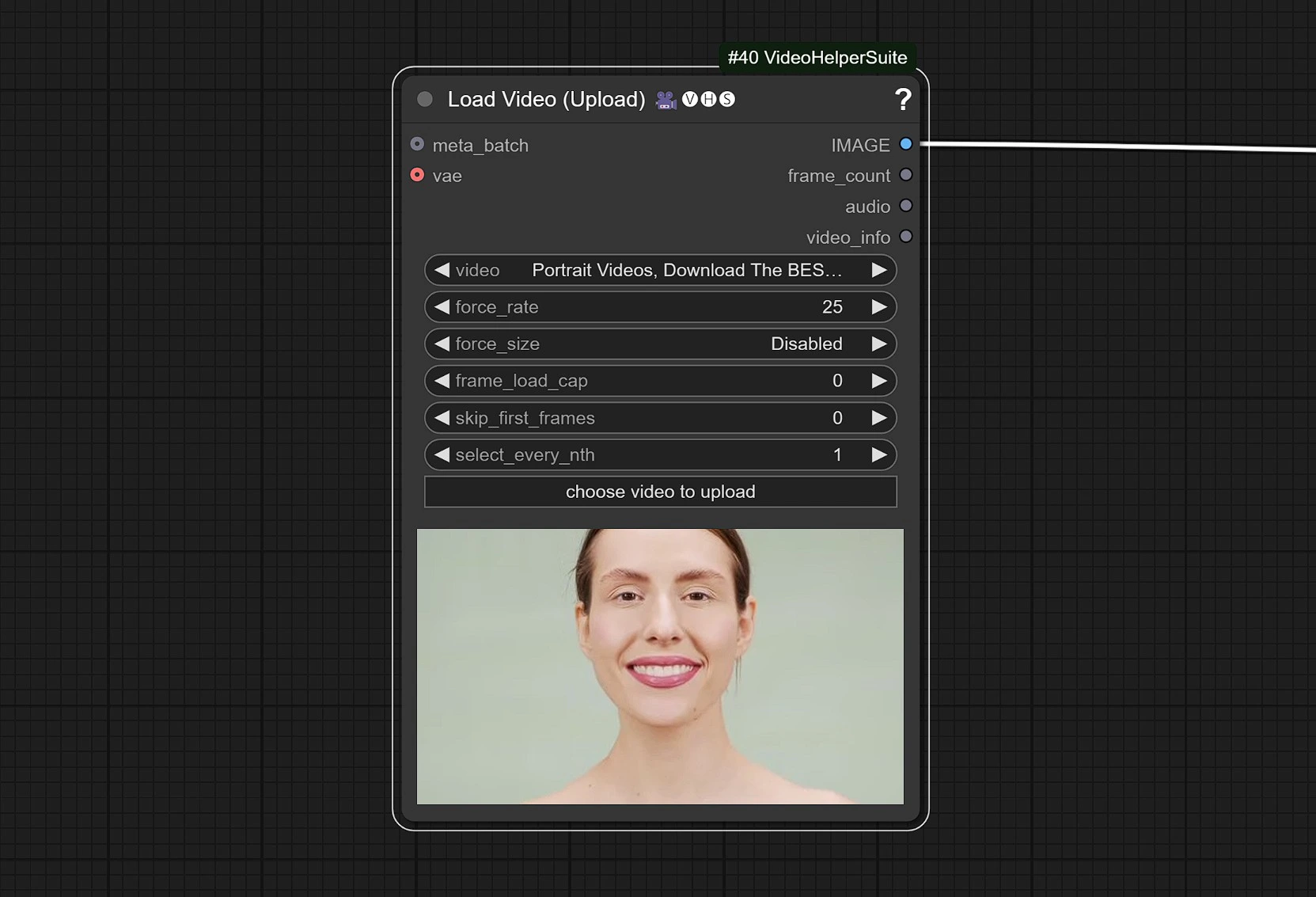
- Clicca e carica il tuo Video di Riferimento che contiene un volto.
Il video è regolato a 25 FPS per sincronizzarsi correttamente con il modello Audio
1.3 Input Audio
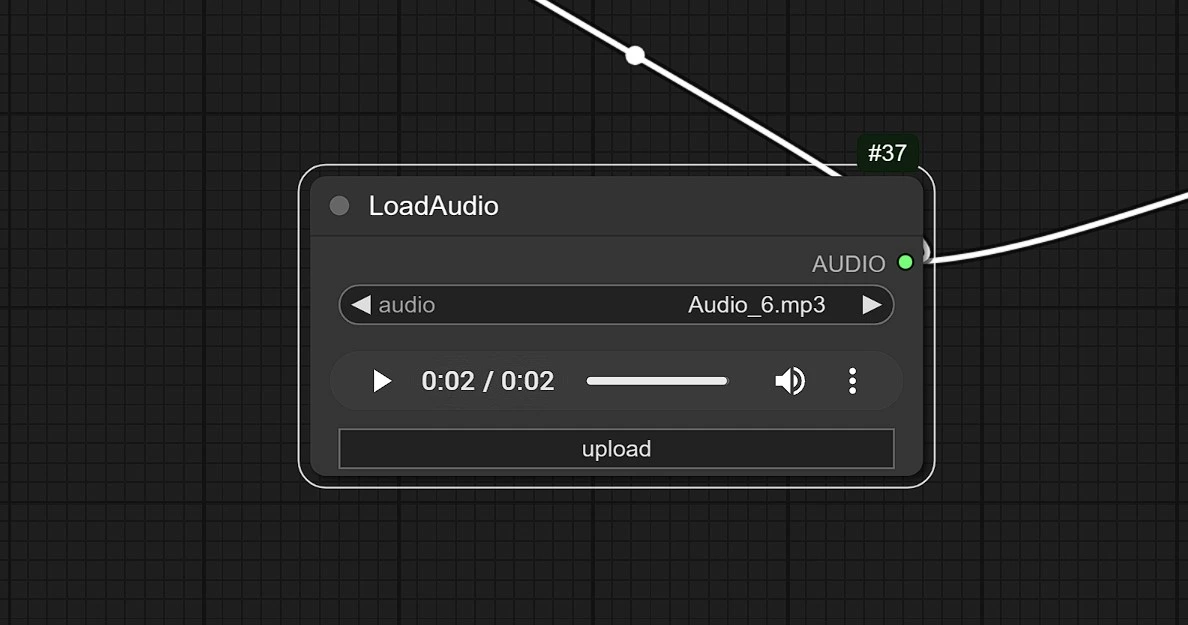
- Clicca e carica qui il tuo audio.
LatentSync stabilisce un nuovo standard per il lip sync con il suo approccio innovativo alla generazione audio-visiva. Combinando precisione, coerenza temporale e la potenza di Stable Diffusion, LatentSync trasforma il modo in cui creiamo contenuti sincronizzati. Ridefinisci ciò che è possibile nel lip sync con LatentSync.


