





ComfyUI FLUX: Guida all'Installazione, ai Flussi di Lavoro come FLUX-ControlNet, FLUX-LoRA e FLUX-IPAdapter... e all'Accesso Online
Updated: 8/26/2024
Ciao, appassionati di AI! 👋 Benvenuti nella nostra guida introduttiva all'uso di FLUX all'interno di ComfyUI. FLUX è un modello all'avanguardia sviluppato da Black Forest Labs. 🌟 In questo tutorial, esploreremo i fondamenti di ComfyUI FLUX, mostrando come questo potente modello possa migliorare il tuo processo creativo e aiutarti a spingere i confini dell'arte generata dall'AI. 🚀
Tratteremo:
1. Introduzione a FLUX
2. Diverse Versioni di FLUX
3. Requisiti Hardware di FLUX
- 3.1. Requisiti Hardware di FLUX.1 [Pro]
- 3.2. Requisiti Hardware di FLUX.1 [Dev]
- 3.3. Requisiti Hardware di FLUX.1 [Schnell]
4. Come installare FLUX in ComfyUI
- 4.1. Installazione o Aggiornamento di ComfyUI
- 4.2. Download dei Text Encoder e Modelli CLIP di ComfyUI FLUX
- 4.3. Download del Modello VAE di FLUX.1
- 4.4. Download del Modello UNET di FLUX.1
5. Flusso di Lavoro di ComfyUI FLUX | Download, Accesso Online e Guida
- 5.1. Flusso di Lavoro ComfyUI: FLUX Txt2Img
- 5.2. Flusso di Lavoro ComfyUI: FLUX Img2Img
- 5.3. Flusso di Lavoro ComfyUI: FLUX LoRA
- 5.4. Flusso di Lavoro ComfyUI: FLUX ControlNet
- 5.5. Flusso di Lavoro ComfyUI: FLUX Inpainting
- 5.6. Flusso di Lavoro ComfyUI: FLUX NF4 & Upscale
- 5.7. Flusso di Lavoro ComfyUI: FLUX IPAdapter
- 5.8. Flusso di Lavoro ComfyUI: Flux LoRA Trainer
- 5.9. Flusso di Lavoro ComfyUI: Flux Latent Upscale
1. Introduzione a FLUX
FLUX.1, il modello AI all'avanguardia di Black Forest Labs, sta rivoluzionando il modo in cui creiamo immagini da descrizioni testuali. Con la sua capacità senza pari di generare immagini straordinariamente dettagliate e complesse che corrispondono strettamente ai prompt di input, FLUX.1 si distingue dalla concorrenza. Il segreto del successo di FLUX.1 risiede nella sua architettura ibrida unica, che combina diversi tipi di blocchi transformer ed è alimentata da ben 12 miliardi di parametri. Questo permette a FLUX.1 di produrre immagini visivamente accattivanti che rappresentano accuratamente le descrizioni testuali con notevole precisione.
Uno degli aspetti più entusiasmanti di FLUX.1 è la sua versatilità nel generare immagini in vari stili, dal fotorealistico all'artistico. FLUX.1 ha persino la straordinaria capacità di incorporare senza soluzione di continuità il testo nelle immagini generate, un'impresa che molti altri modelli faticano a realizzare. Inoltre, FLUX.1 è rinomato per la sua eccezionale aderenza ai prompt, gestendo senza sforzo sia descrizioni semplici che complesse. Questo ha portato FLUX.1 a essere frequentemente paragonato ad altri modelli noti come Stable Diffusion e Midjourney, con FLUX.1 che spesso emerge come la scelta preferita grazie alla sua natura user-friendly e ai risultati di alta qualità.
Le impressionanti capacità di FLUX.1 lo rendono uno strumento inestimabile per una vasta gamma di applicazioni, dalla creazione di contenuti visivi straordinari all'ispirazione di design innovativi fino alla visualizzazione scientifica. La capacità di FLUX.1 di generare immagini altamente dettagliate e accurate da descrizioni testuali apre un mondo di possibilità per professionisti creativi, ricercatori e appassionati. Mentre il campo delle immagini generate dall'AI continua a evolversi, FLUX.1 si trova in prima linea, stabilendo un nuovo standard per qualità, versatilità e facilità d'uso.
Black Forest Labs, la pionieristica azienda AI dietro il rivoluzionario FLUX.1, è stata fondata da Robin Rombach, una figura rinomata nell'industria AI che ha precedentemente servito come membro chiave di Stability AI. Se sei curioso di sapere di più su Black Forest Labs e il loro lavoro rivoluzionario con FLUX.1, assicurati di visitare il loro sito ufficiale all'indirizzo https://blackforestlabs.ai/.

2. Diverse Versioni di FLUX
FLUX.1 è disponibile in tre diverse versioni, ciascuna progettata per soddisfare specifiche esigenze degli utenti:
- FLUX.1 [pro]: Questa è la versione di punta che offre la migliore qualità e prestazioni, perfetta per l'uso professionale e progetti di alto livello.
- FLUX.1 [dev]: Ottimizzata per l'uso non commerciale, questa versione mantiene un'alta qualità di output pur essendo più efficiente, rendendola ideale per sviluppatori e appassionati.
- FLUX.1 [schnell]: Questa versione è tutta incentrata sulla velocità e sulla leggerezza, rendendola perfetta per lo sviluppo locale e progetti personali. È anche open-source e disponibile sotto licenza Apache 2.0, quindi è accessibile a una vasta gamma di utenti.
| Nome | HuggingFace repo | Licenza | md5sum |
FLUX.1 [pro] | Disponibile solo nella nostra API. | ||
FLUX.1 [dev] | https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev Non-Commercial License | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] | https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. Requisiti Hardware di FLUX
3.1. Requisiti Hardware di FLUX.1 [Pro]
- GPU Raccomandata: NVIDIA RTX 4090 o equivalente con 24 GB o più di VRAM. Il modello è ottimizzato per GPU di fascia alta per gestire le sue operazioni complesse.
- RAM: 32 GB o più di memoria di sistema.
- Spazio su Disco: Circa 30 GB.
- Requisiti di Calcolo: È richiesta alta precisione; utilizzare FP16 (mezza precisione) per evitare errori di memoria insufficiente. Per i migliori risultati, si consiglia di utilizzare la variante del modello
fp16Clip per la massima qualità. - Altri Requisiti: Si raccomanda un SSD veloce per tempi di caricamento più rapidi e prestazioni complessive.
3.2. Requisiti Hardware di FLUX.1 [Dev]
- GPU Raccomandata: NVIDIA RTX 3080/3090 o equivalente con almeno 16 GB di VRAM. Questa versione è un po' più tollerante sull'hardware rispetto al modello Pro ma richiede comunque una potenza GPU sostanziale.
- RAM: 16 GB o più di memoria di sistema.
- Spazio su Disco: Circa 25 GB.
- Requisiti di Calcolo: Simile al Pro, utilizzare modelli FP16, ma con una leggera tolleranza per calcoli a precisione inferiore. Può utilizzare modelli Clip
fp16ofp8in base alle capacità della GPU. - Altri Requisiti: Si raccomanda un SSD veloce per prestazioni ottimali.
3.3. Requisiti Hardware di FLUX.1 [Schnell]
- GPU Raccomandata: NVIDIA RTX 3060/4060 o equivalente con 12 GB di VRAM. Questa versione è ottimizzata per inferenze più veloci e richieste hardware inferiori.
- RAM: 8 GB o più di memoria di sistema.
- Spazio su Disco: Circa 15 GB.
- Requisiti di Calcolo: Questa versione è meno esigente e consente calcoli
fp8se si esaurisce la memoria. È progettata per essere veloce ed efficiente, con un focus sulla velocità piuttosto che sulla qualità ultra elevata. - Altri Requisiti: L'SSD è utile ma non così critico come nelle versioni Pro e Dev.
4. Come installare FLUX in ComfyUI
4.1. Installazione o Aggiornamento di ComfyUI
Per utilizzare efficacemente FLUX.1 all'interno dell'ambiente ComfyUI, è fondamentale assicurarsi di avere installata l'ultima versione di ComfyUI. Questa versione supporta le funzionalità e le integrazioni necessarie per i modelli FLUX.1.
4.2. Download dei Text Encoder e Modelli CLIP di ComfyUI FLUX
Per prestazioni ottimali e una generazione precisa di immagini da testo con FLUX.1, sarà necessario scaricare specifici text encoder e modelli CLIP. I seguenti modelli sono essenziali, a seconda dell'hardware del tuo sistema:
| Nome del File del Modello | Dimensione | Nota | Link |
t5xxl_fp16.safetensors | 9.79 GB | Per risultati migliori, se hai alta VRAM e RAM (più di 32GB RAM). | Download |
t5xxl_fp8_e4m3fn.safetensors | 4.89 GB | Per un uso di memoria inferiore (8-12GB) | Download |
clip_l.safetensors | 246 MB | Download |
Passaggi per Scaricare e Installare:
- Scarica il modello
clip_l.safetensors. - A seconda della VRAM e della RAM del tuo sistema, scarica
t5xxl_fp8_e4m3fn.safetensors(per VRAM inferiore) ot5xxl_fp16.safetensors(per VRAM e RAM superiori). - Posiziona i modelli scaricati nella directory
ComfyUI/models/clip/. Nota: Se hai già utilizzato SD 3 Medium, potresti già avere questi modelli.
4.3. Download del Modello VAE di FLUX.1
Il modello Variational Autoencoder (VAE) è cruciale per migliorare la qualità della generazione di immagini in FLUX.1. Il seguente modello VAE è disponibile per il download:
| Nome del File | Dimensione | Link |
ae.safetensors | 335 MB | Download(opens in a new tab) |
Passaggi per Scaricare e Installare:
- Scarica il file del modello
ae.safetensors. - Posiziona il file scaricato nella directory
ComfyUI/models/vae. - Per una facile identificazione, si consiglia di rinominare il file in
flux_ae.safetensors.
4.4. Download del Modello UNET di FLUX.1
Il modello UNET è la spina dorsale per la sintesi delle immagini in FLUX.1. A seconda delle specifiche del tuo sistema, puoi scegliere tra diverse varianti:
| Nome del File | Dimensione | Link | Nota |
flux1-dev.safetensors | 23.8GB | Download | Se hai alta VRAM e RAM. |
flux1-schnell.safetensors | 23.8GB | Download | Per un uso di memoria inferiore |
Passaggi per Scaricare e Installare:
- Scarica il modello UNET appropriato in base alla configurazione della memoria del tuo sistema.
- Posiziona il file del modello scaricato nella directory
ComfyUI/models/unet/.
5. Flusso di Lavoro di ComfyUI FLUX | Download, Accesso Online e Guida
Aggiorneremo continuamente il Flusso di Lavoro di ComfyUI FLUX per fornirti i flussi di lavoro più recenti e completi per generare immagini straordinarie utilizzando ComfyUI FLUX.
5.1. Flusso di Lavoro ComfyUI: FLUX Txt2Img
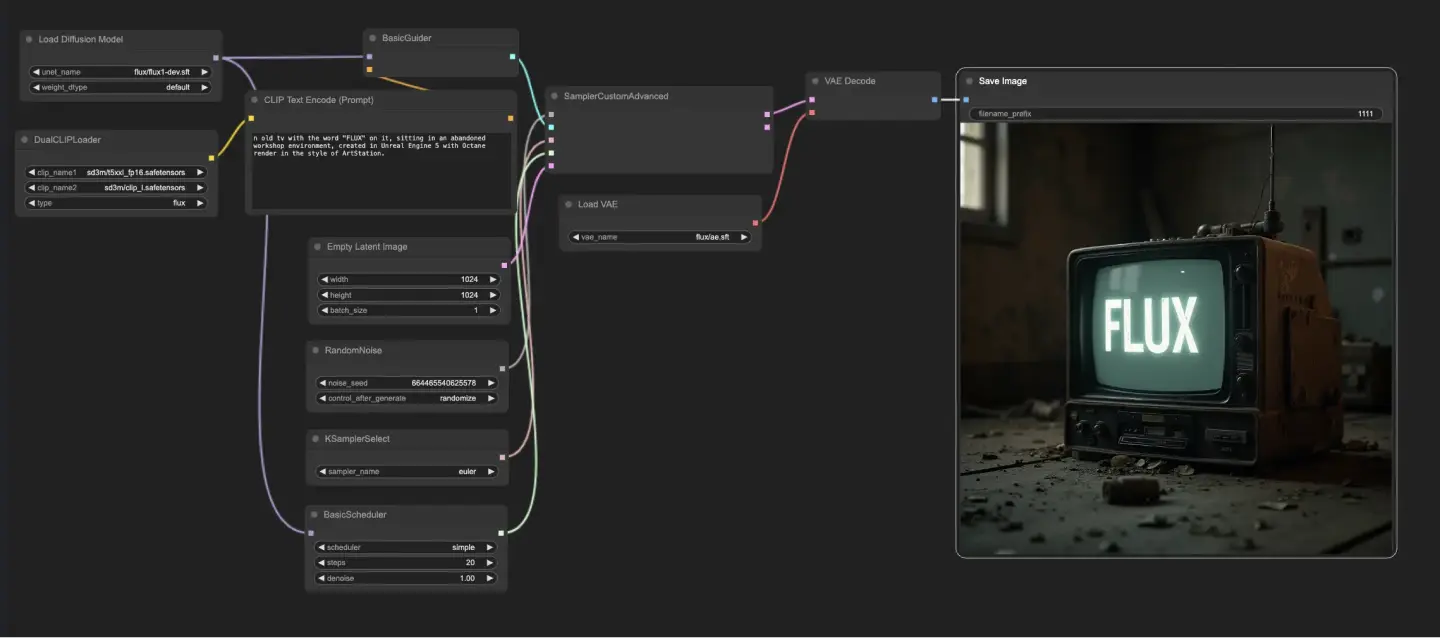
5.1.1. ComfyUI FLUX Txt2Img : Download
5.1.2. ComfyUI FLUX Txt2Img Versione Online: ComfyUI FLUX Txt2Img
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX Txt2Img.
5.1.3. Spiegazione di ComfyUI FLUX Txt2Img:
Il flusso di lavoro ComfyUI FLUX Txt2Img inizia caricando i componenti essenziali, inclusi FLUX UNET (UNETLoader), FLUX CLIP (DualCLIPLoader) e FLUX VAE (VAELoader). Questi formano la base del processo di generazione di immagini di ComfyUI FLUX.
- UNETLoader: Carica il modello UNET per la generazione di immagini.
- Checkpoint: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: Carica il modello CLIP per la codifica del testo.
- Modello di Embedding 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Modello di Embedding 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Raggruppamento: La strategia di raggruppamento per il modello CLIP è flux
- VAELoader: Carica il modello Variational Autoencoder (VAE) per decodificare le rappresentazioni latenti.
- Modello VAE: flux/ae.sft
Il prompt di testo, che descrive l'output desiderato, viene codificato utilizzando CLIPTextEncode. Questo nodo prende il prompt di testo come input e genera la codifica del testo condizionante, che guida ComfyUI FLUX durante la generazione.
Per avviare il processo di generazione di ComfyUI FLUX, viene creata una rappresentazione latente vuota utilizzando EmptyLatentImage. Questo serve come punto di partenza su cui ComfyUI FLUX può costruire.
Il BasicGuider svolge un ruolo cruciale nel guidare il processo di generazione di ComfyUI FLUX. Prende la codifica del testo condizionante e il FLUX UNET caricato come input, assicurando che l'output generato sia in linea con la descrizione testuale fornita.
Il KSamplerSelect ti consente di scegliere il metodo di campionamento per la generazione di ComfyUI FLUX, mentre il RandomNoise genera rumore casuale come input per ComfyUI FLUX. Il BasicScheduler programma i livelli di rumore (sigma) per ogni passaggio del processo di generazione, controllando il livello di dettaglio e la chiarezza nell'output finale.
Il SamplerCustomAdvanced riunisce tutti i componenti del flusso di lavoro ComfyUI FLUX Txt2Img. Prende il rumore casuale, il guida, il campionatore selezionato, i sigma programmati e la rappresentazione latente vuota come input. Attraverso un processo di campionamento avanzato, genera una rappresentazione latente che rappresenta il prompt di testo.
Infine, il VAEDecode decodifica la rappresentazione latente generata nell'output finale utilizzando il FLUX VAE caricato. Il SaveImage ti permette di salvare l'output generato in una posizione specificata, preservando la straordinaria creazione resa possibile dal flusso di lavoro ComfyUI FLUX Txt2Img.
5.2. Flusso di Lavoro ComfyUI: FLUX Img2Img
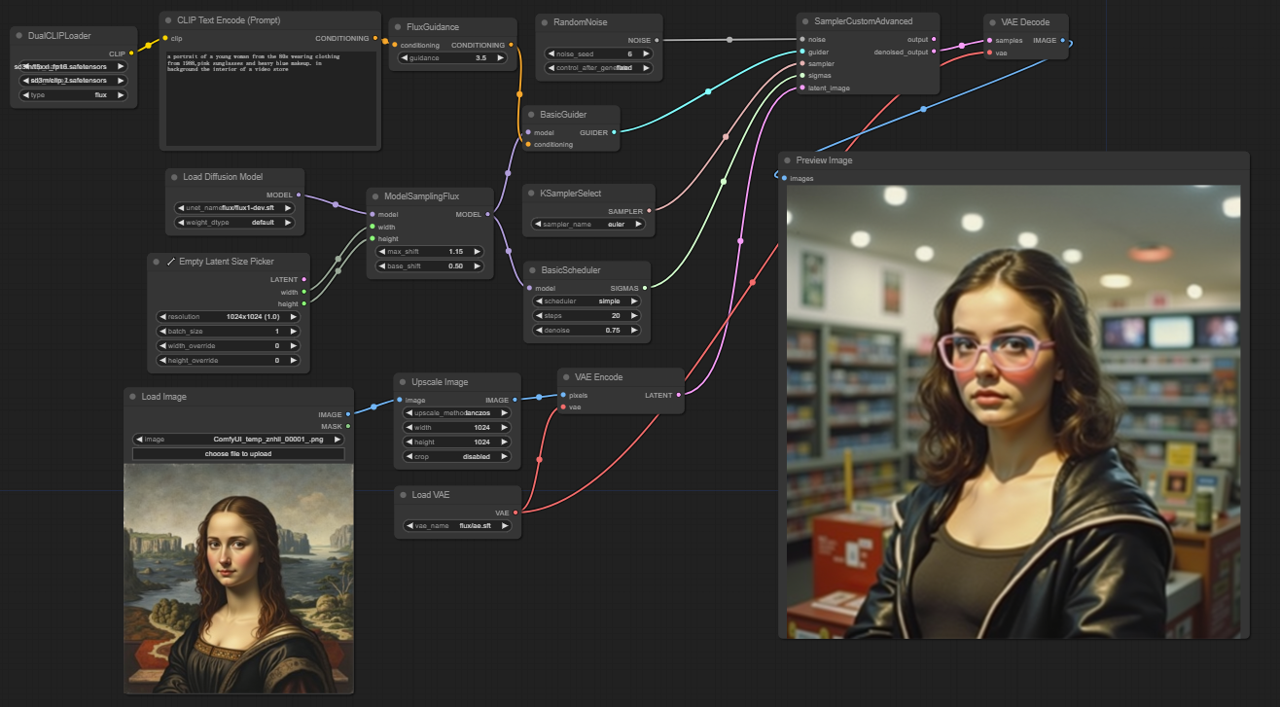
5.2.1. ComfyUI FLUX Img2Img: Download
5.2.2. ComfyUI FLUX Img2Img Versione Online: ComfyUI FLUX Img2Img
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX Img2Img.
5.2.3. Spiegazione di ComfyUI FLUX Img2Img:
Il flusso di lavoro ComfyUI FLUX Img2Img si basa sulla potenza di ComfyUI FLUX per generare output basati sia su prompt di testo che su rappresentazioni di input. Inizia caricando i componenti necessari, inclusi il modello CLIP (DualCLIPLoader), il modello UNET (UNETLoader) e il modello VAE (VAELoader).
- UNETLoader: Carica il modello UNET per la generazione di immagini.
- Checkpoint: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: Carica il modello CLIP per la codifica del testo.
- Modello di Embedding 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Modello di Embedding 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Raggruppamento: La strategia di raggruppamento per il modello CLIP è flux
- VAELoader: Carica il modello Variational Autoencoder (VAE) per decodificare le rappresentazioni latenti.
- Modello VAE: flux/ae.sft
La rappresentazione di input, che serve come punto di partenza per il processo ComfyUI FLUX Img2Img, viene caricata utilizzando LoadImage. L'ImageScale quindi scala la rappresentazione di input alla dimensione desiderata, garantendo la compatibilità con ComfyUI FLUX.
La rappresentazione di input scalata viene codificata utilizzando VAEEncode, convertendola in una rappresentazione latente. Questa rappresentazione latente cattura le caratteristiche e i dettagli essenziali dell'input, fornendo una base su cui ComfyUI FLUX può lavorare.
Il prompt di testo, che descrive le modifiche o i miglioramenti desiderati per l'input, viene codificato utilizzando CLIPTextEncode. Il FluxGuidance applica quindi una guida alla codifica condizionante in base alla scala di guida specificata, influenzando la forza dell'influenza del prompt di testo sull'output finale.
Il ModelSamplingFlux imposta i parametri di campionamento per ComfyUI FLUX, inclusi il respacing dei timestep, il rapporto di padding e le dimensioni dell'output. Questi parametri controllano la granularità e la risoluzione dell'output generato.
Il KSamplerSelect ti consente di scegliere il metodo di campionamento per la generazione di ComfyUI FLUX, mentre il BasicGuider guida il processo di generazione basato sulla codifica del testo condizionante e il FLUX UNET caricato.
Il rumore casuale viene generato utilizzando RandomNoise, e il BasicScheduler programma i livelli di rumore (sigma) per ogni passaggio del processo di generazione. Questi componenti introducono variazioni controllate e affinano i dettagli nell'output finale.
Il SamplerCustomAdvanced riunisce il rumore casuale, il guida, il campionatore selezionato, i sigma programmati e la rappresentazione latente dell'input. Attraverso un processo di campionamento avanzato, genera una rappresentazione latente che incorpora le modifiche specificate dal prompt di testo preservando le caratteristiche essenziali dell'input.
Infine, il VAEDecode decodifica la rappresentazione latente denoised nell'output finale utilizzando il FLUX VAE caricato. Il PreviewImage visualizza un'anteprima dell'output generato, mostrando i risultati straordinari ottenuti dal flusso di lavoro ComfyUI FLUX Img2Img.
5.3. Flusso di Lavoro ComfyUI: FLUX LoRA
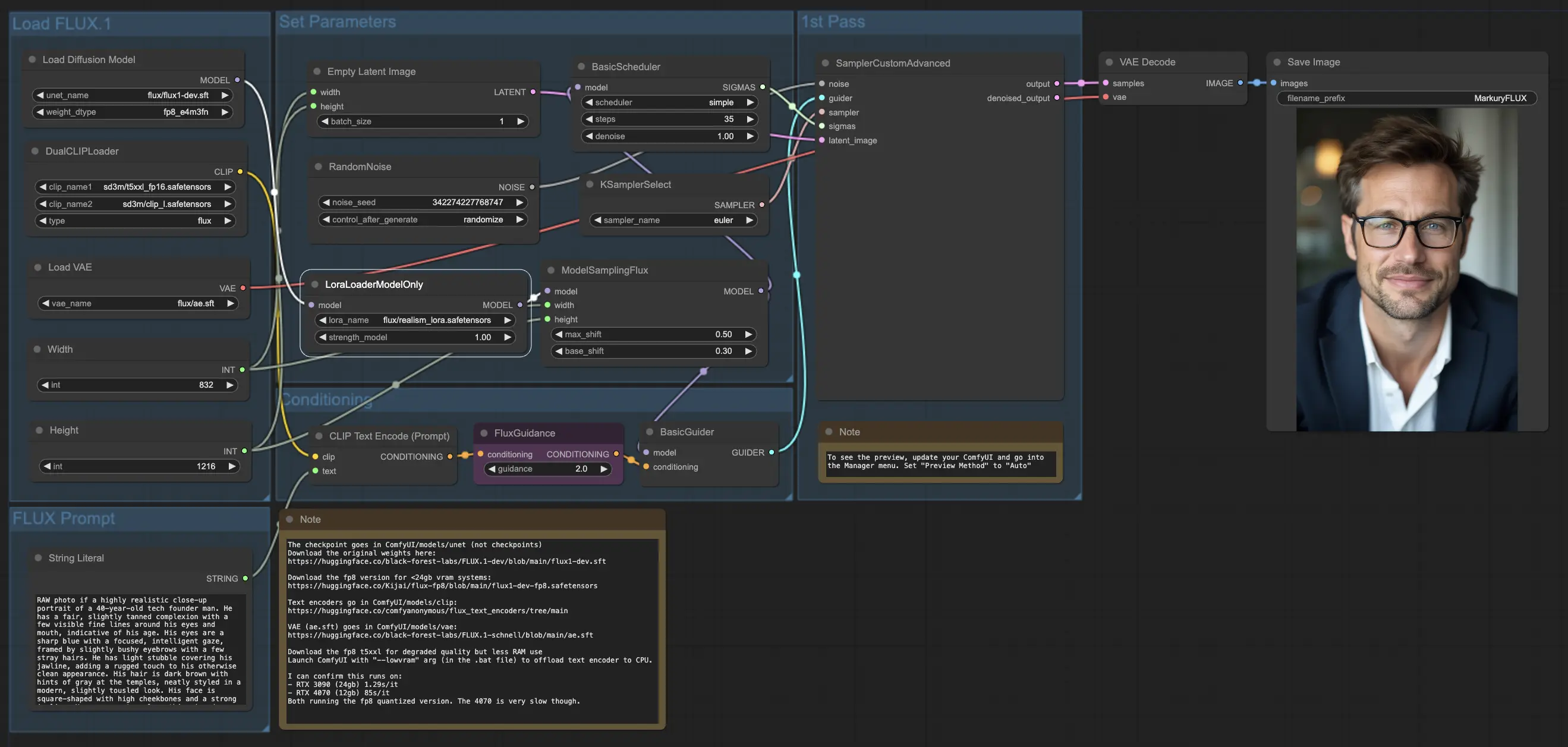
5.3.1. ComfyUI FLUX LoRA: Download
5.3.2. ComfyUI FLUX LoRA Versione Online: ComfyUI FLUX LoRA
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX LoRA.
5.3.3. Spiegazione di ComfyUI FLUX LoRA:
Il flusso di lavoro ComfyUI FLUX LoRA sfrutta la potenza dell'Adattamento a Basso Rango (LoRA) per migliorare le prestazioni di ComfyUI FLUX. Inizia caricando i componenti necessari, inclusi il modello UNET (UNETLoader), il modello CLIP (DualCLIPLoader), il modello VAE (VAELoader) e il modello LoRA (LoraLoaderModelOnly).
- UNETLoader: Carica il modello UNET per la generazione di immagini.
- Checkpoint: flux/flux1-dev.sft
- DualCLIPLoader: Carica il modello CLIP per la codifica del testo.
- Modello di Embedding 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Modello di Embedding 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Raggruppamento: La strategia di raggruppamento per il modello CLIP è flux
- VAELoader: Carica il modello Variational Autoencoder (VAE) per decodificare le rappresentazioni latenti.
- Modello VAE: flux/ae.sft
- LoraLoaderModelOnly: Carica il modello LoRA (Adattamento a Basso Rango) per migliorare il modello UNET.
- LoaderModel: flux/realism_lora.safetensors
Il prompt di testo, che descrive l'output desiderato, viene specificato utilizzando String Literal. Il CLIPTextEncode quindi codifica il prompt di testo, generando la codifica del testo condizionante che guida il processo di generazione di ComfyUI FLUX.
Il FluxGuidance applica una guida alla codifica del testo condizionante, influenzando la forza e la direzione dell'aderenza di ComfyUI FLUX al prompt di testo.
Una rappresentazione latente vuota, che serve come punto di partenza per la generazione, viene creata utilizzando EmptyLatentImage. La larghezza e l'altezza dell'output generato vengono specificate utilizzando Int Literal, garantendo le dimensioni desiderate del risultato finale.
Il ModelSamplingFlux imposta i parametri di campionamento per ComfyUI FLUX, inclusi il rapporto di padding e il respacing dei timestep. Questi parametri controllano la risoluzione e la granularità dell'output generato.
Il KSamplerSelect ti consente di scegliere il metodo di campionamento per la generazione di ComfyUI FLUX, mentre il BasicGuider guida il processo di generazione basato sulla codifica del testo condizionante e il FLUX UNET caricato migliorato con FLUX LoRA.
Il rumore casuale viene generato utilizzando RandomNoise, e il BasicScheduler programma i livelli di rumore (sigma) per ogni passaggio del processo di generazione. Questi componenti introducono variazioni controllate e affinano i dettagli nell'output finale.
Il SamplerCustomAdvanced riunisce il rumore casuale, il guida, il campionatore selezionato, i sigma programmati e la rappresentazione latente vuota. Attraverso un processo di campionamento avanzato, genera una rappresentazione latente che rappresenta il prompt di testo, sfruttando la potenza di FLUX e il miglioramento FLUX LoRA.
Infine, il VAEDecode decodifica la rappresentazione latente generata nell'output finale utilizzando il FLUX VAE caricato. Il SaveImage ti permette di salvare l'output generato in una posizione specificata, preservando la straordinaria creazione resa possibile dal flusso di lavoro ComfyUI FLUX LoRA.
5.4. Flusso di Lavoro ComfyUI: FLUX ControlNet
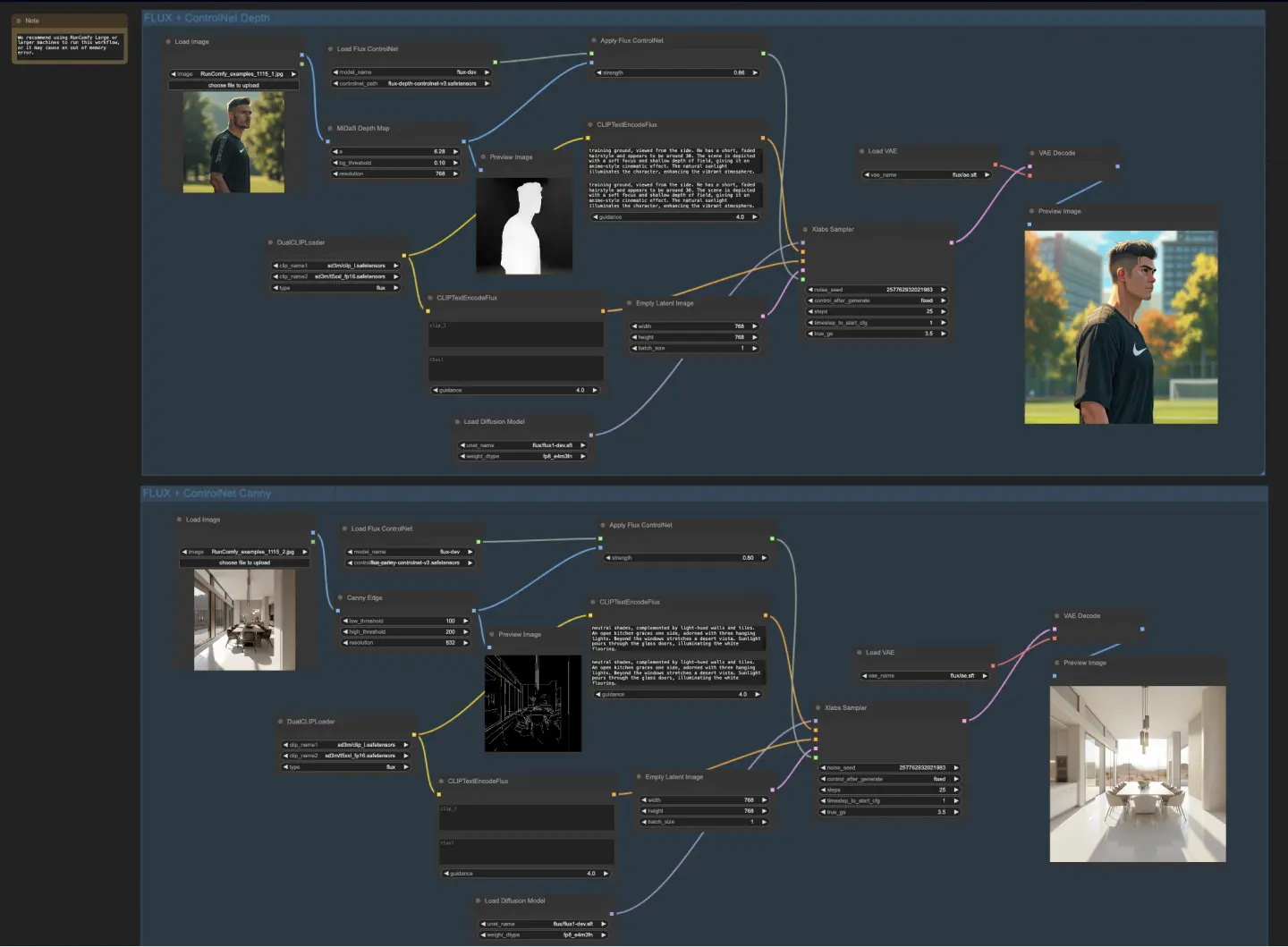
5.4.1. ComfyUI FLUX ControlNet: Download
5.4.2. ComfyUI FLUX ControlNet Versione Online: ComfyUI FLUX ControlNet
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX ControlNet.
5.4.3. Spiegazione di ComfyUI FLUX ControlNet:
Il flusso di lavoro ComfyUI FLUX ControlNet dimostra l'integrazione di ControlNet con ComfyUI FLUX per migliorare la generazione dell'output. Il flusso di lavoro mostra due esempi: condizionamento basato sulla profondità e condizionamento basato sui bordi Canny.
- UNETLoader: Carica il modello UNET per la generazione di immagini.
- Checkpoint: flux/flux1-dev.sft
- DualCLIPLoader: Carica il modello CLIP per la codifica del testo.
- Modello di Embedding 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Modello di Embedding 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Raggruppamento: La strategia di raggruppamento per il modello CLIP è flux
- VAELoader: Carica il modello Variational Autoencoder (VAE) per decodificare le rappresentazioni latenti.
- Modello VAE: flux/ae.sft
Nel flusso di lavoro basato sulla profondità, la rappresentazione di input viene pre-processata utilizzando MiDaS-DepthMapPreprocessor, generando una mappa di profondità. La mappa di profondità viene quindi passata attraverso ApplyFluxControlNet (Depth) insieme al FLUX ControlNet caricato per il condizionamento della profondità. La condizione FLUX ControlNet risultante serve come input per XlabsSampler (Depth), insieme al FLUX UNET caricato, la codifica del testo condizionante, la codifica del testo negativo e la rappresentazione latente vuota. XlabsSampler genera una rappresentazione latente basata su questi input, che viene successivamente decodificata nell'output finale utilizzando VAEDecode.
- MiDaS-DepthMapPreprocessor (Depth): Pre-processa l'immagine di input per la stima della profondità utilizzando MiDaS.
- LoadFluxControlNet: Carica il modello ControlNet.
- Path: flux-depth-controlnet.safetensors
Allo stesso modo, nel flusso di lavoro basato sui bordi Canny, la rappresentazione di input viene pre-processata utilizzando CannyEdgePreprocessor per generare i bordi Canny. La rappresentazione dei bordi Canny viene passata attraverso ApplyFluxControlNet (Canny) insieme al FLUX ControlNet caricato per il condizionamento dei bordi Canny. La condizione FLUX ControlNet risultante serve come input per XlabsSampler (Canny), insieme al FLUX UNET caricato, la codifica del testo condizionante, la codifica del testo negativo e la rappresentazione latente vuota. XlabsSampler genera una rappresentazione latente basata su questi input, che viene poi decodificata nell'output finale utilizzando VAEDecode.
- CannyEdgePreprocessor (Canny): Pre-processa l'immagine di input per la rilevazione dei bordi Canny.
- LoadFluxControlNet: Carica il modello ControlNet.
- Path: flux-canny-controlnet.safetensors
Il flusso di lavoro ComfyUI FLUX ControlNet incorpora nodi per caricare i componenti necessari (DualCLIPLoader, UNETLoader, VAELoader, LoadFluxControlNet), codificare i prompt di testo (CLIPTextEncodeFlux), creare rappresentazioni latenti vuote (EmptyLatentImage) e visualizzare in anteprima gli output generati e pre-processati (PreviewImage).
Sfruttando la potenza di FLUX ControlNet, il flusso di lavoro ComfyUI FLUX ControlNet consente la generazione di output che sono in linea con specifici condizionamenti, come le mappe di profondità o i bordi Canny. Questo livello aggiuntivo di controllo e guida migliora la flessibilità e la precisione del processo di generazione, permettendo la creazione di output straordinari e contestualmente rilevanti utilizzando ComfyUI FLUX.
5.5. Flusso di Lavoro ComfyUI: FLUX Inpainting
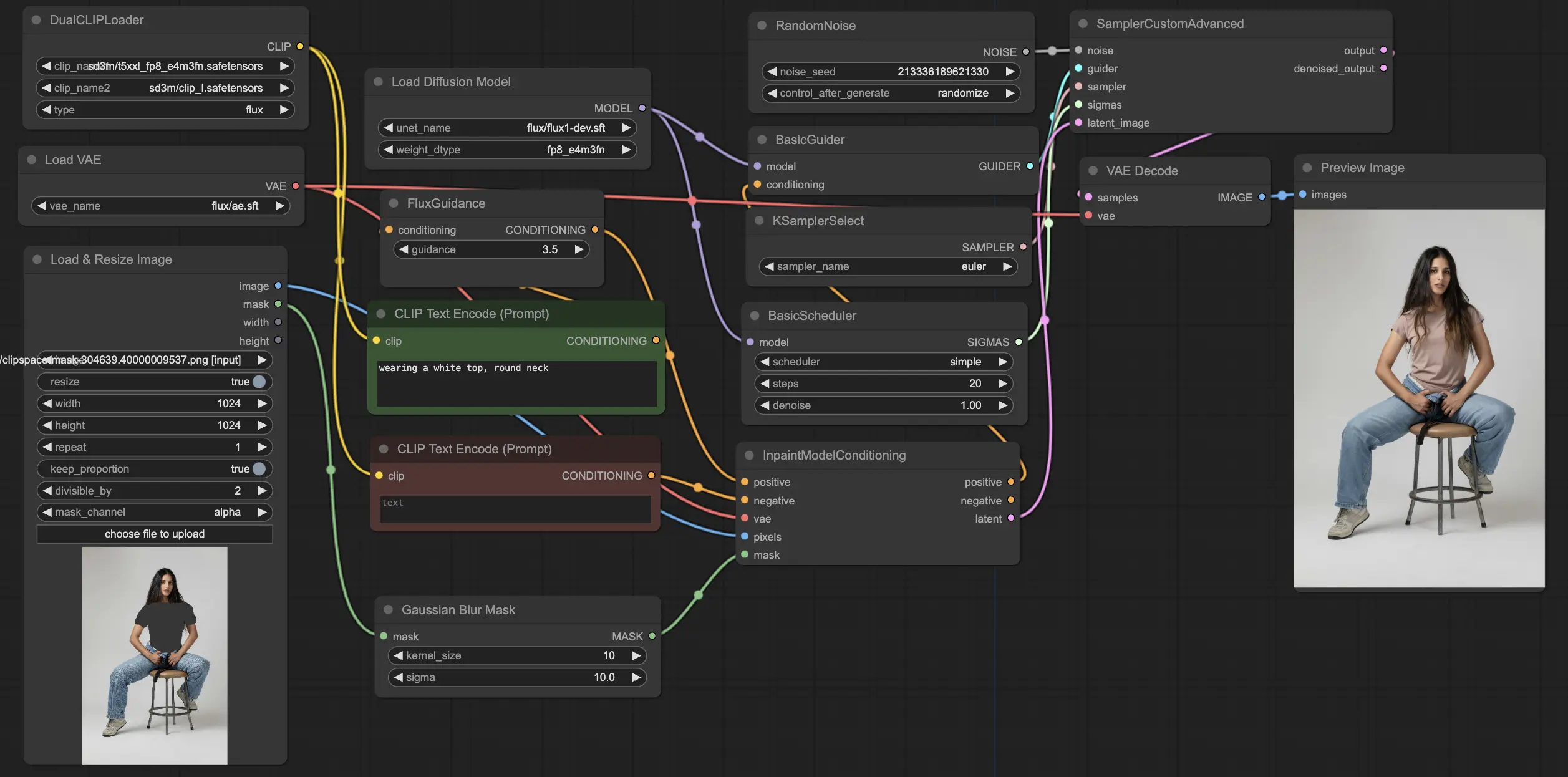
5.5.1. ComfyUI FLUX Inpainting: Download
5.5.2. ComfyUI FLUX Inpainting Versione Online: ComfyUI FLUX Inpainting
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX Inpainting.
5.5.3. Spiegazione di ComfyUI FLUX Inpainting:
Il flusso di lavoro ComfyUI FLUX Inpainting dimostra la capacità di ComfyUI FLUX di eseguire l'inpainting, che comporta il riempimento di regioni mancanti o mascherate di un output basato sul contesto circostante e sui prompt di testo forniti. Il flusso di lavoro inizia caricando i componenti necessari, inclusi il modello UNET (UNETLoader), il modello VAE (VAELoader) e il modello CLIP (DualCLIPLoader).
- UNETLoader: Carica il modello UNET per la generazione di immagini.
- Checkpoint: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: Carica il modello CLIP per la codifica del testo.
- Modello di Embedding 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Modello di Embedding 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Raggruppamento: La strategia di raggruppamento per il modello CLIP è flux
- VAELoader: Carica il modello Variational Autoencoder (VAE) per decodificare le rappresentazioni latenti.
- Modello VAE: flux/ae.sft
I prompt di testo positivi e negativi, che descrivono il contenuto e lo stile desiderati per la regione inpaintata, vengono codificati utilizzando CLIPTextEncodes. Il condizionamento del testo positivo viene ulteriormente guidato utilizzando FluxGuidance per influenzare il processo di inpainting di ComfyUI FLUX.
La rappresentazione di input e la maschera vengono caricate e ridimensionate utilizzando LoadAndResizeImage, garantendo la compatibilità con i requisiti di ComfyUI FLUX. L'ImpactGaussianBlurMask applica il blur gaussiano alla maschera, creando una transizione più fluida tra la regione inpaintata e la rappresentazione originale.
L'InpaintModelConditioning prepara il condizionamento per l'inpainting di FLUX combinando il condizionamento del testo positivo guidato, la codifica del testo negativo, il FLUX VAE caricato, la rappresentazione di input caricata e ridimensionata, e la maschera sfocata. Questo condizionamento serve come base per il processo di inpainting di ComfyUI FLUX.
Il rumore casuale viene generato utilizzando RandomNoise, e il metodo di campionamento viene selezionato utilizzando KSamplerSelect. Il BasicScheduler programma i livelli di rumore (sigma) per il processo di inpainting di ComfyUI FLUX, controllando il livello di dettaglio e la chiarezza nella regione inpaintata.
Il BasicGuider guida il processo di inpainting di ComfyUI FLUX basato sul condizionamento preparato e il FLUX UNET caricato. Il SamplerCustomAdvanced esegue il processo di campionamento avanzato, prendendo il rumore casuale generato, il guida, il campionatore selezionato, i sigma programmati e la rappresentazione latente dell'input come input. Il risultato è la rappresentazione latente inpaintata.
Infine, il VAEDecode decodifica la rappresentazione latente inpaintata nell'output finale, fondendo senza soluzione di continuità la regione inpaintata con la rappresentazione originale. Il PreviewImage visualizza l'output finale, mostrando le impressionanti capacità di inpainting di FLUX.
Sfruttando la potenza di FLUX e il flusso di lavoro di inpainting accuratamente progettato, FLUX Inpainting consente la creazione di output inpaintati visivamente coerenti e contestualmente rilevanti. Che si tratti di ripristinare parti mancanti, rimuovere oggetti indesiderati o modificare regioni specifiche, il flusso di lavoro di inpainting di ComfyUI FLUX fornisce uno strumento potente per l'editing e la manipolazione.
5.6. Flusso di Lavoro ComfyUI: FLUX NF4
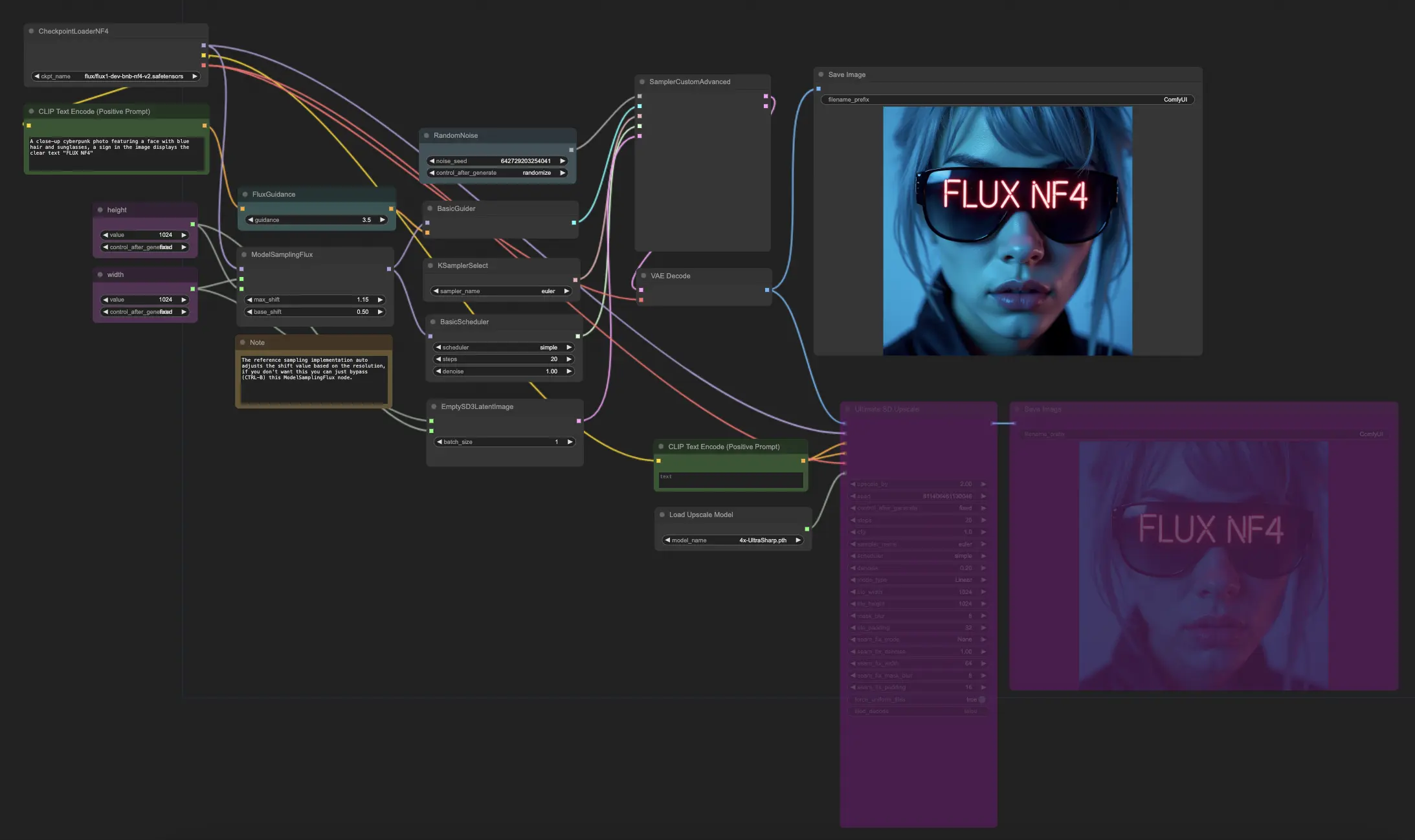
5.6.1. ComfyUI FLUX NF4: Download
5.6.2. ComfyUI FLUX NF4 Versione Online: ComfyUI FLUX NF4
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX NF4.
5.6.3. Spiegazione di ComfyUI FLUX NF4:
Il flusso di lavoro ComfyUI FLUX NF4 mostra l'integrazione di ComfyUI FLUX con l'architettura NF4 (Normalizing Flow 4) per la generazione di output di alta qualità. Il flusso di lavoro inizia caricando i componenti necessari utilizzando CheckpointLoaderNF4, che include FLUX UNET, FLUX CLIP e FLUX VAE.
- UNETLoader: Carica il modello UNET per la generazione di immagini.
- Checkpoint: TBD
I nodi PrimitiveNode (height) e PrimitiveNode (width) specificano l'altezza e la larghezza desiderate dell'output generato. Il nodo ModelSamplingFlux imposta i parametri di campionamento per ComfyUI FLUX basati sul FLUX UNET caricato e l'altezza e larghezza specificate.
Il nodo EmptySD3LatentImage crea una rappresentazione latente vuota come punto di partenza per la generazione. Il nodo BasicScheduler programma i livelli di rumore (sigma) per il processo di generazione di ComfyUI FLUX.
Il nodo RandomNoise genera rumore casuale per il processo di generazione di ComfyUI FLUX. Il nodo BasicGuider guida il processo di generazione basato sul FLUX condizionato di ComfyUI.
Il nodo KSamplerSelect seleziona il metodo di campionamento per la generazione di ComfyUI FLUX. Il nodo SamplerCustomAdvanced esegue il processo di campionamento avanzato, prendendo il rumore casuale generato, il guida, il campionatore selezionato, i sigma programmati e la rappresentazione latente vuota come input. Il risultato è la rappresentazione latente generata.
Il nodo VAEDecode decodifica la rappresentazione latente generata nell'output finale utilizzando il FLUX VAE caricato. Il nodo SaveImage salva l'output generato in una posizione specificata.
Per l'upscaling, viene utilizzato il nodo UltimateSDUpscale. Prende l'output generato, il FLUX caricato, il condizionamento positivo e negativo per l'upscaling, il FLUX VAE caricato e il FLUX upscaling caricato come input. Il nodo CLIPTextEncode (Upscale Positive Prompt) codifica il prompt di testo positivo per l'upscaling. Il nodo UpscaleModelLoader carica il FLUX upscaling. Il nodo UltimateSDUpscale esegue il processo di upscaling e genera la rappresentazione upscalata. Infine, il nodo SaveImage (Upscaled) salva l'output upscalato in una posizione specificata.
Sfruttando la potenza di ComfyUI FLUX e dell'architettura NF4, il flusso di lavoro ComfyUI FLUX NF4 consente la generazione di output di alta qualità con fedeltà e realismo migliorati. L'integrazione senza soluzione di continuità di ComfyUI FLUX con l'architettura NF4 fornisce uno strumento potente per creare output straordinari e accattivanti.
5.7. Flusso di Lavoro ComfyUI: FLUX IPAdapter
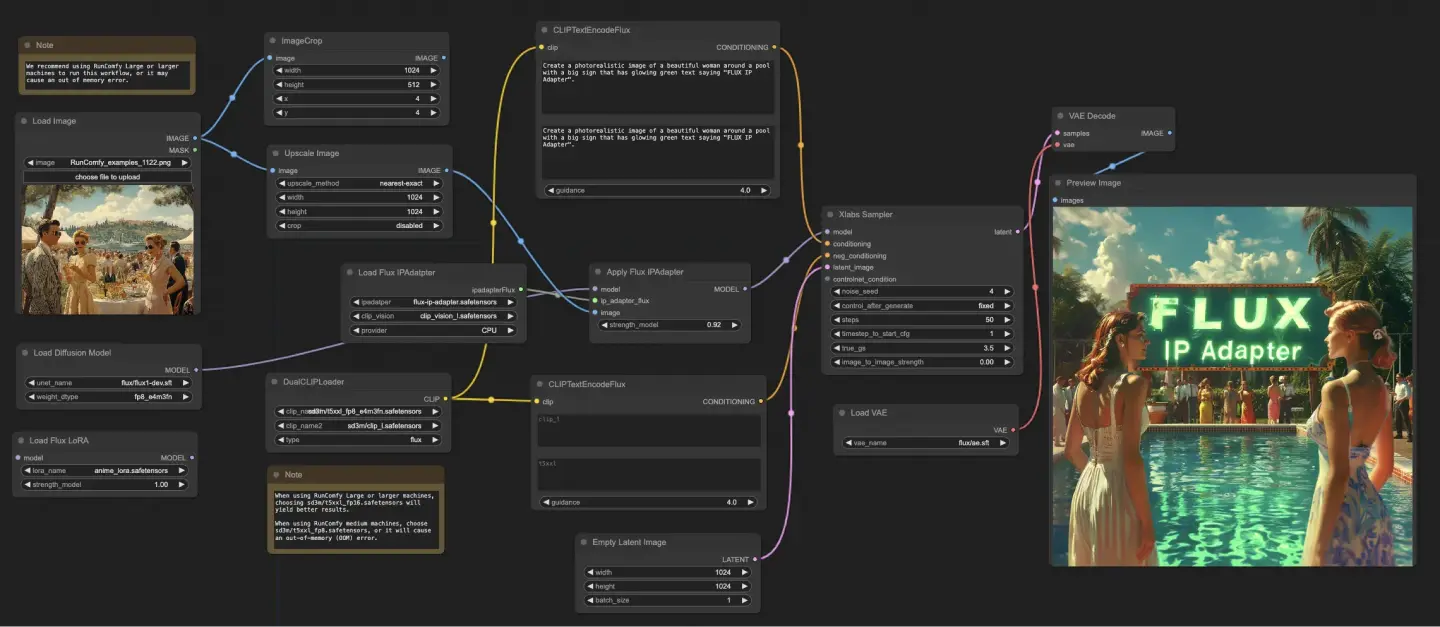
5.7.1. ComfyUI FLUX IPAdapter: Download
5.7.2. ComfyUI FLUX IPAdapter Versione Online: ComfyUI FLUX IPAdapter
Sulla Piattaforma RunComfy, la nostra versione online pre-carica tutte le modalità e i nodi necessari per te. Inoltre, offriamo macchine GPU ad alte prestazioni, garantendoti un'esperienza senza sforzo con ComfyUI FLUX IPAdapter.
5.7.3. Spiegazione di ComfyUI FLUX IPAdapter:
Il flusso di lavoro ComfyUI FLUX IPAdapter inizia caricando i modelli necessari, inclusi il modello UNET (UNETLoader), il modello CLIP (DualCLIPLoader) e il modello VAE (VAELoader).
I prompt di testo positivi e negativi vengono codificati utilizzando CLIPTextEncodeFlux. Il condizionamento del testo positivo viene utilizzato per guidare il processo di generazione di ComfyUI FLUX.
L'immagine di input viene caricata utilizzando LoadImage. Il LoadFluxIPAdapter carica l'IP-Adapter per il modello FLUX, che viene poi applicato al modello UNET caricato utilizzando ApplyFluxIPAdapter. L'ImageScale scala l'immagine di input alla dimensione desiderata prima di applicare l'IP-Adapter.
- LoadFluxIPAdapter: Carica l'IP-Adapter per il modello FLUX.
- Modello IP Adapter: flux-ip-adapter.safetensors
- CLIP Vision Encoder: clip_vision_l.safetensors
L'EmptyLatentImage crea una rappresentazione latente vuota come punto di partenza per la generazione di ComfyUI FLUX.
L'XlabsSampler esegue il processo di campionamento, prendendo il FLUX UNET con IP-Adapter applicato, la codifica del testo positivo e negativo, e la rappresentazione latente vuota come input. Genera una rappresentazione latente.
Il VAEDecode decodifica la rappresentazione latente generata nell'output finale utilizzando il FLUX VAE caricato. Il nodo PreviewImage visualizza un'anteprima dell'output finale.
Il flusso di lavoro ComfyUI FLUX IPAdapter sfrutta la potenza di ComfyUI FLUX e dell'IP-Adapter per generare output di alta qualità che si allineano ai prompt di testo forniti. Applicando l'IP-Adapter al FLUX UNET, il flusso di lavoro consente la generazione di output che catturano le caratteristiche e lo stile desiderati specificati nel condizionamento del testo.
5.8. Flusso di Lavoro
ComfyUI: Flux LoRA Trainer

5.8.1. ComfyUI FLUX LoRA Trainer: Download
5.8.2. Spiegazione di ComfyUI Flux LoRA Trainer:
Il flusso di lavoro ComfyUI FLUX LoRA Trainer consiste in più fasi per l'addestramento di un LoRA utilizzando l'architettura FLUX in ComfyUI.
Selezione e Configurazione del Modello ComfyUI FLUX: Il nodo FluxTrainModelSelect viene utilizzato per selezionare i componenti per l'addestramento, inclusi UNET, VAE, CLIP e encoder di testo CLIP. Il nodo OptimizerConfig configura le impostazioni dell'ottimizzatore per l'addestramento di ComfyUI FLUX, come il tipo di ottimizzatore, il tasso di apprendimento e il decadimento del peso. I nodi TrainDatasetGeneralConfig e TrainDatasetAdd vengono utilizzati per configurare il dataset di addestramento, inclusi la risoluzione, le impostazioni di aumento e le dimensioni del batch.
Inizializzazione dell'Addestramento ComfyUI FLUX: Il nodo InitFluxLoRATraining inizializza il processo di addestramento LoRA utilizzando i componenti selezionati, la configurazione del dataset e le impostazioni dell'ottimizzatore. Il nodo FluxTrainValidationSettings configura le impostazioni di validazione per l'addestramento, come il numero di campioni di validazione, la risoluzione e la dimensione del batch.
Ciclo di Addestramento ComfyUI FLUX: Il nodo FluxTrainLoop esegue il ciclo di addestramento per il LoRA, iterando per un numero specificato di passaggi. Dopo ogni ciclo di addestramento, il nodo FluxTrainValidate valida il LoRA addestrato utilizzando le impostazioni di validazione e genera output di validazione. Il nodo PreviewImage visualizza un'anteprima dei risultati della validazione. Il nodo FluxTrainSave salva il LoRA addestrato a intervalli specificati.
Visualizzazione della Perdita ComfyUI FLUX: Il nodo VisualizeLoss visualizza la perdita di addestramento nel corso dell'addestramento. Il nodo SaveImage salva il grafico della perdita per ulteriori analisi.
Elaborazione degli Output di Validazione ComfyUI FLUX: I nodi AddLabel e SomethingToString vengono utilizzati per aggiungere etichette agli output di validazione, indicando i passaggi di addestramento. I nodi ImageBatchMulti e ImageConcatFromBatch combinano e concatenano gli output di validazione in un singolo risultato per una visualizzazione più semplice.
Finalizzazione dell'Addestramento ComfyUI FLUX: Il nodo FluxTrainEnd finalizza il processo di addestramento LoRA e salva il LoRA addestrato. Il nodo UploadToHuggingFace può essere utilizzato per caricare il LoRA addestrato su Hugging Face per la condivisione e l'uso successivo con ComfyUI FLUX.
5.9. Flusso di Lavoro ComfyUI: Flux Latent Upscaler
5.9.1. ComfyUI Flux Latent Upscaler: Download
5.9.2. Spiegazione di ComfyUI Flux Latent Upscaler:
Il flusso di lavoro ComfyUI Flux Latent Upscale inizia caricando i componenti necessari, inclusi CLIP (DualCLIPLoader), UNET (UNETLoader) e VAE (VAELoader). Il prompt di testo viene codificato utilizzando il nodo CLIPTextEncode, e la guida viene applicata utilizzando il nodo FluxGuidance.
Il nodo SDXLEmptyLatentSizePicker+ specifica la dimensione della rappresentazione latente vuota, che serve come punto di partenza per il processo di upscaling in FLUX. La rappresentazione latente viene quindi elaborata attraverso una serie di passaggi di upscaling e cropping utilizzando i nodi LatentUpscale e LatentCrop.
Il processo di upscaling è guidato dalla codifica del testo condizionante e utilizza il nodo SamplerCustomAdvanced con il metodo di campionamento selezionato (KSamplerSelect) e i livelli di rumore programmati (BasicScheduler). Il nodo ModelSamplingFlux imposta i parametri di campionamento.
La rappresentazione latente upscalata viene quindi composita con la rappresentazione latente originale utilizzando il nodo LatentCompositeMasked e una maschera generata dai nodi SolidMask e FeatherMask. Il rumore viene iniettato nella rappresentazione latente upscalata utilizzando il nodo InjectLatentNoise+.
Infine, la rappresentazione latente upscalata viene decodificata nell'output finale utilizzando il nodo VAEDecode, e la nitidezza intelligente viene applicata utilizzando il nodo ImageSmartSharpen+. Il nodo PreviewImage visualizza un'anteprima dell'output finale generato da ComfyUI FLUX.
Il flusso di lavoro ComfyUI FLUX Latent Upscaler include anche varie operazioni matematiche utilizzando i nodi SimpleMath+, SimpleMathFloat+, SimpleMathInt+ e SimpleMathPercent+ per calcolare dimensioni, rapporti e altri parametri per il processo di upscaling.