オーディオリアクティブダンサー進化
オーディオリアクティブダンサー進化ワークフローは、ビデオの被写体を音楽のビートに同期した魅力的なアニメーションに変換し、動的で幾何学的、サイケデリックな背景に設定します。柔軟性を考慮して設計されており、ユーザーがビデオフレーム、マスキング、オーディオ応答性、およびパターンの詳細を制御できるようにします。拡張マスク、ControlNet、ビート同期ノイズアニメーションなどの機能を備えたこのComfyUIワークフローは、芸術、音、動きを融合させ、視覚的に没入感のあるリズミカルな体験をオーディオリアクティブビジュアルで作成することができます。ComfyUI Audioreactive Dancers Evolved ワークフロー

このワークフローを実行しますか?
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Audioreactive Dancers Evolved 例
ComfyUI Audioreactive Dancers Evolved 説明
被写体(ダンサー)を変換して、さまざまな複雑なジオメトリとサイケデリックなパターンで構成された動的なオーディオリアクティブな背景を与えることで、驚くべきビデオアニメーションを作成します。このワークフローは単一または複数の被写体で使用できます。このワークフローを使用すると、音楽のリズムに完全に同期した魅力的なオーディオリアクティブな視覚効果を生み出すことができ、没入感のある体験を提供します。ワークフローは単一の被写体または複数の被写体で使用でき、すべてオーディオリアクティブな要素で強化されています。
オーディオリアクティブダンサー進化ワークフローの使用方法:
- 入力セクションに被写体ビデオをアップロードします
- 最終ビデオの希望する幅と高さを選択し、「every_nth」で入力ビデオのスキップするフレーム数を選択します。「frame_load_cap」でレンダリングする総フレーム数を制限することもできます。
- ポジティブおよびネガティブプロンプトを記入します。シーンの切り替えが発生するタイミングに合わせてバッチフレーム時間を設定します。
- デフォルトのIPアダプター被写体マスク色ごとに画像をアップロードします:
- 赤、緑、青 = 被写体
- 黒 = 背景
- 白 = 白のオーディオリアクティブ拡張マスク
- 黄、マゼンタ = 背景ノイズマスクパターン
- 「Models」セクションで良好なLCMチェックポイント(私はMachine DelusionsによるParadigmLCMを使用します)をロードします。
- モデルローダーの下にあるLoraスタッカーを使用して任意のロラを追加します
- キューをプロンプトします
ビデオガイド
ノードとグループカラー
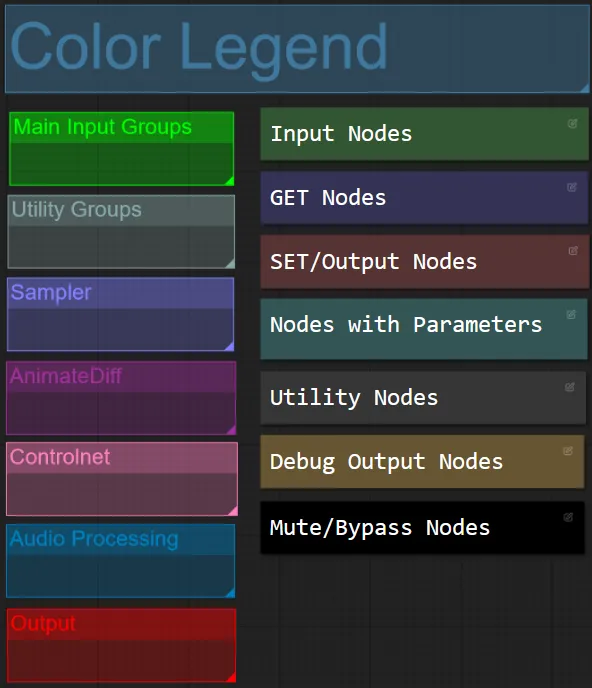
- このワークフローでは、各グループ内の機能に基づいてノードを色で区別しています。
- グループセクションのタイトルは、区別しやすいように色分けされています。
入力
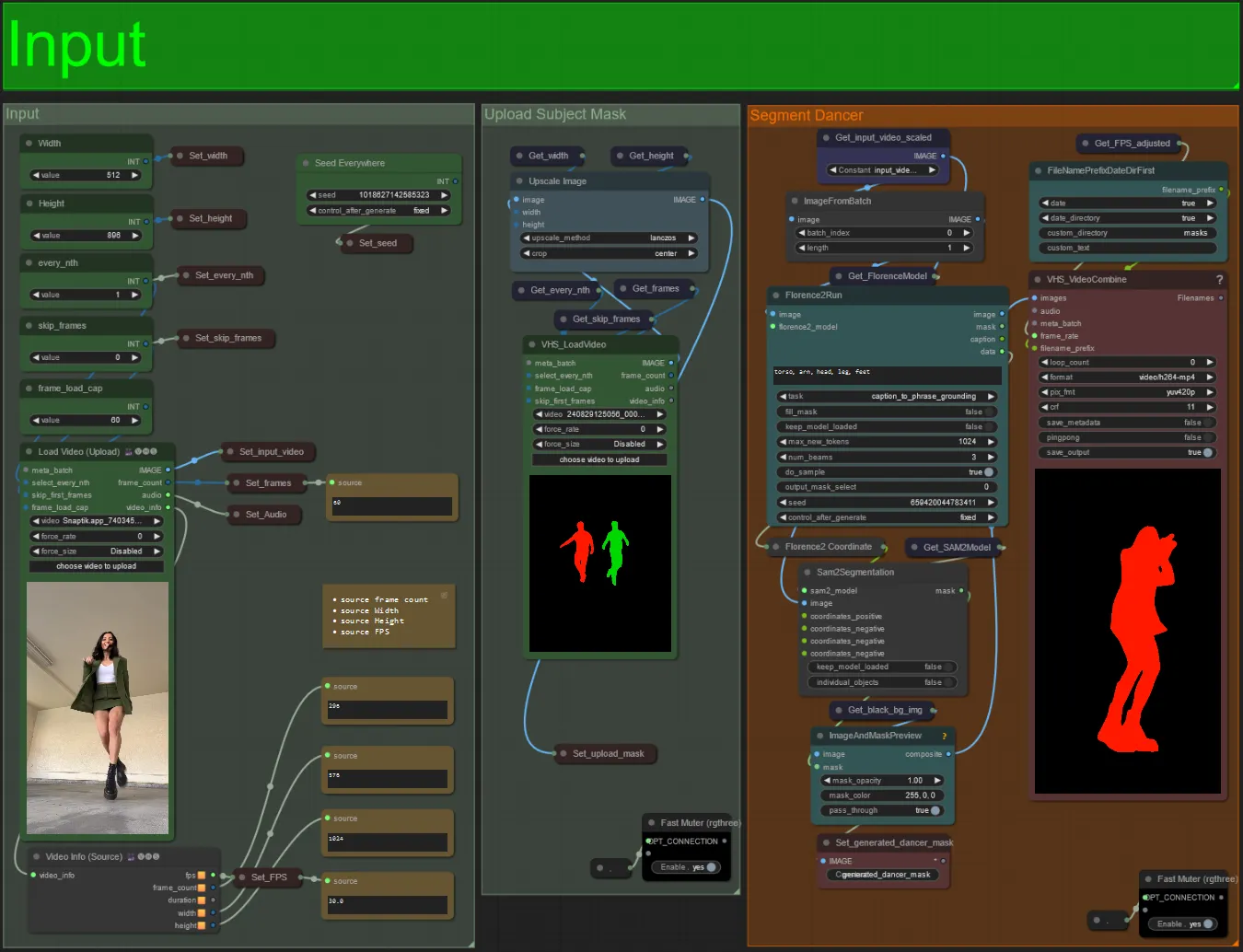
- 希望する被写体ビデオをLoad Video(アップロード)ノードにアップロードします。
- 左上の2つの入力を使用して出力の幅と高さを調整できます。
- every_nthは、すべてのフレーム、3フレームごとに1つのフレームを使用するかどうかを設定します(2 = すべての2番目のフレーム)。デフォルトでは1に設定されています。
- skip_framesは、ビデオの最初のフレームをスキップするために使用されます。(100 = 入力ビデオの最初の100フレームをスキップします)。デフォルトでは0に設定されています。
- frame_load_capは、入力ビデオの総フレーム数をロードするかどうかを指定します。設定をテストするときは、低く設定するのが最適です(例: 30 - 60)その後、最終ビデオをレンダリングするときに増加または0(フレームキャップなし)に設定します。
- 右下の数値フィールドは、アップロードされた入力ビデオに関する情報を表示します: 総フレーム数、幅、高さ、およびFPSが上から下に表示されます。
- 既に生成された被写体のマスクビデオがある場合、「Upload Subject Mask」セクションをミュート解除してマスクビデオをアップロードできます。オプションとして、「Segment Dancer」セクションをミュートして、処理時間を節約できます。
- 時々、セグメント化された被写体が完璧ではない場合があります。上記で表示される右下のプレビューでマスクの品質を確認できます。その場合、「Florence2Run」ノードのプロンプトを調整して、「head」、「chest」、「legs」などの異なる体の部分をターゲットにして、より良い結果が得られるかどうかを確認できます。
プロンプト
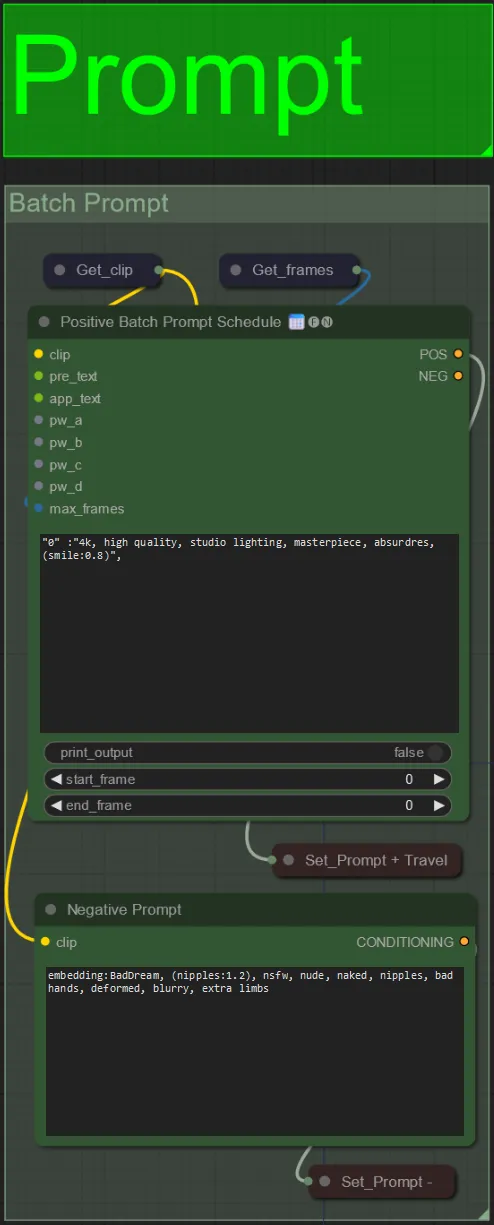
- バッチフォーマットを使用してポジティブプロンプトを設定します:
- 例: “0”: “4k, masterpiece, 1girl standing on the beach, absurdres”, “25”: “HDR, sunset scene, 1girl with black hair and a white jacket, absurdres”, …
- ネガティブプロンプトは通常の形式です。必要に応じて埋め込みを追加できます。
オーディオ処理
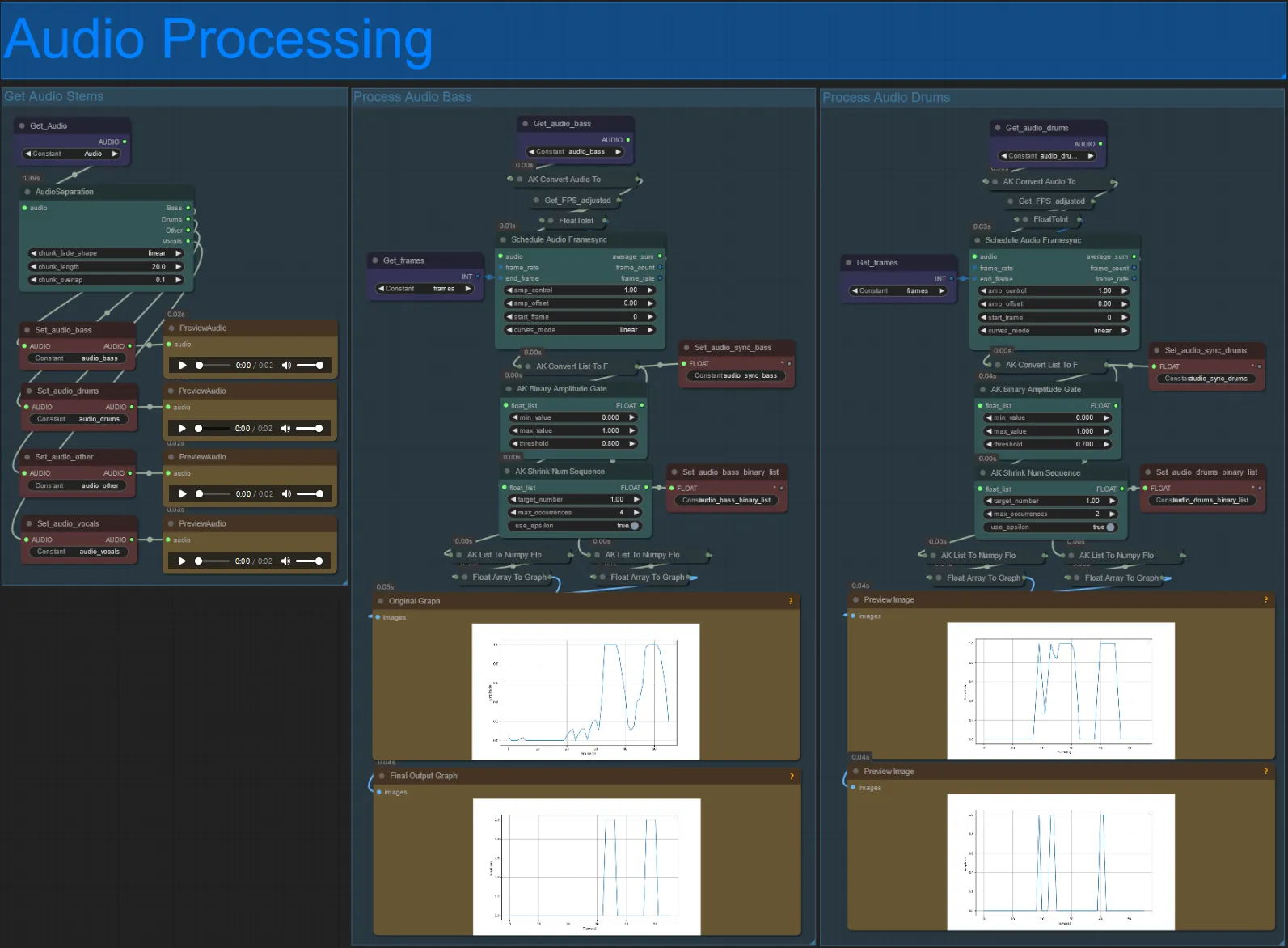
- このセクションは、入力ビデオからオーディオを取り込み、ステム(ベース、ドラム、ボーカルなど)を抽出し、入力ビデオフレームと同期した正規化された振幅に変換して、オーディオリアクティブビジュアルを作成します。
- amp_control = 振幅が移動できる全範囲。
- amp_offset = 振幅が取ることができる最小値。
- 例: amp_control = 0.8とamp_offset = 0.2は、信号が0.2から1.0まで移動することを意味します。
- 時々、Drumsステムには曲の実際のBassノートが含まれることがあります。それぞれのプレビューを見て、オーディオリアクティブマスクに使用するものを決定します。
- グラフを使用して、そのステムの信号がビデオの長さにわたってどのように変化するかをよく理解してください。
ボロノイジェネレーター
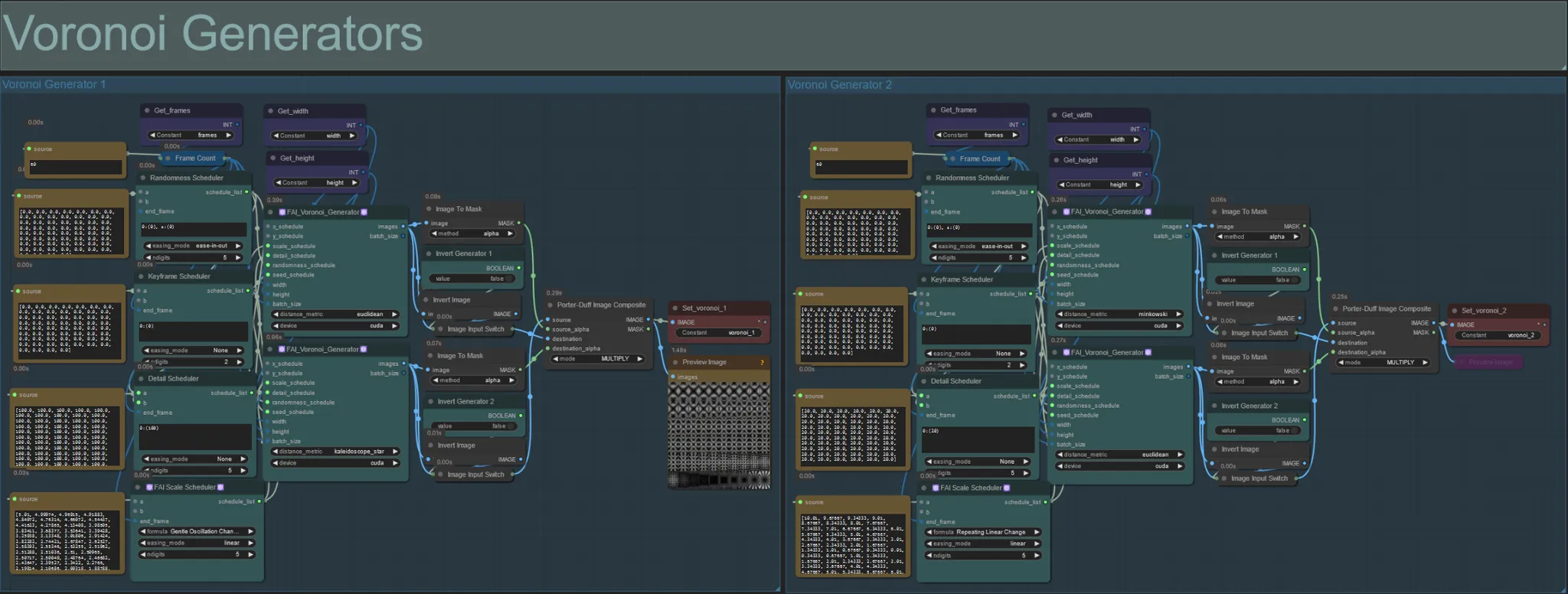
- このセクションは、2つのFAI_Voronoi_Generatorカスタムノードを使用してボロノイノイズパターンを生成し、それらをMultiplyを使用して合成します。
- 親にあるRandomness Schedulerの値を0から増やして最終出力の対称パターンを崩すことができます。
- Detail Schedulerの値を増やして、出力ノイズパターンの詳細数を増やします。値が低いとノイズの差別化が少なくなります。
- FAI Scale Schedulerノードの「formula」パラメータを変更して、最終ノイズパターンの動きに大きな影響を与えることができます。
- FAI_Voronoi_Generatorノード自体の「distance_metric」関数を変更して、生成されるパターンと形状に大きな影響を与えることができます。
オーディオマスク
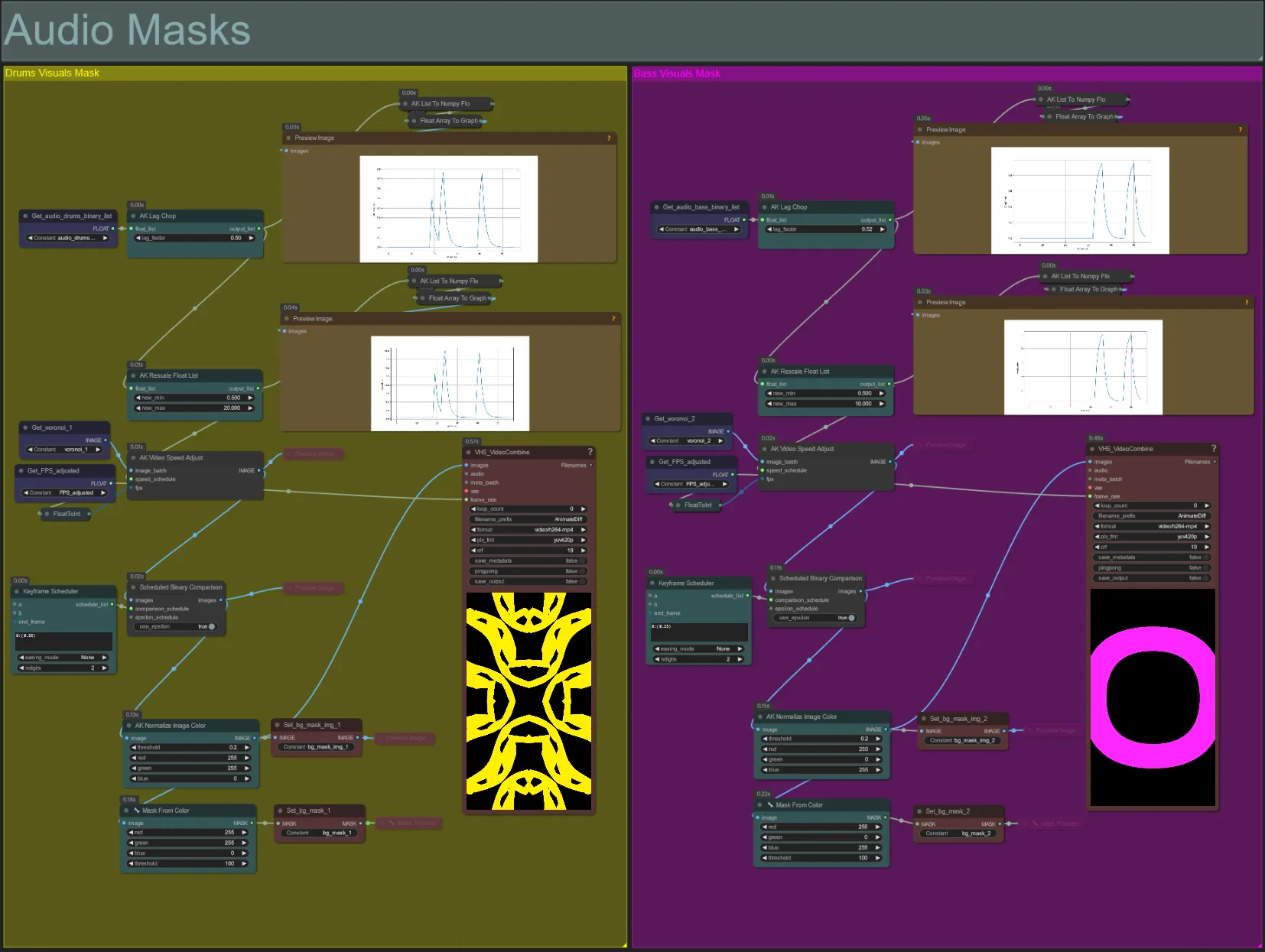
- このセクションは、ボロノイノイズ画像バッチをカラー化されたマスクに変換し、被写体と合成するために使用され、ベースまたはドラムのオーディオステムのビートに合わせて動きを同期させます。これらのマスクはオーディオリアクティブ効果を作成するために不可欠です。
- AK Lag Chopノードの「lag_factor」を増やして、最終振幅グラフをより「とがった」ものにします。これにより、出力ノイズの動きがより突然に加速および減速しますが、lag_factorが低いと各ビート後の動きの減速がより緩やかになります。これは、ノイズマスクアニメーションがあまりに「飛び跳ね」すぎたり不規則に見えるのを避けるために使用されます。
- AK Rescale Float Listは、正規化された振幅値を0-1からnew_minおよびnew_maxに再マッピングするために使用されます。値1.0はノイズアニメーションの30FPS再生速度を表し、0.5は15FPS、2.0は60FPSなどを表します。この値を調整して、オーディオリアクティブノイズパターンがビートから外れたとき(振幅0.0)にどれだけ遅く動くか、およびビートに乗ったとき(振幅1.0)にどれだけ速く動くかを変更します。
- Keyframe Schedulerは、マスクの外観に大きな影響を与えます。ノイズ入力画像のピクセル輝度値のしきい値を指定するためにフロート値のリストを作成し、ノイズの一部が切り取られて最終マスクに変換されます。この値を下げて入力ノイズをより多く保持し、増やしてノイズをより少なく保持します。
拡張マスク
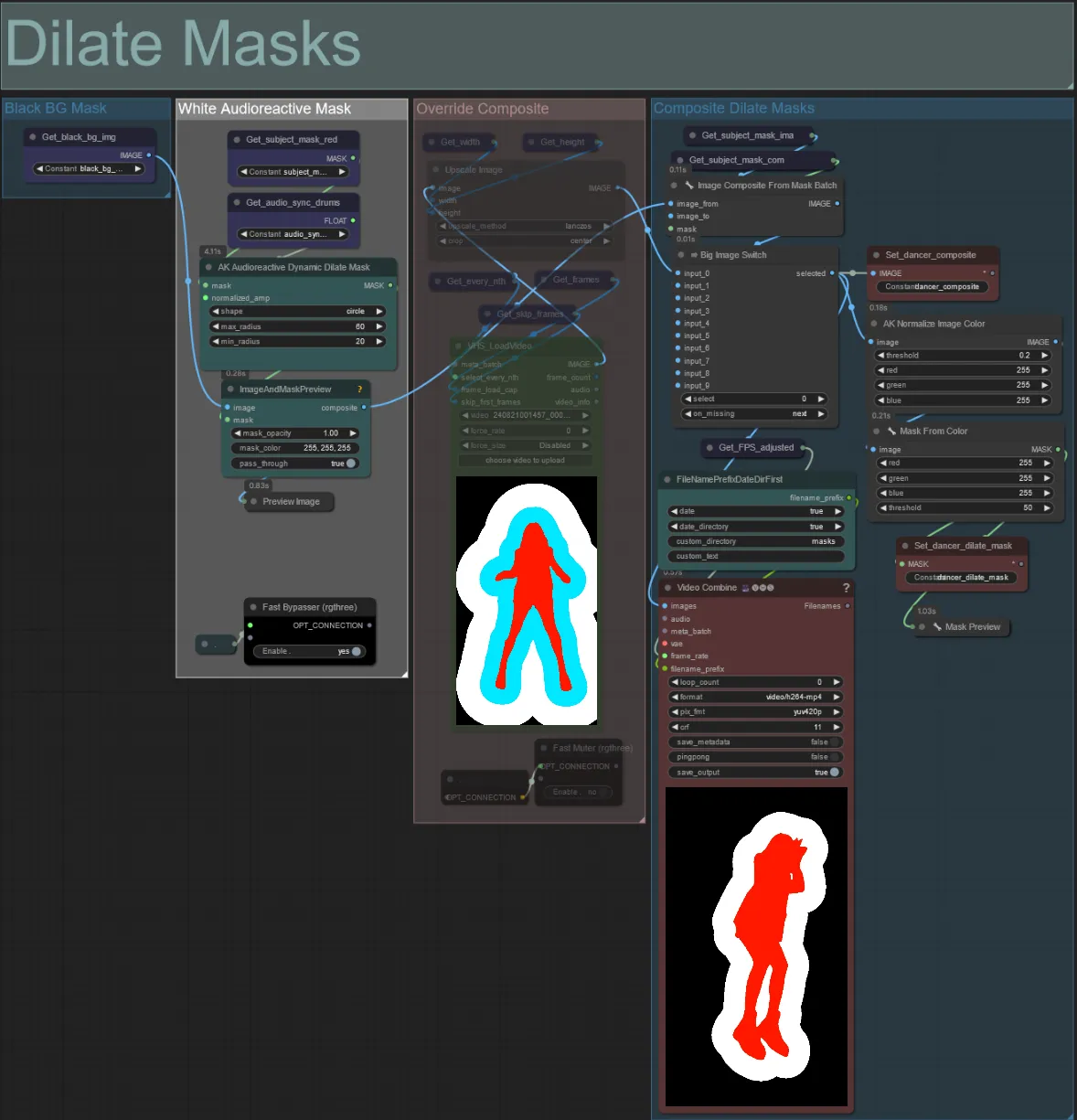
- 各色分けされたグループは、それによって生成される拡張マスクの色に対応しています。
- 次のノードを使用して、拡張マスクの最小および最大半径、形状を設定できます:
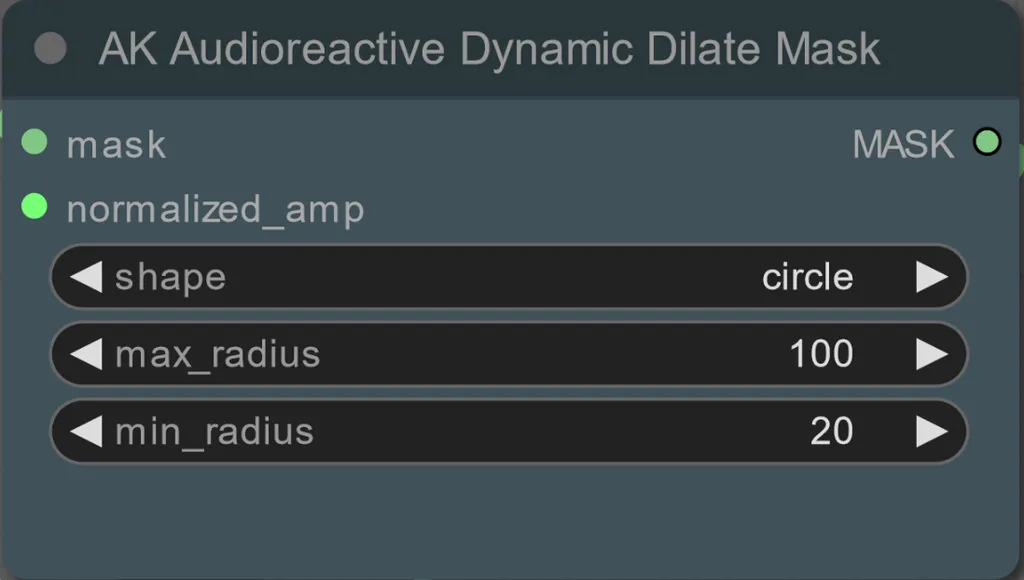
- shape: 「circle」は最も正確ですが生成に時間がかかります。最終レンダリングを行う準備ができたときに設定します。「square」は計算が速いですが、正確さが低いため、ワークフローをテストしてIPアダプター画像を決定するのに最適です。
- max_radius: 振幅値が最大(1.0)のときのマスクの半径(ピクセル単位)。
- min_radius: 振幅値が最小(0.0)のときのマスクの半径(ピクセル単位)。
- 既に生成された合成マスクビデオがある場合、「Override Composite Mask」グループをミュート解除してアップロードできます。オーバーライドする場合、処理時間を節約するために拡張マスクグループをバイパスすることをお勧めします。
潜在ノイズマスク
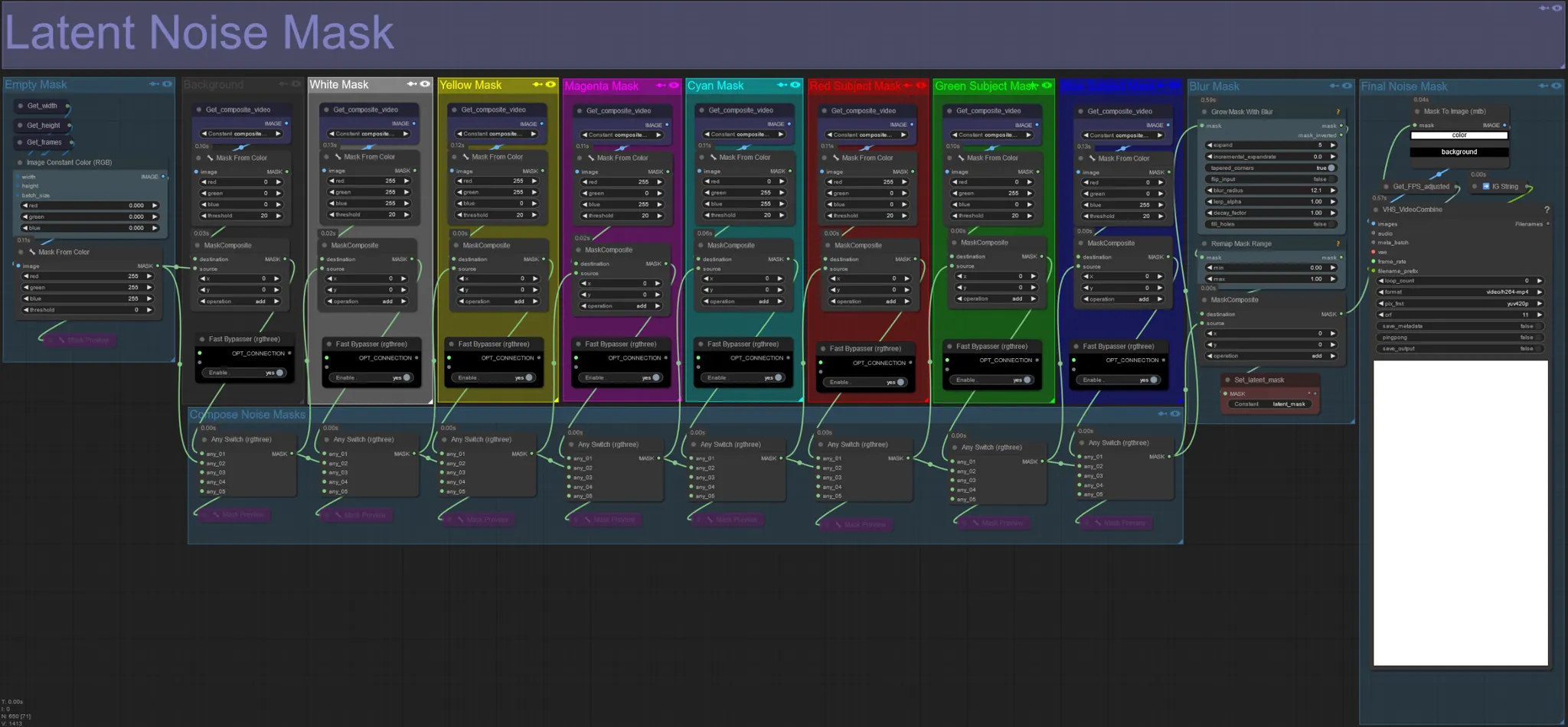
- 潜在ノイズマスクを使用して、ksamplerによって実際に拡散される(夢見られる)マスクを制御します。拡散したくない色付きマスクに対応するグループをバイパスします(つまり、元のビデオからの要素を表示したい場合)。
- すべてのマスクグループを有効にすると、最終ノイズマスクが白になります(すべてが拡散されます)。
- 例: Fast Bypasserノードをクリックして赤の被写体マスクグループをバイパスすると、最終出力にダンサーや被写体が表示されます。
元の入力ビデオ:

赤と黄色のマスクグループをバイパス:

合成マスク
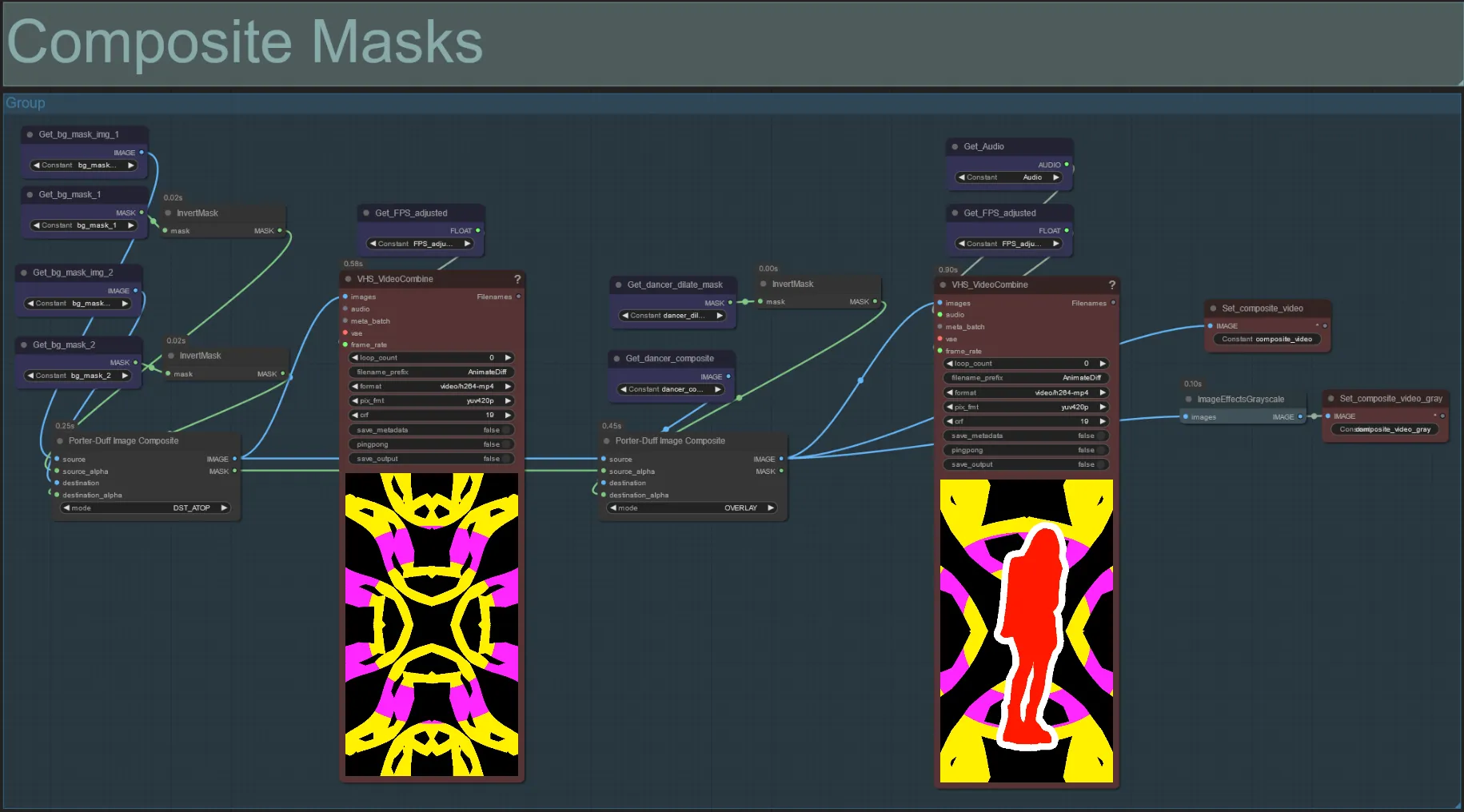
- このセクションは、被写体マスク(およびオーディオリアクティブ拡張マスクが有効な場合)とボロノイノイズマスクの最終合成を作成します。
モデル
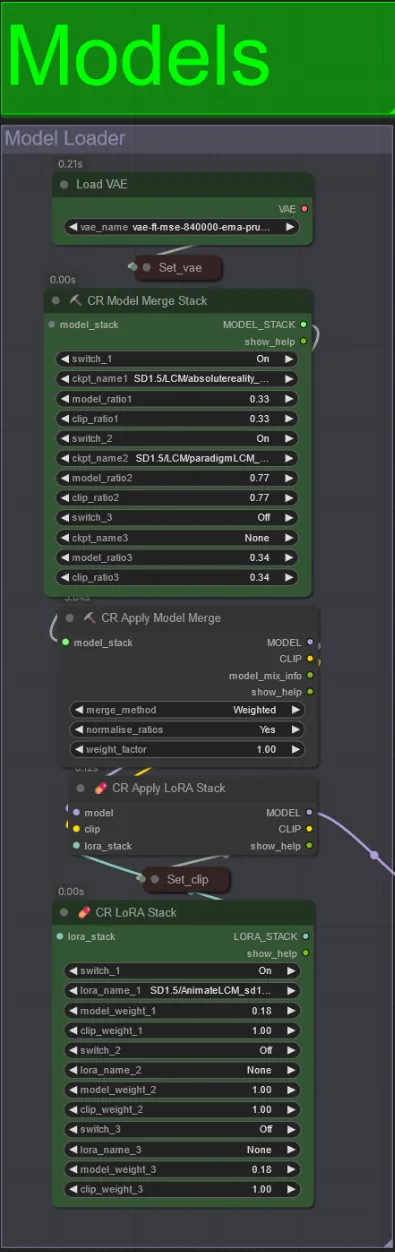
- チェックポイントには良好なLCMモデルを使用します。Machine DelusionsによるParadigmLCMをお勧めします。
- 複数のモデルをModel Merge Stackを使用してマージし、さまざまな興味深い効果を得ることができます。有効なモデルの重みが1.0になるようにしてください。
- さらにアニメーションLCM_sd15_t2v_lora.safetensorsを低い重み0.18で指定して、最終結果をさらに強化することもできます。
- モデルローダーの下にあるLoraスタッカーを使用して、追加のLoraをモデルに追加します。
アニメーションディフ

- 使用したMotion Lora(LiquidAF-0-1.safetensors)の代わりに異なるものを設定できます
- 出力の動きの量を増減するためにスケールとエフェクトのフロートを増減します。
IPアダプター
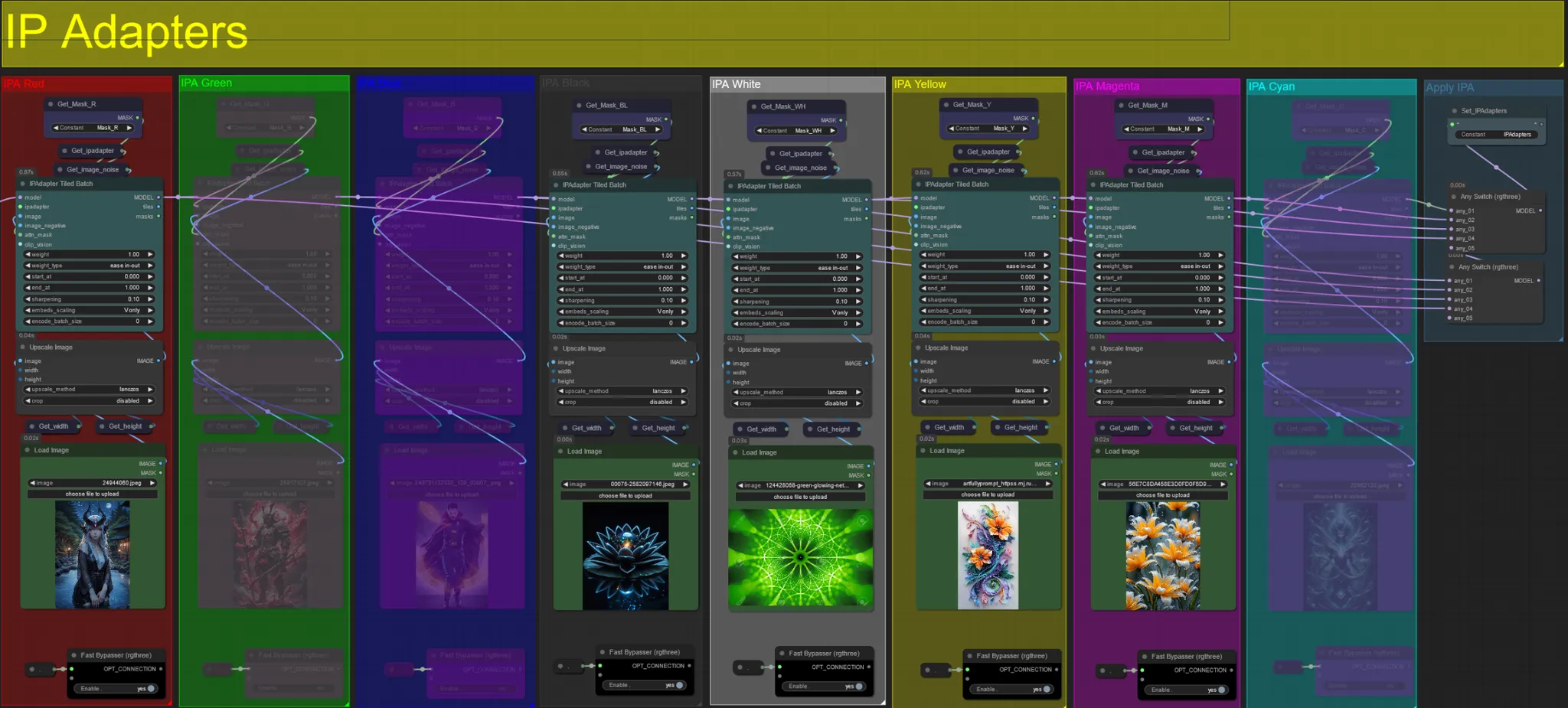
- ここでは、各拡張マスクおよびビデオの被写体の背景をレンダリングするために使用される参照画像を指定できます。
- 各グループの色はターゲットとするマスクを表しています:
赤、緑、青:
- 被写体マスク参照画像。
黒:
- 背景マスク画像、背景用の参照画像をアップロードしてください。
白:
- 拡張マスク参照画像、使用する各色の拡張マスクの参照画像をアップロードしてください。
黄、マゼンタ
- ボロノイノイズマスク参照画像。
ControlNet

- このワークフローは、AD、Lineart、QR Code、Depth、OpenPoseを含む5つの異なるコントロールネットを使用します。
- コントロールネットへのすべての入力は自動的に生成されます
- 必要に応じて、「Override」グループをミュート解除してLineart、Depth、Openposeコントロールネットの入力ビデオをオーバーライドできます:
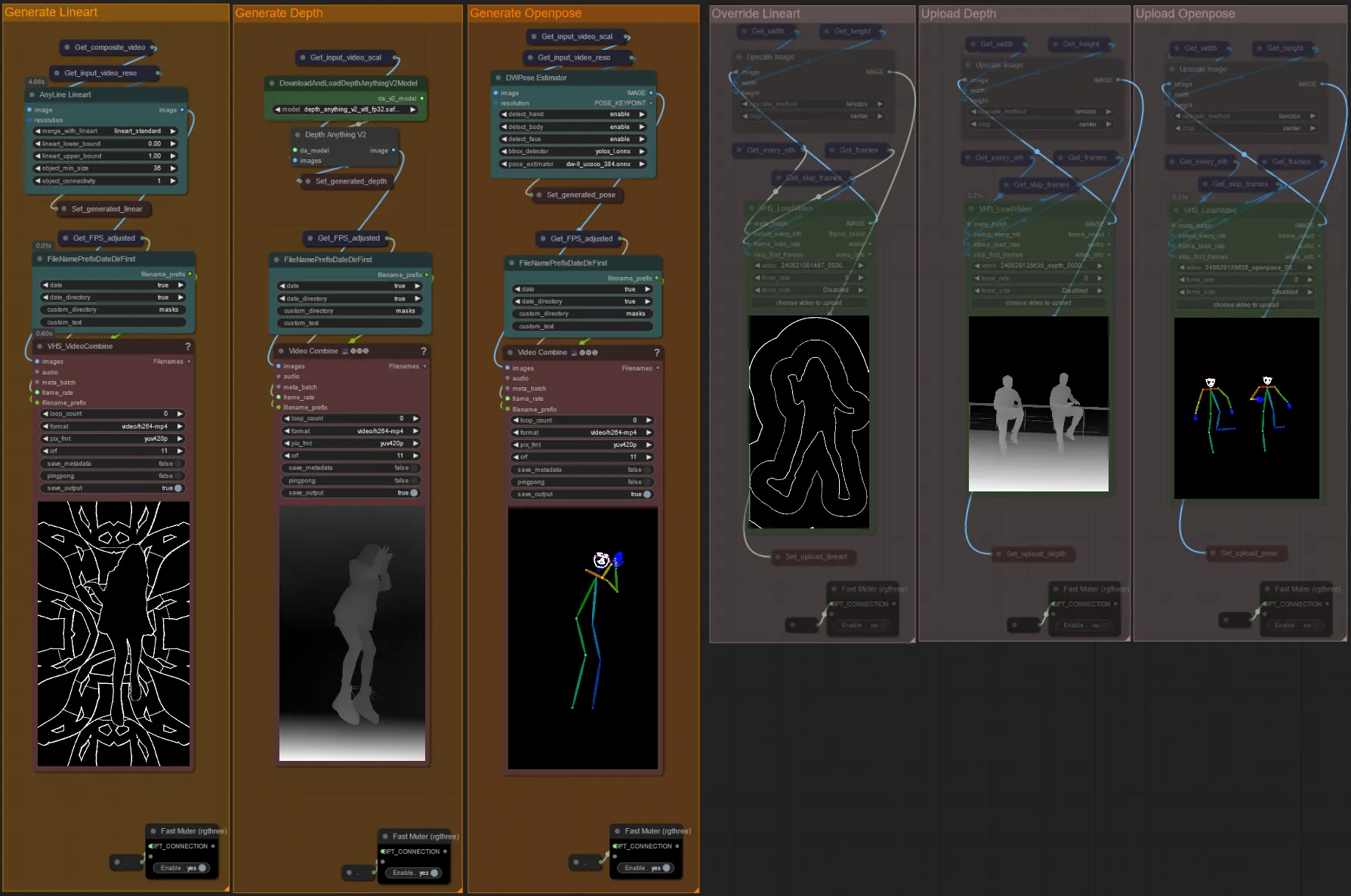
- オーバーライドする場合、処理時間を節約するために「Generate」グループもミュートすることをお勧めします。
ヒント:
- Ksamplerをバイパスし、完全な入力ビデオでレンダリングを開始します。すべてのプリプロセッサビデオが生成されたら、それらを保存し、それぞれのオーバーライドにアップロードします。これ以降、ワークフローをテストするときに、各プリプロセッサビデオが個別に生成されるのを待つ必要がなくなります。
サンプラー
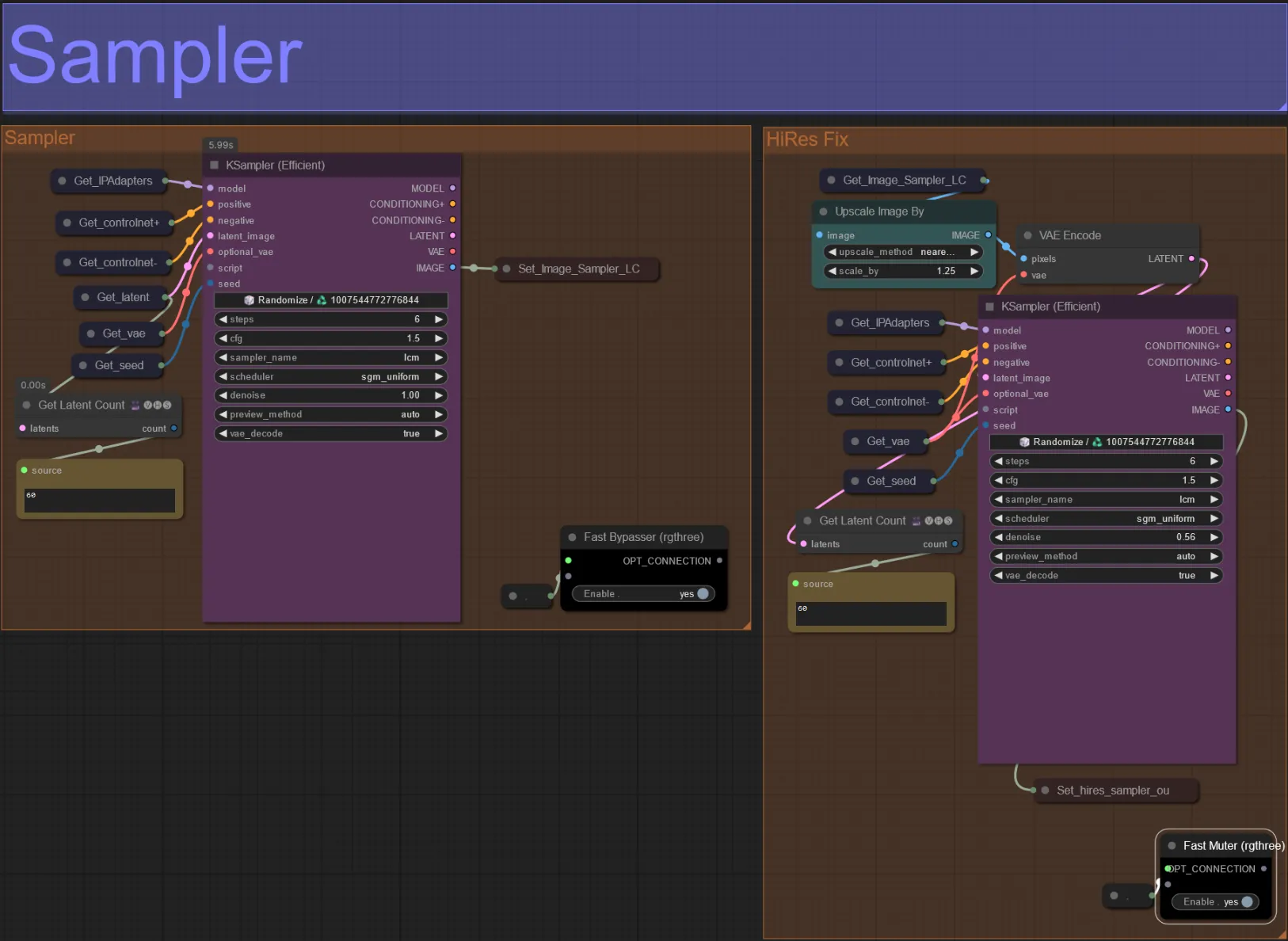
- デフォルトでは、テスト時の処理時間を節約するためにHiRes Fixサンプラーグループはミュートされます
- 処理時間を節約するために、拡張マスク設定を試すときにサンプラーグループをバイパスすることをお勧めします。
- 最終レンダリングでは、HiRes Fixグループをミュート解除して、最終結果をアップスケールして詳細を追加できます。
出力
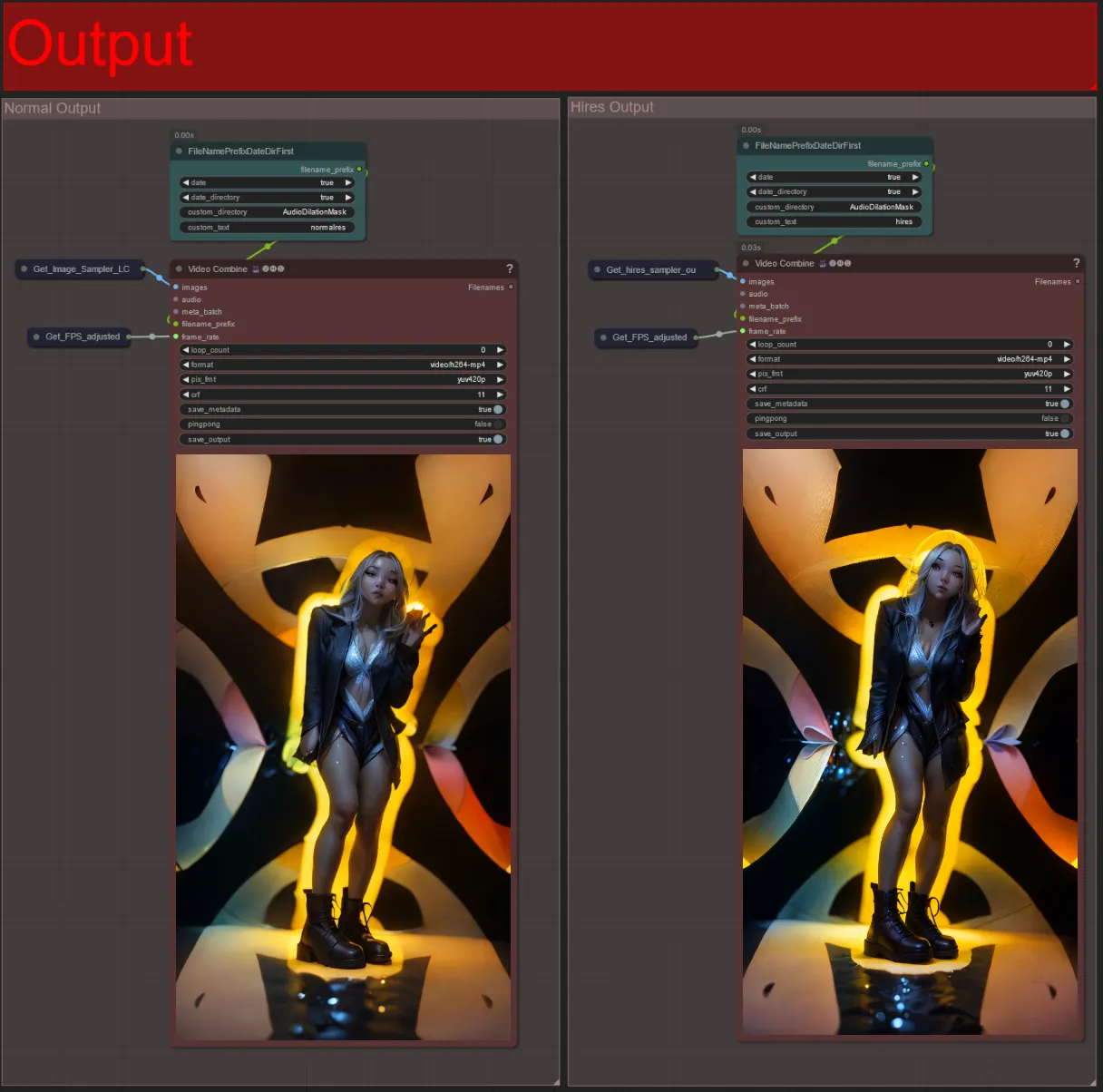
- 出力グループは2つあります: 左は標準サンプラー出力用、右はHiRes Fixサンプラー出力用です。
- “FileNamePrefixDateDirFirst”ノードで“custom_directory”文字列を変更して、ファイルが保存される場所を変更できます。デフォルトでは、このノードはComfyUIの“output”ディレクトリにタイムスタンプ付きディレクトリで出力ビデオを保存します
- 例:
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- 例:
オーディオリアクティブビデオを作成することで、被写体に没入感のある脈動するエネルギーを追加し、すべてのフレームがリアルタイムでビートに応答します。オーディオリアクティブアートの世界に飛び込み、リズム主導の変革を楽しんでください!
著者について
Akatz AI:
- ウェブサイト:
連絡先:
- Email: akatzfey@sendysoftware.com
