Dance Video Transform | 장면 맞춤화 & 얼굴 교체
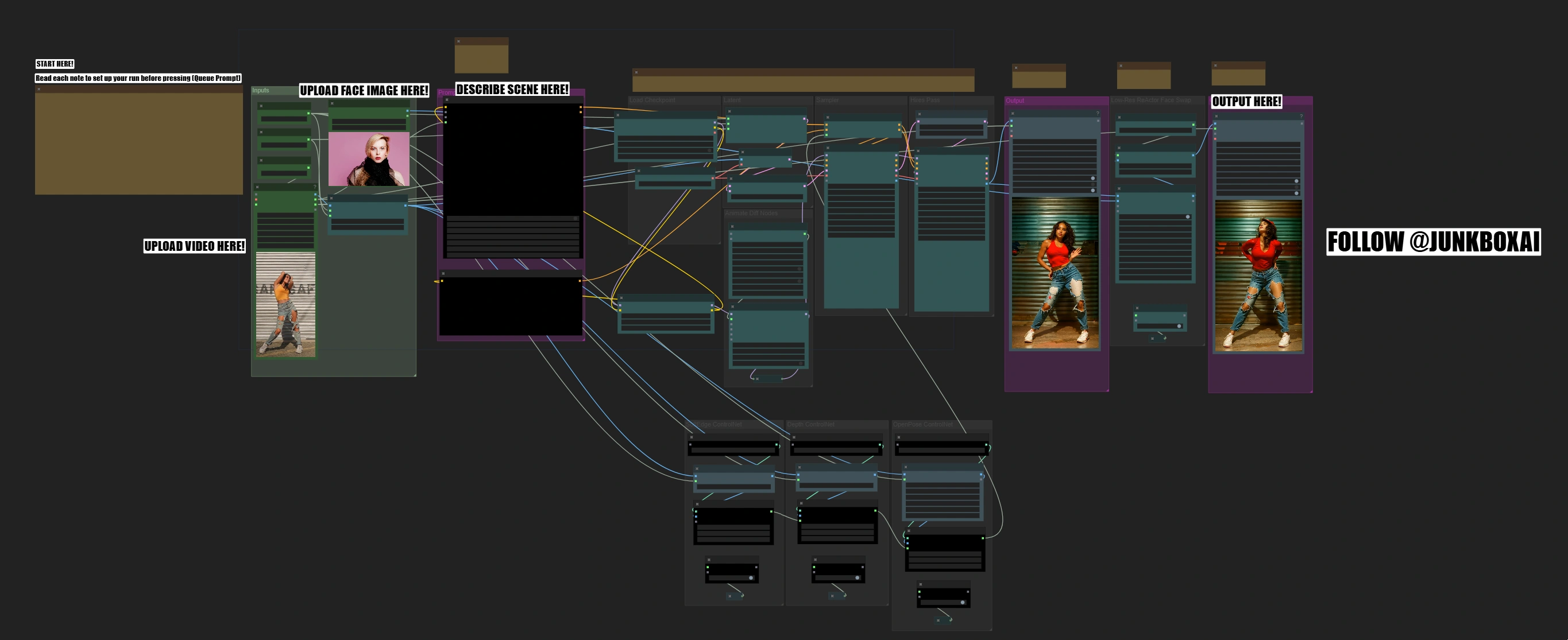
이 Dance Video Transform 워크플로우는 SD1.5 모델, AnimateDiff, ControlNet 및 ReActor 얼굴 교체를 결합하여 고품질 안무 변환을 제공합니다. Edge, Depth 및 OpenPose의 세 가지 ControlNet 지침을 사용하여 댄서의 움직임을 보존하며, ReActor와 CodeFormer는 향상된 충실도로 정확한 얼굴 교체를 보장합니다. 이 워크플로우는 배치 프롬프트 스케줄링을 통해 동적 장면 제어를 지원하여 프레임별 맞춤화를 가능하게 합니다. AnimateDiff의 컨텍스트 옵션과 적응형 움직임 스케일링으로 변환 내내 부드럽고 자연스러운 움직임 보존을 보장합니다.ComfyUI Dance Video Transform 워크플로우
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Dance Video Transform 예제
ComfyUI Dance Video Transform 설명
Dance Video Transform ComfyUI 워크플로우의 기능
Dance Video Transform ComfyUI 워크플로우는 원본 안무를 보존하면서 전문적인 얼굴 교체와 함께 댄스 비디오를 놀라운 새로운 장면으로 변환하여 고품질 출력을 보장합니다. 이 과정은 움직임 분석에서 얼굴 교체까지 단계별로 진행되며 각 단계에서 품질 검사가 가능합니다.
Dance Video Transform ComfyUI 워크플로우의 작동 방식
이 워크플로우는 복잡한 변환을 여러 단계로 자동화하여 비디오, 얼굴 이미지 및 장면 설명만 필요로 합니다: 움직임 분석 → 스타일 전환 → 얼굴 교체
- 댄스 동작 및 공간 정보를 분석합니다
- 설명에 따라 장면을 변환합니다
- 표현을 유지하면서 새로운 얼굴을 통합합니다
Dance Video Transform ComfyUI 워크플로우의 주요 기능
- 세로 형식에 최적화 (9:16 화면 비율)
- 안정적인 변환을 위한 트리플 ControlNet 시스템
- 자연스러운 블렌딩의 전문 얼굴 교체
- 빠른 테스트 모드 (50 프레임을 몇 분 안에 처리)
- 고해상도 출력 지원 (최대 896px 높이)
- AnimateDiff를 사용한 고급 움직임 보존
- 품질 검증을 위한 이중 출력 시스템
빠른 시작 가이드
1단계: 초기 설정
각 노드에서:
-
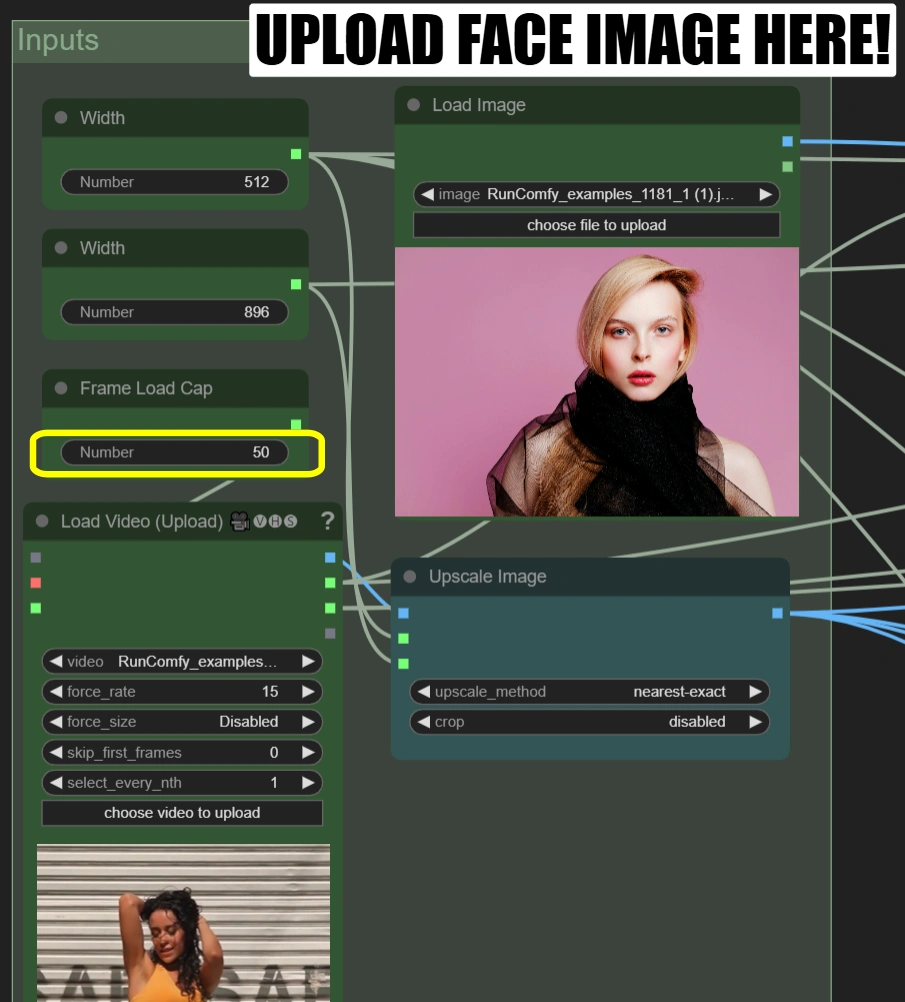
비디오 로드 (업로드):
- 9:16 화면 비율의 10-15초 댄스 비디오 업로드
- 비디오가 9:16이 아닌 경우, 비디오에 맞게 너비 및 높이 매개변수를 조정해야 합니다.
- 프레임 로드 제한: 50 (빠른 테스트를 위해 처음 50 프레임만 렌더링)
-
이미지 로드:
- 깨끗하고 정면을 향한 얼굴 사진 업로드
-
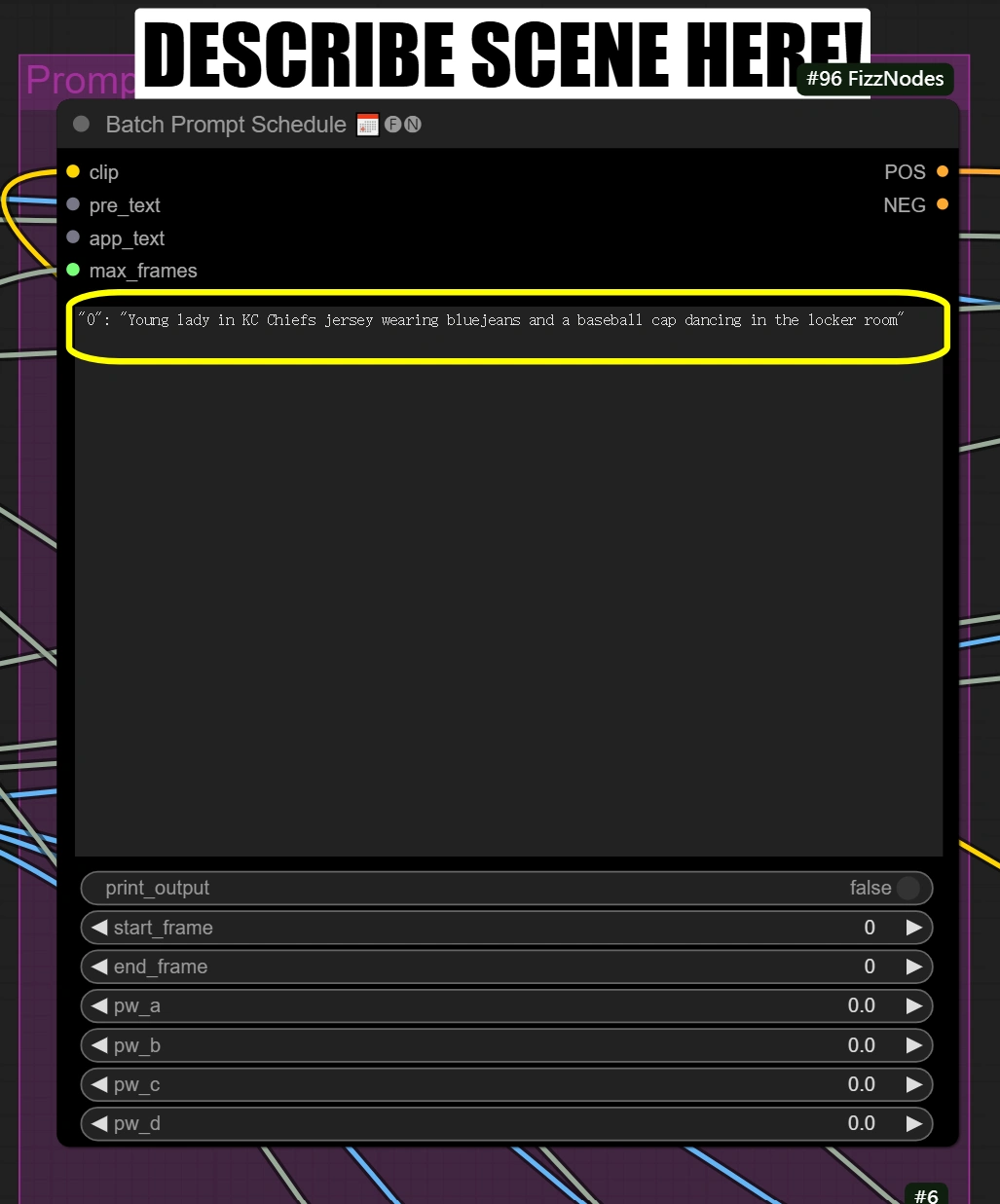
배치 프롬프트 스케줄:
- 변환하고자 하는 장면 및 기타 측면을 간단히 설명합니다
"0": "[person] in KC Chiefs jersey wearing bluejeans and a baseball cap dancing in the locker room"
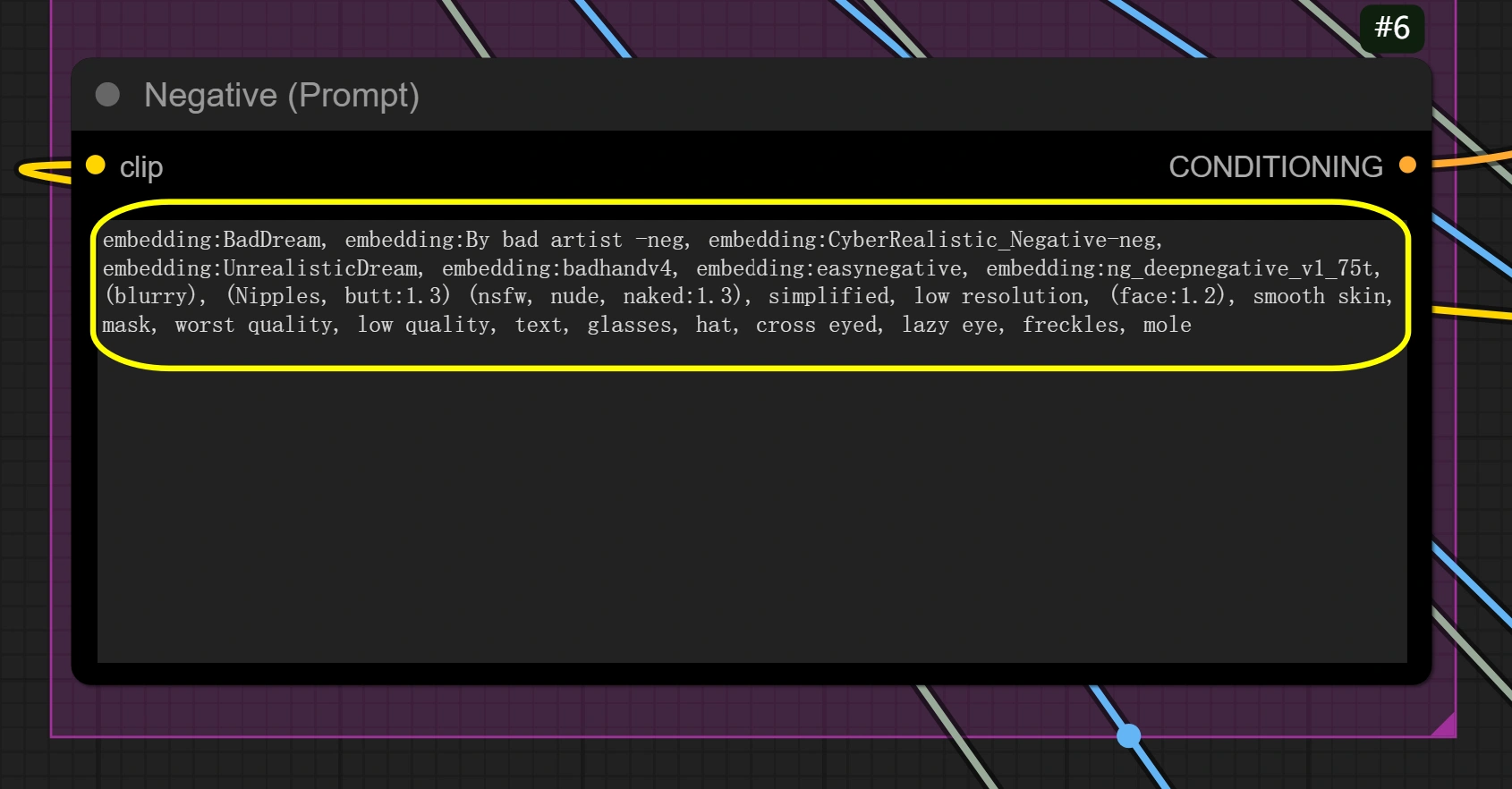
- 필요한 경우 부정적 프롬프트 설정
2단계: 빠른 테스트 실행
- "Queue Prompt" 클릭
- 약 2초 분량의 비디오를 처리합니다
- 두 가지 출력을 확인할 수 있습니다:
- 첫 번째 출력: 장면 변환만
- 두 번째 출력: 얼굴 교체 적용

3단계: 전체 비디오 처리
빠른 테스트가 잘 진행된 경우에만:
- "비디오 로드" 노드로 돌아갑니다
- 전체 비디오를 위해 프레임 로드 제한을 0으로 변경
- "Queue Prompt" 클릭하여 전체 처리 수행 (상당히 오래 걸릴 수 있음)
초보자를 위한 팁
- 노트를 따르세요: 인터페이스의 노트를 찾아보세요. 단계별로 안내합니다
- 고급 설정에 대해 걱정하지 마세요: 여기 언급된 것 외에는 대부분 조정할 필요가 없습니다
- 화면 비율의 중요성: 화면 비율이 정확해야 비디오가 왜곡되거나 잘리지 않습니다
주요 노드 참조
AnimateDiff 설정
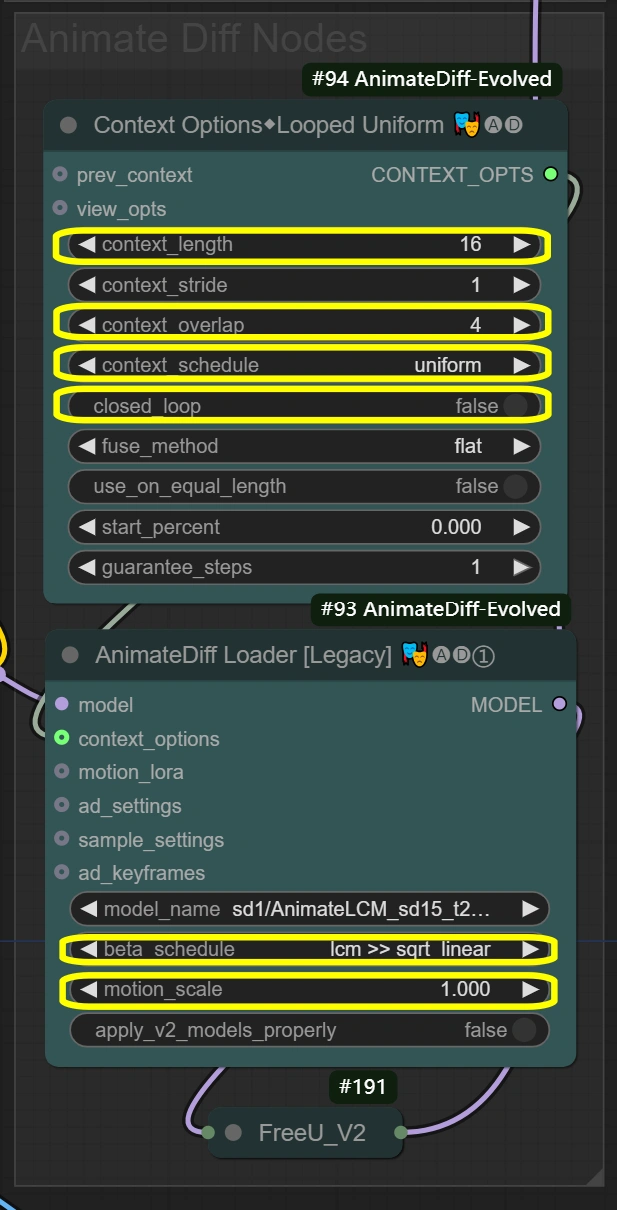
여기 노드들은 비디오 변환 내내 부드러운 움직임 보존을 만듭니다. 컨텍스트 옵션은 프레임이 그룹화되고 처리되는 방식을 정의하며, AnimateDiff Loader에 이 설정을 전달하여 실제 움직임 보존을 적용합니다. 컨텍스트 길이와 중첩 설정은 AnimateDiff Loader가 움직임의 일관성을 유지하는 방식에 직접 영향을 미칩니다.
- 컨텍스트 옵션 노드 (#94): 일관된 움직임을 위해 프레임 그룹화 및 시간 처리 제어를 달성합니다.
- context_length:
- 함께 처리할 프레임 수를 제어합니다
- 높을수록 더 부드럽지만 VRAM 사용 증가
- 낮을수록 더 빠르지만 움직임 일관성 상실 가능
- context_overlap:
- 프레임 전환 부드러움을 처리합니다
- 높을수록 블렌딩이 더 잘되지만 처리 속도 느려짐
- 낮을수록 빠르지만 전환 간격이 보일 수 있음
- context_schedule:
- 프레임 분배를 제어합니다
- "uniform"은 댄스 동작에 가장 적합
- 특정 필요가 없으면 변경하지 마세요
- closed_loop:
- 비디오 루프 동작을 제어합니다
- 완벽하게 반복되는 비디오에만 True
- context_length:
- AnimateDiff Loader 노드 (#93): AnimateDiff 모델을 사용하여 움직임 보존을 구현하고 시간적 일관성을 적용합니다.
- motion_scale:
- 움직임 강도를 제어합니다
- 높을수록 과장된 움직임
- 낮을수록 억제된 움직임
- beta_schedule: lcm >> sqrt_linear
- 샘플링 동작을 제어합니다
- 이 워크플로우에 최적화
- 필요하지 않으면 수정하지 마세요
- motion_scale:
ControlNet 스택
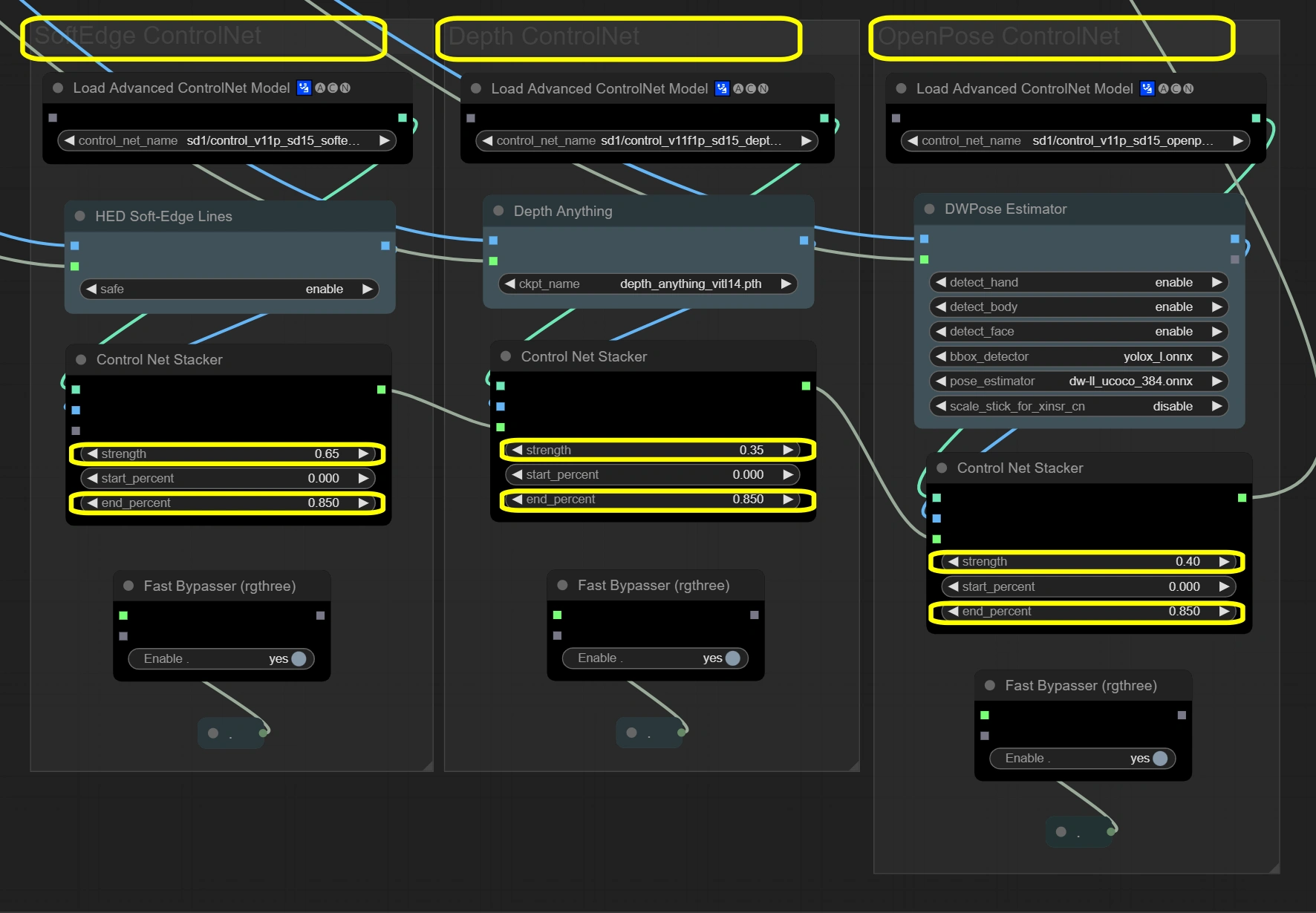
여기 노드는 세 층의 지침 시스템을 통해 비디오의 무결성을 유지합니다. 세 개의 ControlNets는 입력 프레임을 동시에 처리하여 각각 다른 측면에 집중합니다. Soft Edge는 기본 구조를 제공하고, Depth는 공간 이해를 추가하며, OpenPose는 움직임 정확성을 보장합니다. 결과는 스태커를 통해 결합되며, 전체 강도는 안정성을 위해 1.4를 초과하지 않습니다.
- Soft Edge ControlNet: 원본 프레임에서 구조적 요소와 모양을 추출하고 보존합니다.
- Strength:
- 구조적 보존을 제어합니다
- 높을수록 원본 모양에 더 강하게 고정
- 낮을수록 모양 수정에 더 많은 창의적 자유
- End percent:
- 제어 영향이 중지되는 시점
- 높을수록 프로세스 전반에 걸쳐 더 긴 영향
- 낮을수록 후반 단계에서 더 많은 편차 허용
- Strength:
- Depth ControlNet: 공간 관계를 처리하고 3D 일관성을 유지합니다.
- Strength:
- 공간 인식을 제어합니다
- 높을수록 강한 3D 일관성
- 낮을수록 공간에 대한 예술적 자유 증가
- End percent:
- 깊이 영향 지속 시간을 유지합니다
- 일관성을 위해 Soft Edge와 일치해야 합니다
- Strength:
- OpenPose ControlNet: 정확한 움직임을 위한 포즈 정보를 캡처하고 전송합니다.
- Strength:
- 포즈 보존을 제어합니다
- 높을수록 더 엄격한 포즈 추적
- 낮을수록 포즈 해석이 더 유연함
- End percent:
- 포즈 영향을 유지합니다
- 과정 내내 자연스러운 움직임을 유지
- Strength:
얼굴 처리
여기 노드는 자연스러운 결과를 위해 얼굴 교체 및 향상을 처리합니다. 이 과정은 두 단계로 작동합니다: FaceRestore는 먼저 원본 얼굴 품질을 향상시키고, ReActor는 향상된 얼굴을 참조로 사용하여 교체를 수행합니다. 이 두 단계 프로세스는 표현을 보존하면서 자연스러운 통합을 보장합니다.
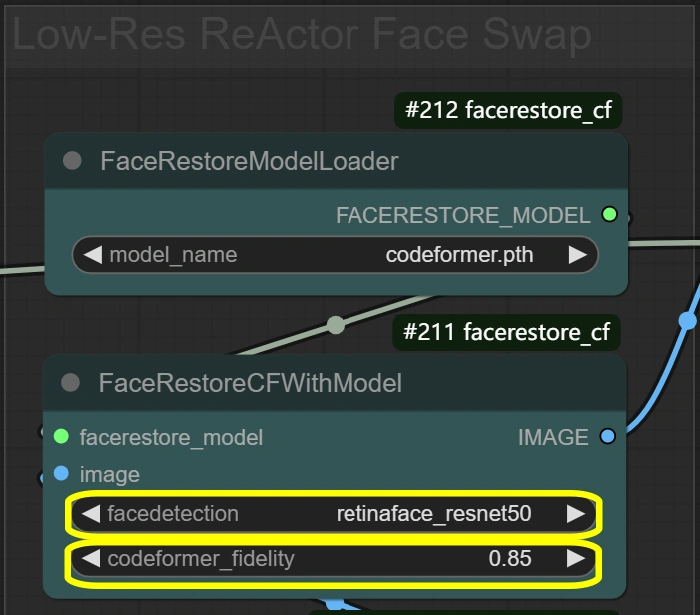
- FaceRestore 시스템: 얼굴 세부 정보를 향상시키고 교체를 준비합니다.
- Fidelity:
- 복원에서 세부 정보 보존을 제어합니다
- 높을수록 더 자세한 정보가 있지만 잠재적인 아티팩트 발생
- 낮을수록 매끄럽지만 세부 정보 손실 가능
- Detection:
- 얼굴 감지 모델 선택
- 대부분의 시나리오에서 신뢰할 수 있음
- 얼굴이 감지되지 않는 경우에만 변경
- Fidelity:
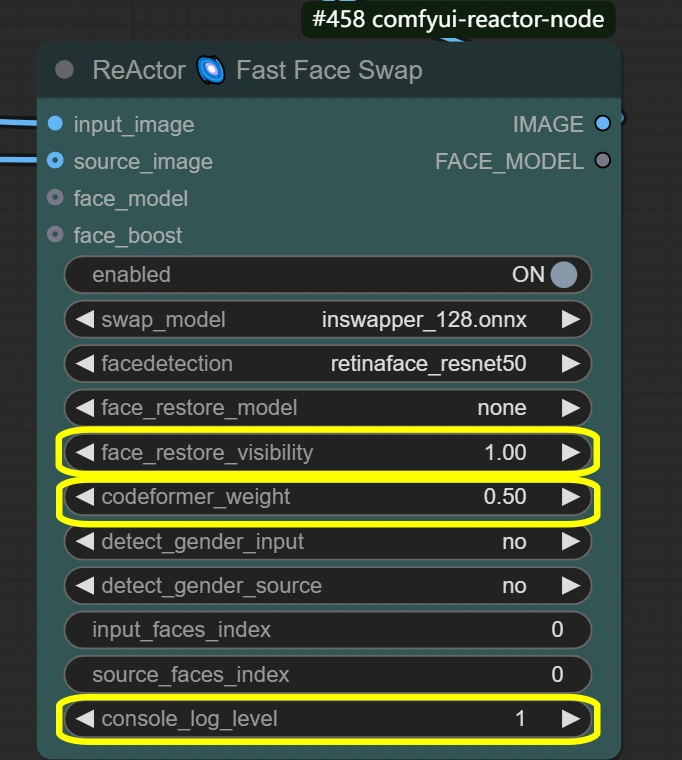
- ReActor 얼굴 교체: 보존된 표현으로 얼굴 교체 및 블렌딩을 수행합니다.
- Visibility:
- 교체 가시성을 제어합니다
- 높을수록 얼굴 교체 효과가 더 강함
- 낮을수록 더 미묘한 블렌딩
- Weight:
- 얼굴 특징 보존 균형
- 높을수록 소스 얼굴 특징 강함
- 낮을수록 타겟과의 더 나은 블렌딩
- Console log level:
- 디버깅 정보 제어
- 높을수록 더 자세한 로그
- Visibility:
추가 노드 세부 정보
입력 및 전처리
목적: 비디오를 로드하고, 치수를 조정하고, VAE 모델을 처리 준비합니다.
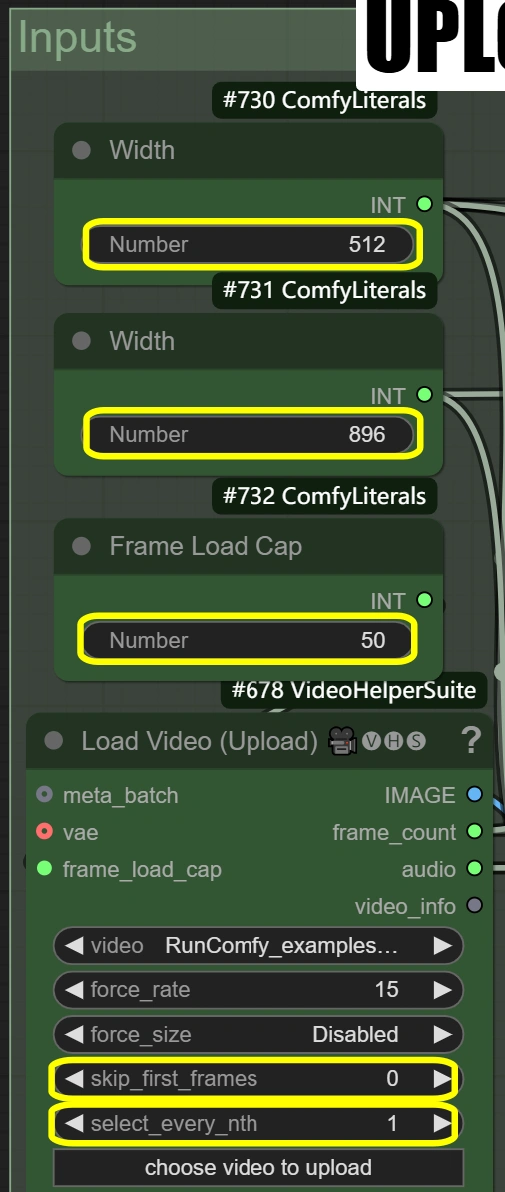
- 비디오 로드:
- 프레임 로드 제한:
- 처리할 프레임 수를 제어합니다
- 50 = 빠른 테스트 (~2초 처리)
- 0 = 전체 비디오 처리
- 총 처리 시간에 영향을 미침
- 처음 프레임 건너뛰기:
- 비디오 시작 지점 정의
- 높을수록 비디오 후반부에서 시작
- 인트로 건너뛰기에 유용
- 매 N번째 선택:
- 프레임 샘플링 비율을 제어합니다
- 숫자가 높을수록 프레임 건너뛰기
- 1 = 모든 프레임 사용
- 2 = 매 두 번째 프레임 사용 등
- 프레임 로드 제한:
- 이미지 스케일:
- 너비: 512
- 출력 프레임 너비를 제어합니다
- 높이와 9:16 비율을 유지해야 함
- 높이: 896
- 출력 프레임 높이를 제어합니다
- 너비와 9:16 비율을 유지해야 함
- 방법: nearest-exact
- 선명도를 유지하는 데 가장 좋음
- 대안은 콘텐츠를 흐리게 할 수 있음
- 댄스 비디오에 권장
- 특정 필요가 없는 한 변경하지 마세요
- 너비: 512
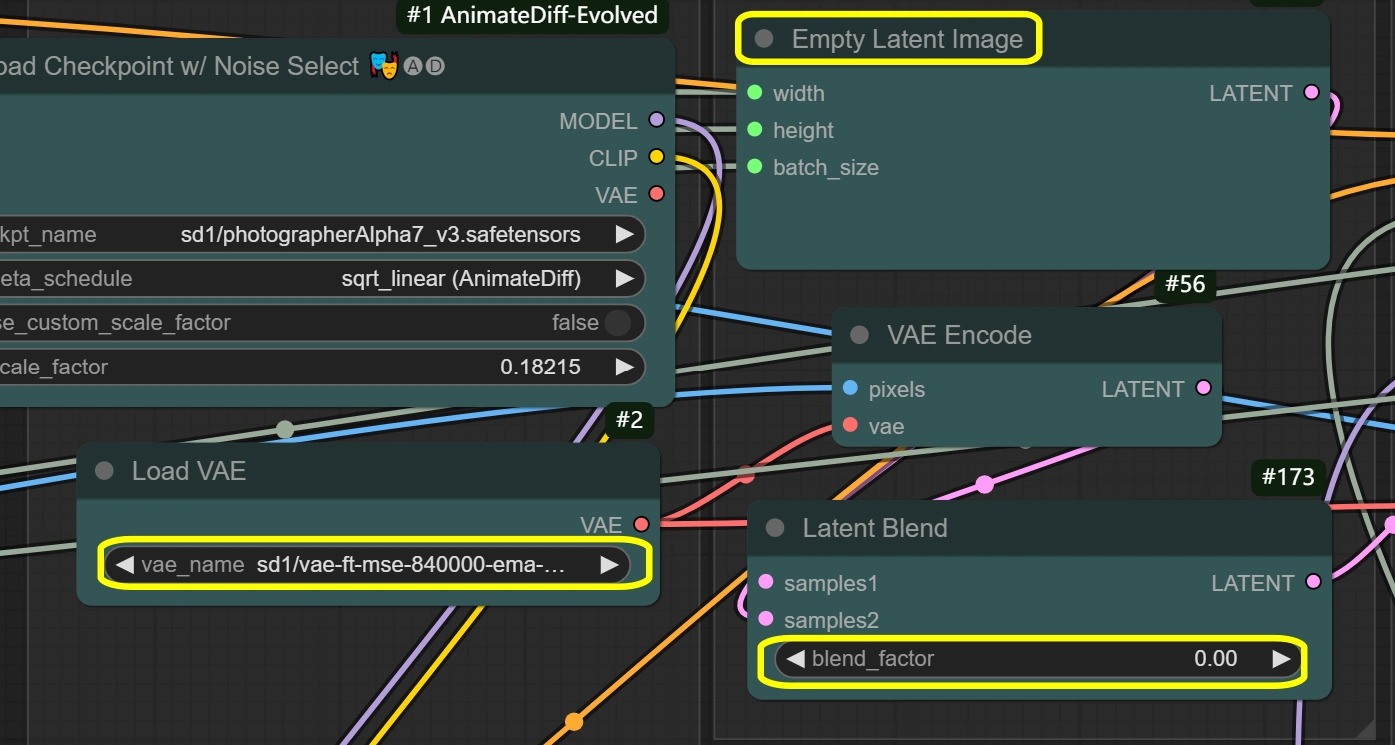
- VAE 로더:
- 모델: vae-ft-mse-840000-ema-pruned
- 안정성과 품질에 최적화
- 이미지 인코딩/디코딩 처리
- 균형 잡힌 압축 비율
- 특정 필요가 없는 한 변경하지 마세요
- VAE 모드: 변경하지 마세요
- 현재 워크플로우에 최적화
- 인코딩 품질에 영향
- 모델: vae-ft-mse-840000-ema-pruned
잠재 처리
목적: 모든 잠재 공간 작업 및 변환을 처리합니다.
- 빈 잠재 이미지:
- 너비/높이: 입력과 일치
- 이미지 스케일 치수와 일치해야 함
- 메모리 사용에 직접 영향을 미침
- 더 큰 크기는 더 많은 VRAM 필요
- 입력보다 작을 수 없음
- 배치 크기: 비디오 프레임에서
- 프레임 수에서 자동 설정
- 처리 속도 및 VRAM에 영향
- 높을수록 더 많은 메모리 필요
- 너비/높이: 입력과 일치
- VAE 인코딩:
- VAE 모델: VAE 로더에서
- VAE 로더 설정 사용
- 일관성 유지
- 디코드: 활성화
- 디코딩 품질 제어
- VRAM 제한이 있는 경우에만 비활성화
- 출력 품질에 영향
- VAE 모델: VAE 로더에서
- 잠재 블렌드:
- 블렌드 팩터:
- 잠재 공간 혼합을 제어합니다
- 0 = 전체 소스 콘텐츠
- 높을수록 빈 잠재 영향 증가
- 스타일 전환 강도에 영향
- 블렌드 팩터:
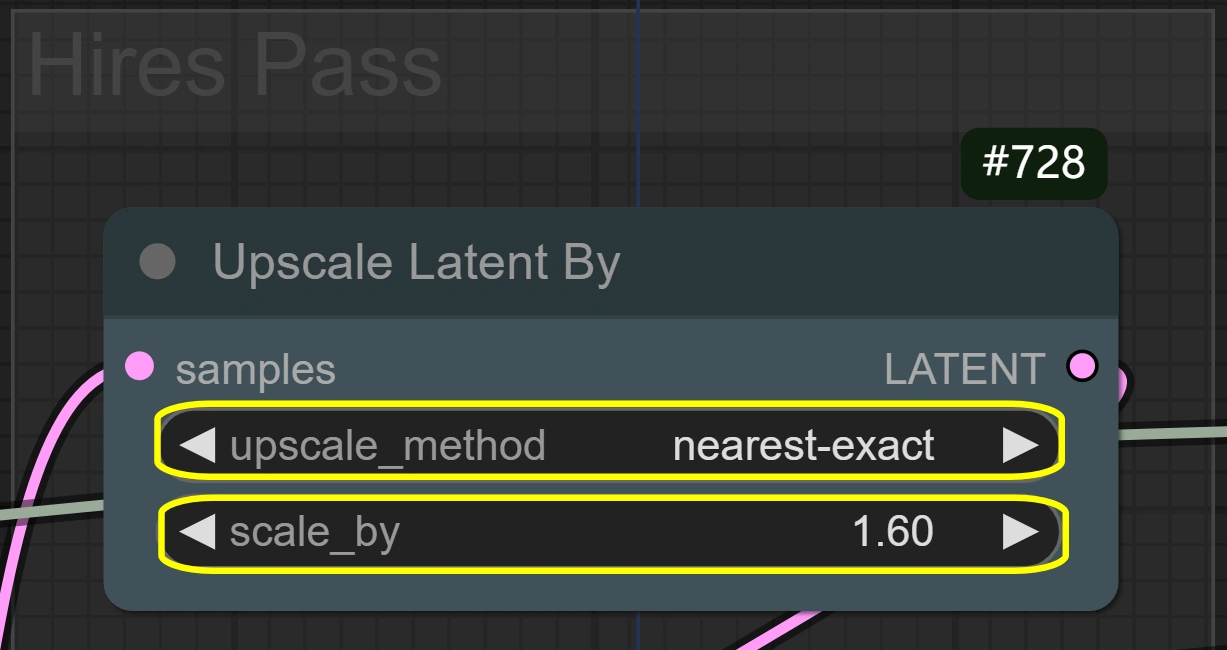
- 잠재 업스케일:
- 방법: nearest-exact
- 선명도를 유지하는 데 가장 좋음
- 대안은 흐려질 수 있음
- 움직임 세부 사항 보존
- 스케일:
- 크기 증가 제어
- 높을수록 더 나은 세부 사항, 더 많은 VRAM 필요
- 낮을수록 더 빠른 처리
- 대부분의 경우에 1.6 최적
- 방법: nearest-exact
샘플링 및 정제
목적: 품질 변환을 위한 두 단계의 샘플링 프로세스.
- KSampler (첫 번째 패스):
- 단계:
- 디노이징 단계 수
- 높을수록 품질이 좋지만 속도가 느림
- lcm 샘플러에 6 최적
- CFG:
- 프롬프트 영향을 제어합니다
- 높을수록 스타일 고정 강함
- 낮을수록 자유로움 증가
- 샘플러: lcm
- 속도에 최적화
- 품질/속도 균형이 좋음
- 스케줄러: sgm_uniform
- lcm과 가장 잘 작동
- 시간적 일관성 유지
- 디노이즈:
- 첫 번째 패스에 대한 전체 강도
- 변환 강도를 제어합니다
- 단계:
- KSampler (고해상도 패스):
- 단계:
- 일관성을 위해 첫 번째 패스와 일치
- 정제에 더 높을 필요 없음
- CFG:
- 스타일 일관성 유지
- 세부 정보 보존 균형
- 샘플러: lcm
- 첫 번째 패스와 동일
- 일관성 유지
- 스케줄러: sgm_uniform
- 첫 번째 패스와 일관json
- 일관성을 유지하며 세부 사항을 정제하는 데 좋음
- 디노이즈:
- 첫 번째 패스보다 낮음
- 원본 세부 사항을 더 많이 보존
- 정제를 위한 좋은 균형
- 단계:
출력 처리
목적: 얼굴 교체가 포함된 최종 비디오 출력 생성.
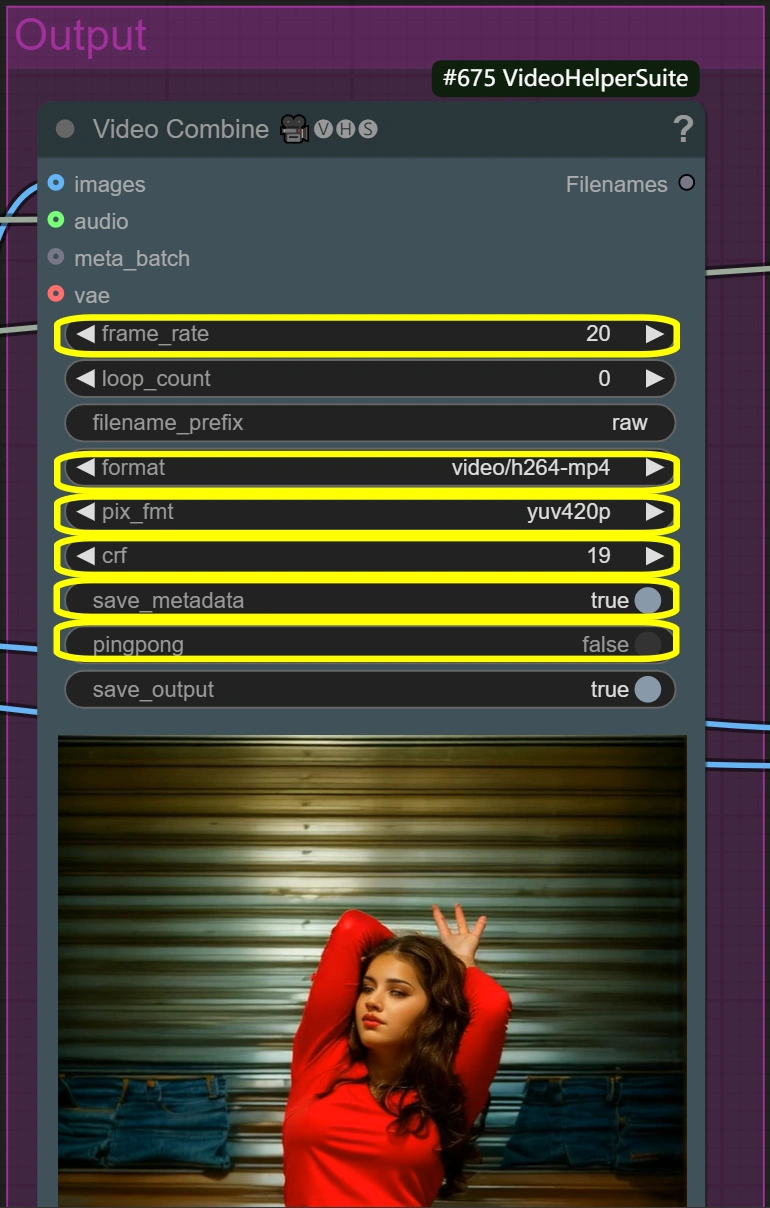
- 비디오 결합 (원본):
- 프레임 속도:
- 표준 비디오 프레임 속도
- 재생 속도를 제어합니다
- 낮을수록 파일 크기 작아짐
- 높을수록 움직임 부드러워짐
- 형식: video/h264-mp4
- 호환성을 위한 표준 형식
- 품질/크기 균형이 좋음
- 널리 지원됨
- CRF:
- 압축 품질을 제어합니다
- 낮을수록 품질이 좋지만 파일이 커짐
- 높을수록 파일이 작지만 품질이 낮음
- 19는 고품질 설정
- 픽셀 형식: yuv420p
- 호환성을 위한 표준 형식
- 필요하지 않으면 변경하지 마세요
- 널리 재생 지원 보장
- 프레임 속도:
- 비디오 결합 (얼굴 교체):
- 원본 출력과 동일한 매개변수
- 일관성을 위해 동일한 설정 사용
- 얼굴 교체 통합 추가
- 비디오 품질 설정 유지
최적화 팁
품질 대 속도 트레이드오프
- 해상도 균형:
- 표준: 512x896
- 더 빠른 처리
- 대부분의 사용에 적합
- 고품질: 768x1344
- 더 나은 세부 사항
- 2-3배 긴 처리 시간
- 표준: 512x896
- 얼굴 교체 품질:
- 표준: 기본 설정
- 자연스러운 통합
- 균형 잡힌 처리 시간
- 최대 품질:
- codeformer_fidelity를 0.9로 증가
- 느리지만 더 자세한 얼굴
- 표준: 기본 설정
- 움직임 부드러움:
- 더 빠른 처리:
- context_overlap을 2로 줄임
- 전환이 조금 덜 부드러움
- 더 나은 움직임:
- 중첩을 6으로 증가
- 더 많은 VRAM 사용, 느린 처리
- 더 빠른 처리:
일반 문제 및 해결책
- 얼굴 블렌딩:
- 문제: 부자연스러운 얼굴 전환
- 해결책: codeformer_weight 조정
- 0.4-0.7 범위 시도
- 낮을수록 더 나은 블렌딩
- 높을수록 얼굴 세부 사항 증가
- 스타일 강도:
- 문제: 약한 스타일 전환
- 해결책: cfg 증가
- 7-8 범위 시도
- 높을수록 강한 스타일
- 움직임 품질에 영향을 줄 수 있음
- 메모리 관리:
- 문제: VRAM 제한
- 해결책:
- VAE 슬라이싱 활성화
- 해상도 감소
- 더 짧은 세그먼트 처리
추가 정보
추가 세부 정보와 놀라운 창작물을 보려면 을 방문하세요.


