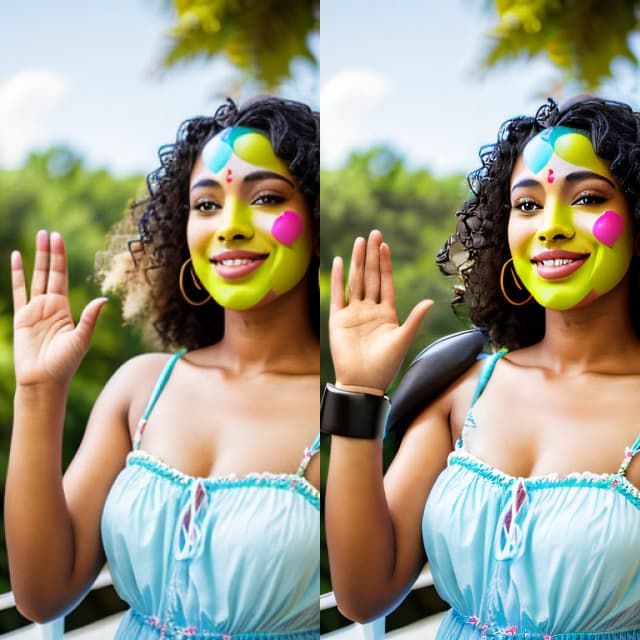音频反应遮罩扩展 | 惊艳动画
这个 ComfyUI 音频反应遮罩扩展工作流程使您能够创造性地改变视频中的主题。无论是个人还是团体表演者,它都能使您的主题包裹在一个动态且响应的光环中,光环会根据音乐的节奏完美同步地扩展和收缩。这个效果为您的视频增加了一个引人入胜的视觉维度,增强了它们的整体影响力和参与度。ComfyUI Audioreactive Mask Dilation 工作流程

想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Audioreactive Mask Dilation 示例
ComfyUI Audioreactive Mask Dilation 描述
通过赋予您的主题(例如舞者)一个随节奏同步扩展和收缩的动态光环,创建惊艳的视频动画。使用这个工作流程可以处理单个或多个主题,如示例中所见。
如何使用音频反应遮罩扩展工作流程:
- 在输入部分上传一个主题视频
- 选择最终视频的所需宽度和高度,以及输入视频中应跳过的帧数使用 'every_nth'。您还可以使用 'frame_load_cap' 限制要渲染的总帧数。
- 填写正面和负面提示。设置批量帧时间以匹配您希望场景转换发生的时间。
- 为每个默认的 IP 适配器主题遮罩颜色上传图像:
- 红色 = 主题(舞者)
- 黑色 = 背景
- 白色 = 白色音频反应扩展遮罩
- 在 'Models' 部分加载一个好的 LCM 检查点(我使用 Machine Delusions 的 ParadigmLCM)。
- 使用模型加载器下方的 Lora 堆叠器添加任何 loras
- 点击队列提示
输入
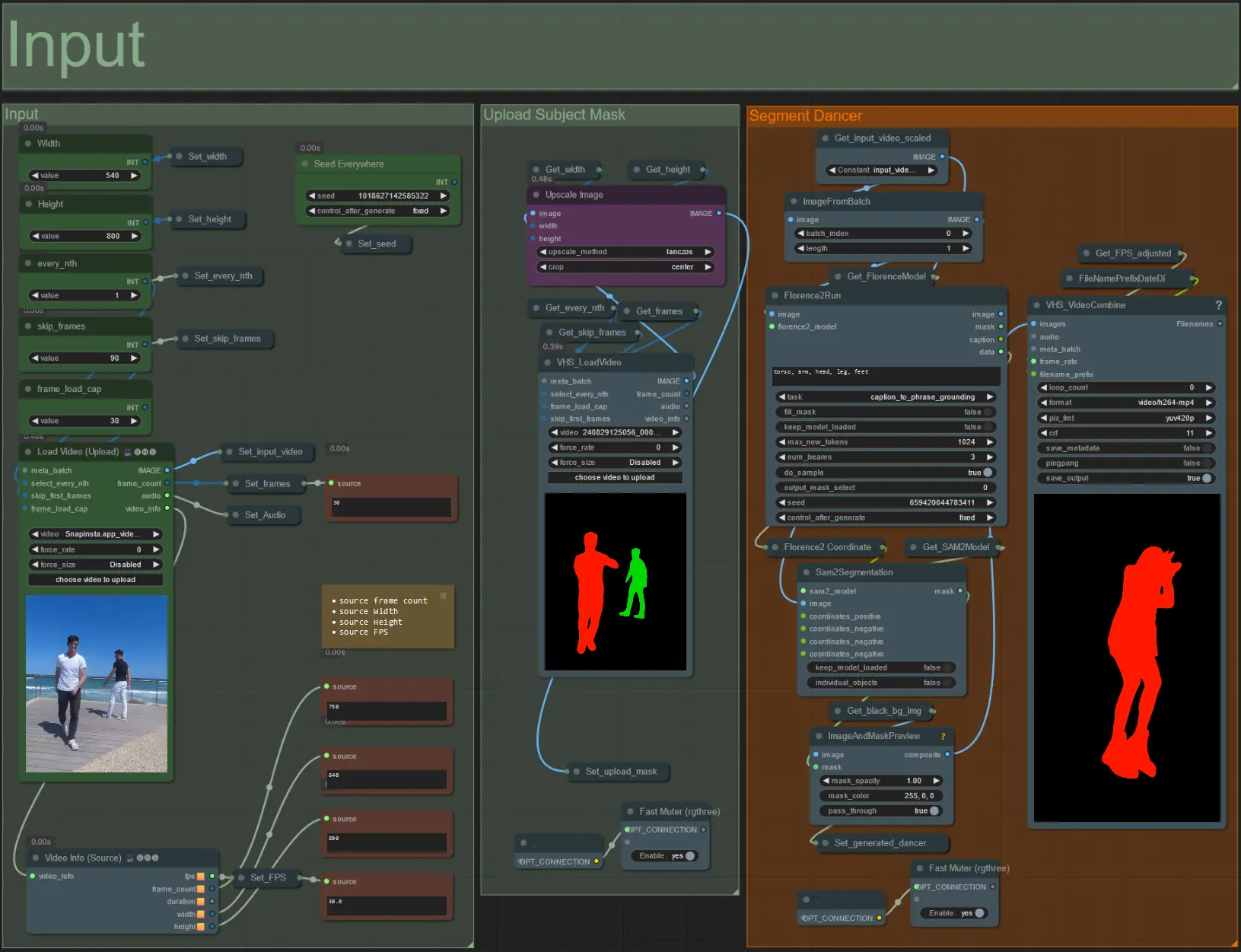
- 将您想要的主题视频上传到加载视频(上传)节点。
- 使用左上角的两个输入调整输出宽度和高度。
- every_nth 设置是否使用每隔一帧、每隔三帧等(2 = 每隔一帧)。默认设置为 1。
- skip_frames 用于跳过视频开头的帧。(100 = 跳过输入视频的前 100 帧)。默认设置为 0。
- frame_load_cap 用于指定应加载的输入视频的总帧数。测试设置时最好保持较低(例如 30 - 60),然后在渲染最终视频时增加或设置为 0(无帧数上限)。
- 右下角的数字字段显示有关上传的输入视频的信息:总帧数、宽度、高度和 FPS,从上到下。
- 如果您已经生成了主题的遮罩视频,请取消静音 'Upload Subject Mask' 部分并上传遮罩视频。可选地静音 'Segment Dancer' 部分以节省一些处理时间。
- 有时分割的主题可能不完美,请使用右下角的预览框检查遮罩质量。如有必要,可以在 'Florence2Run' 节点中调整提示以定位不同的身体部位,如 'head'、'chest'、'legs' 等,看看是否能获得更好的结果。
提示
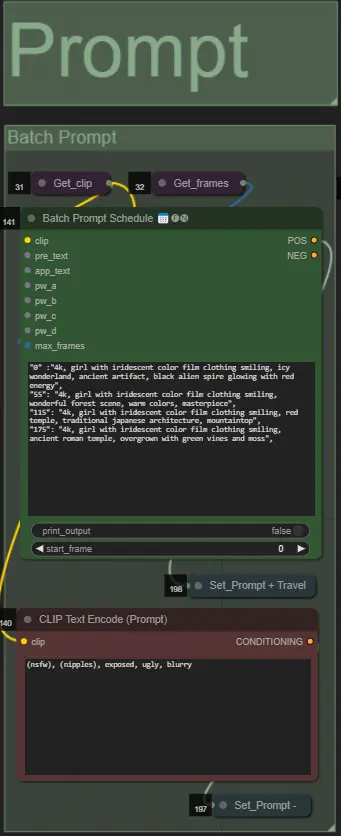
- 使用批量格式设置正面提示:
- 例如 '0': '4k, masterpiece, 1girl standing on the beach, absurdres', '25': 'HDR, sunset scene, 1girl with black hair and a white jacket, absurdres', …
- 负面提示是正常格式,如有需要可添加嵌入。
音频处理
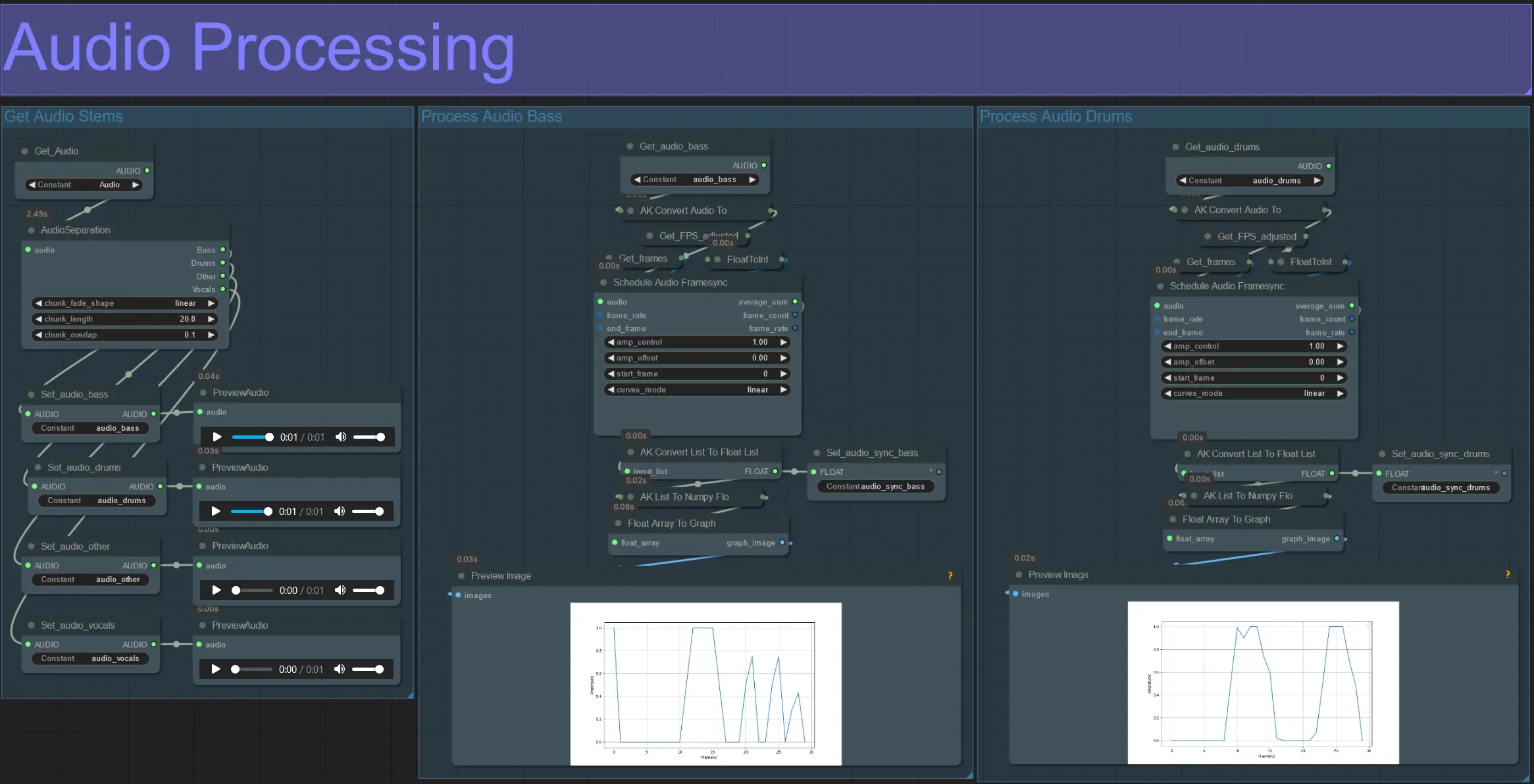
- 该部分从输入视频中提取音频,提取干音(低音、鼓声、主唱等),然后将其转换为与输入视频帧同步的标准化振幅。
- amp_control = 振幅可以变化的总范围。
- amp_offset = 振幅可以达到的最小值。
- 例如:amp_control = 0.8 和 amp_offset = 0.2 意味着信号将在 0.2 和 1.0 之间变化。
- 有时鼓声干音包含了歌曲的实际低音音符;预览每个干音以确定哪个最适合您的遮罩。
- 使用图表清晰了解该干音在视频整个持续时间内的信号变化情况。
扩展遮罩
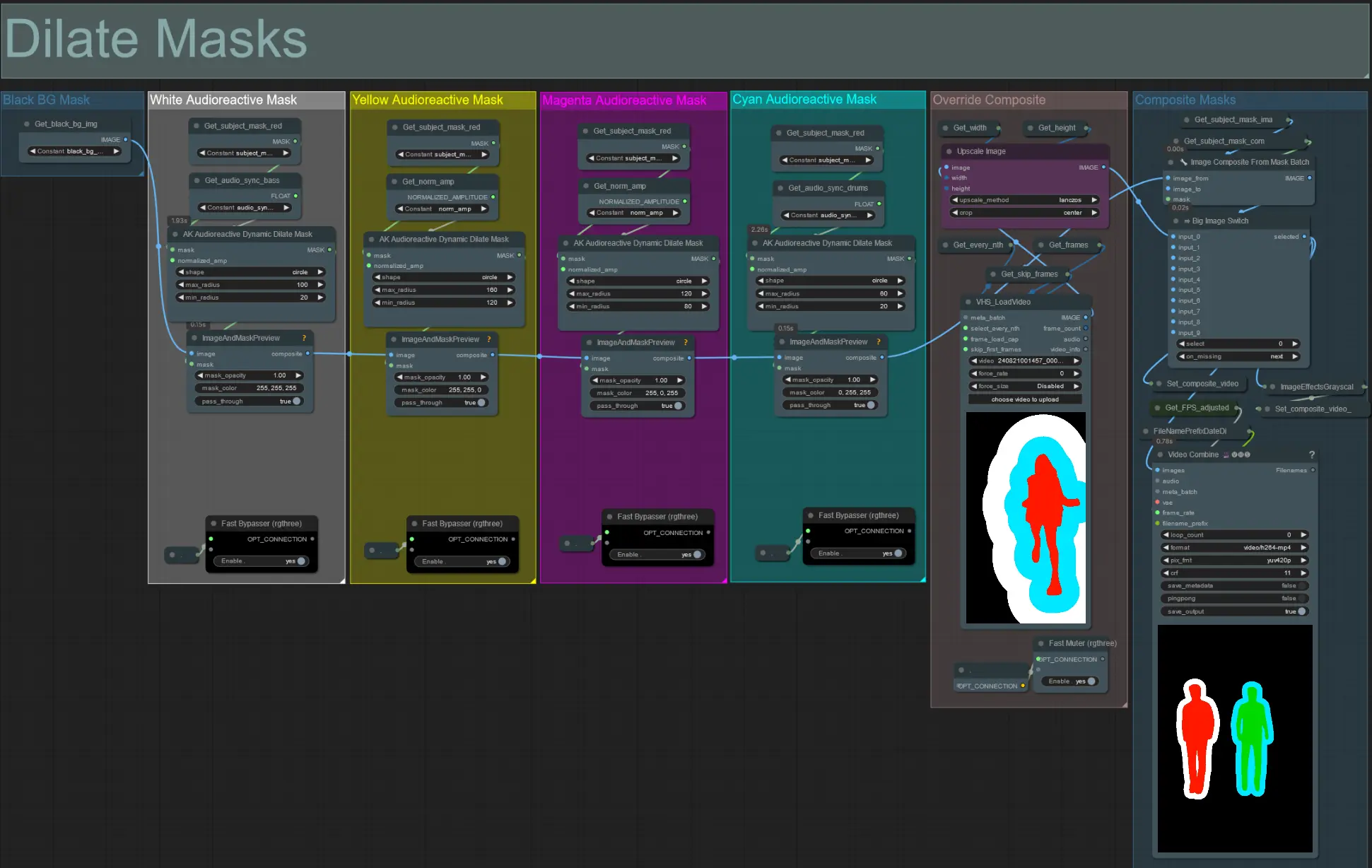
- 每个彩色组对应将由其生成的扩展遮罩的颜色。
- 使用以下节点设置扩展遮罩的最小和最大半径及其形状:
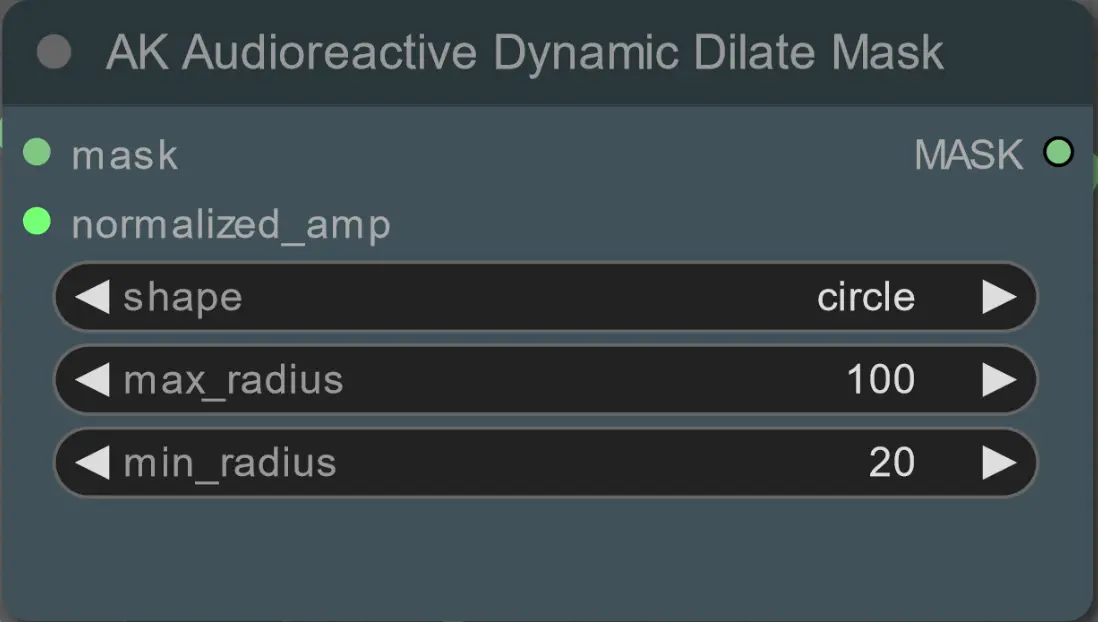
- 形状:'circle' 是最精确的,但生成时间较长。准备进行最终渲染时设置此项。'square' 计算速度快但不太精确,最适合测试工作流程和决定 IP 适配器图像。
- max_radius:振幅值为最大(1.0)时遮罩的半径(以像素为单位)。
- min_radius:振幅值为最小(0.0)时遮罩的半径(以像素为单位)。
- 如果您已经生成了复合遮罩视频,可以取消静音 'Override Composite Mask' 组并上传它。建议绕过扩展遮罩组以节省处理时间。
模型
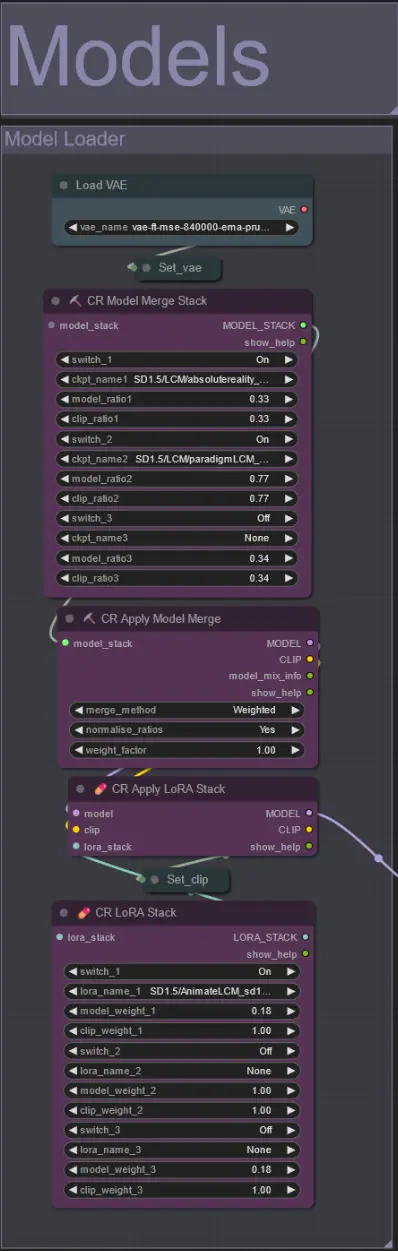
- 使用一个好的 LCM 模型作为检查点。我推荐 Machine Delusions 的 ParadigmLCM。
- 使用模型合并堆栈将多个模型合并在一起,以获得各种有趣的效果。确保启用的模型的权重总和为 1.0。
- 可选地指定 AnimateLCM_sd15_t2v_lora.safetensors,权重较低(0.18),以进一步增强最终效果。
- 使用模型加载器下方的 Lora 堆叠器添加任何额外的 Loras。
AnimateDiff

- 设置一个不同的 Motion Lora 而不是我使用的(LiquidAF-0-1.safetensors)
- 增加/减少 Scale 和 Effect 浮点数以增加/减少输出中的运动量。
IP 适配器
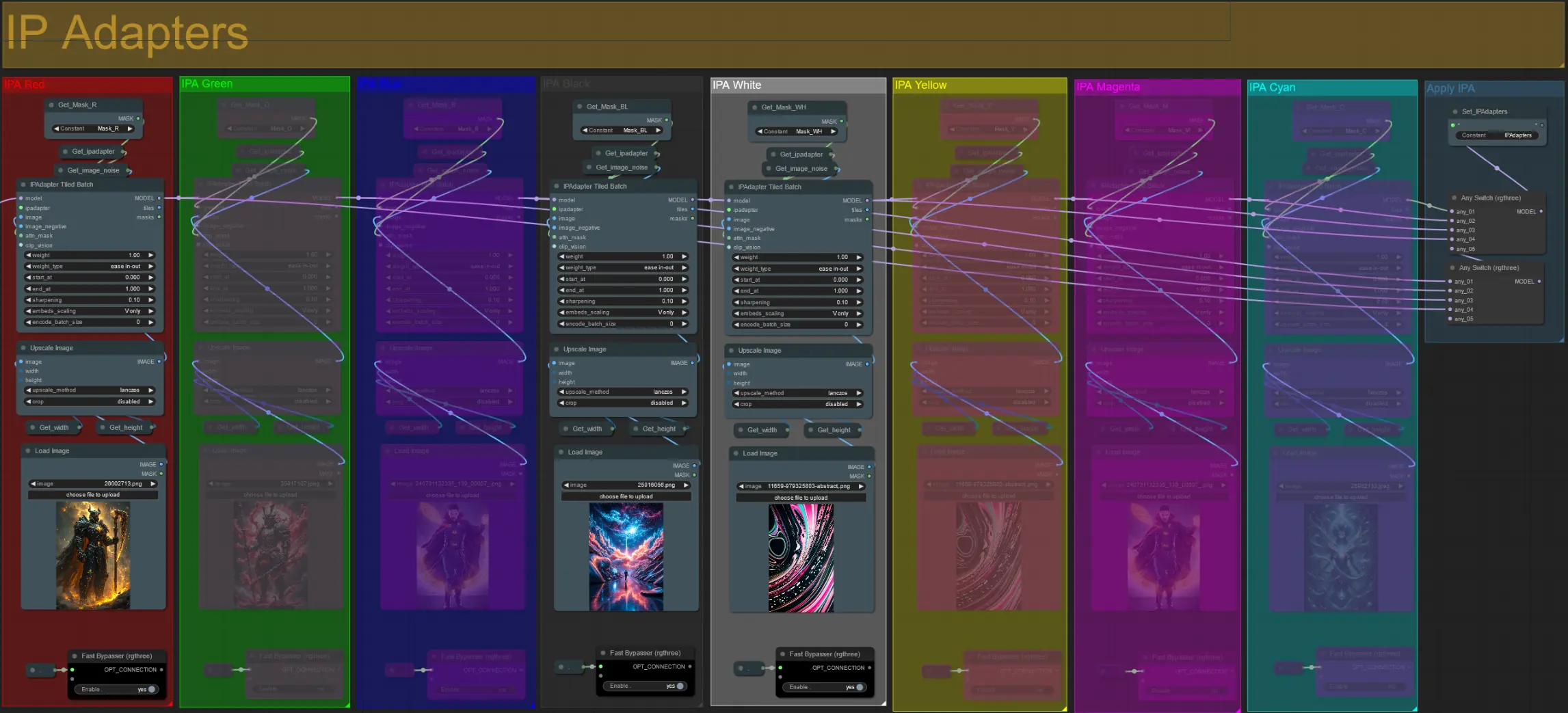
- 在这里,您可以指定用于渲染每个扩展遮罩背景以及视频主题的参考图像。
- 每组的颜色表示其目标的遮罩:
红色、绿色、蓝色:
- 主题遮罩参考图像。
黑色:
- 背景遮罩图像,上传背景的参考图像。
白色、黄色、洋红色、青色:
- 扩展遮罩参考图像,为使用的每种颜色扩展遮罩上传参考图像。
ControlNet
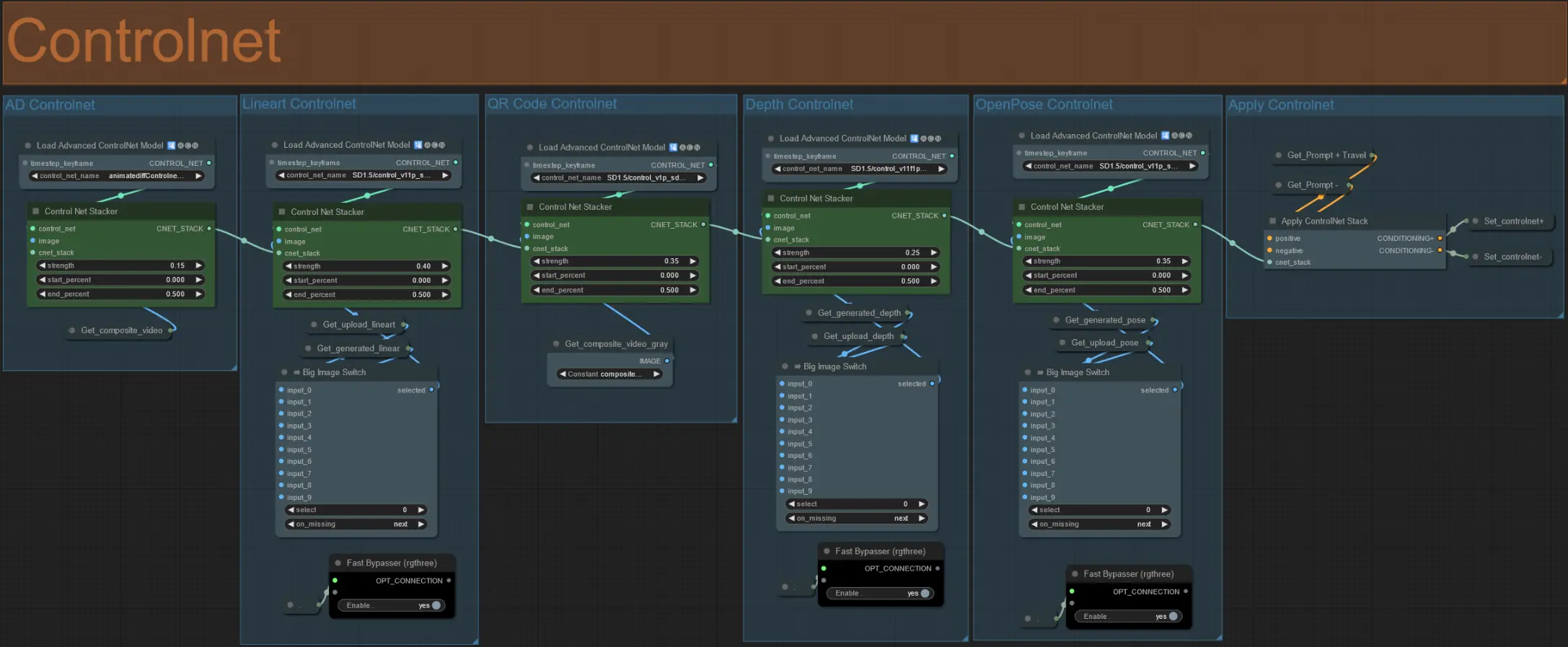
- 该工作流程使用了 5 个不同的 controlnets,包括 AD、Lineart、QR Code、Depth 和 OpenPose。
- 所有输入到 controlnets 的数据都是自动生成的
- 您可以选择取消静音 'Override ' 组来覆盖 Lineart、Depth 和 Openpose controlnets 的输入视频,如下所示:
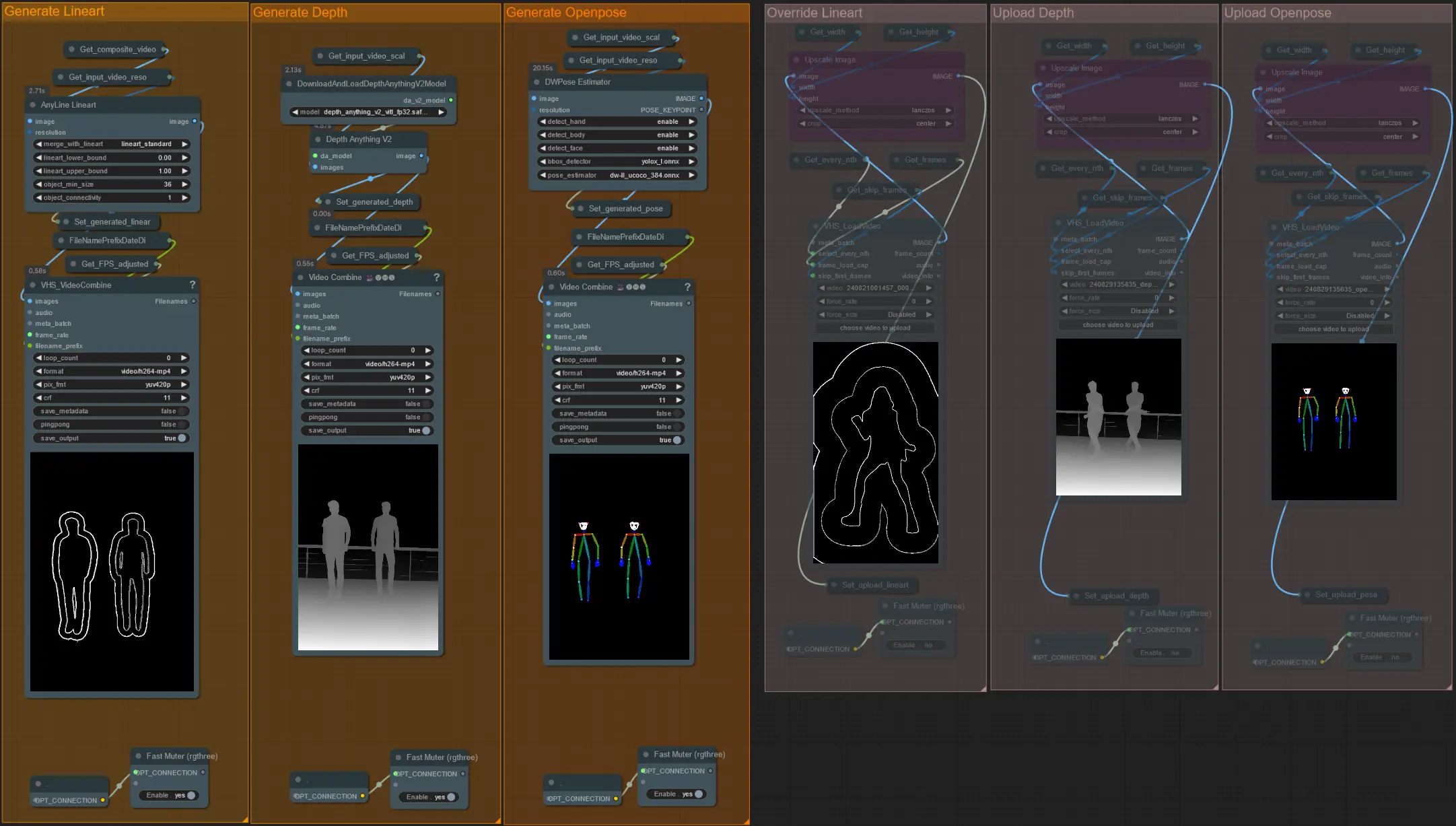
- 建议您在覆盖时也静音 'Generate' 组以节省处理时间。
提示:
- 绕过 Ksampler 并开始渲染您的完整输入视频。一旦所有预处理器视频生成完毕,保存它们并上传到相应的覆盖。之后在测试工作流程时,您将无需等待每个预处理器视频单独生成。
采样器
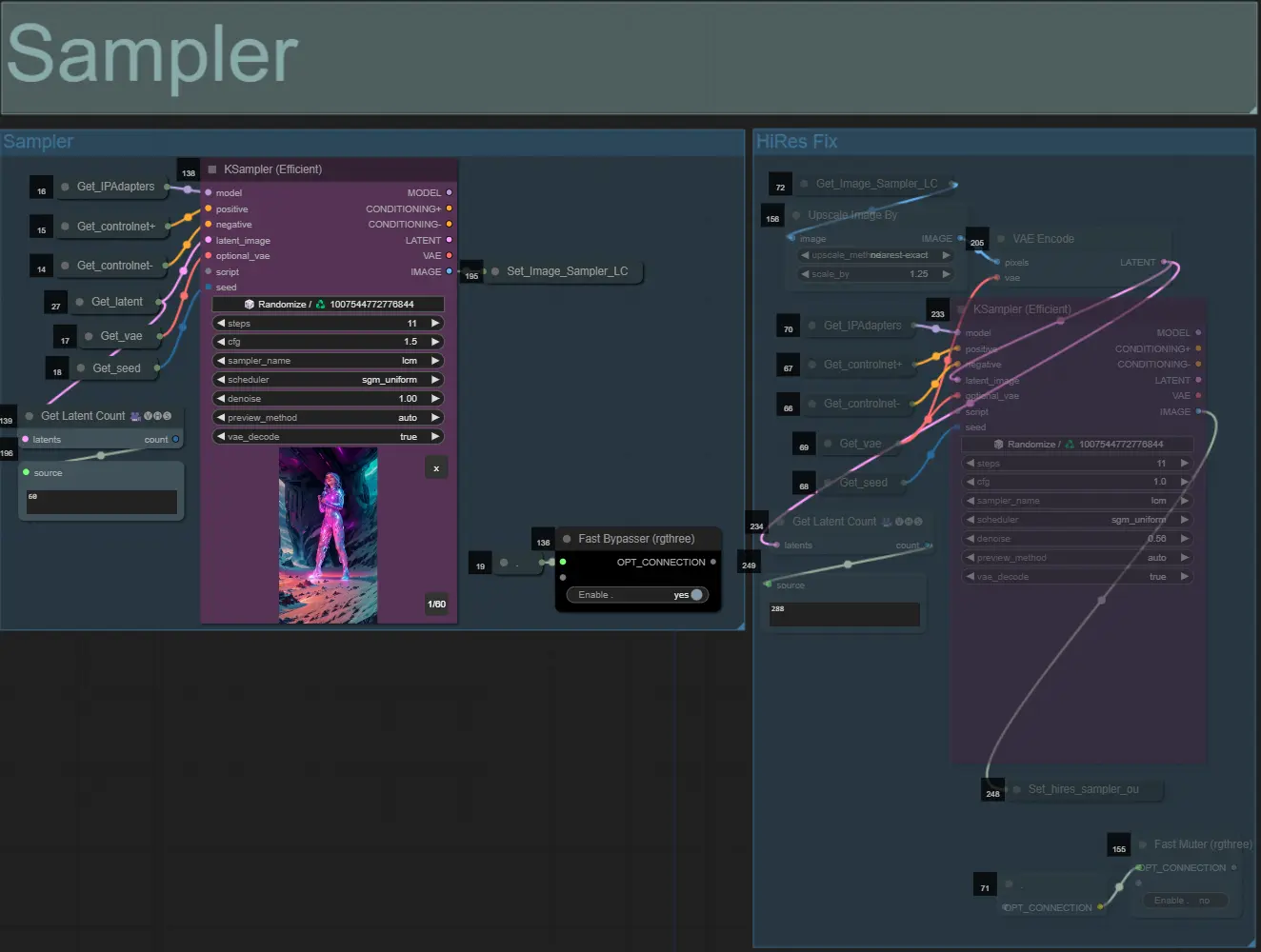
- 默认情况下,HiRes Fix 采样器组将静音以节省测试时的处理时间
- 我建议在尝试扩展遮罩设置时绕过采样器组以节省时间。
- 在最终渲染时,您可以取消静音 HiRes Fix 组,这将放大并为最终结果添加细节。
输出

- 有两个输出组:左侧是标准采样器输出,右侧是 HiRes Fix 采样器输出。
关于作者
Akatz AI:
- 网站:
- http://patreon.com/Akatz
- https://civitai.com/user/akatz
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
联系方式:
- 电子邮件:akatz.hello@gmail.com