AnimateDiff + ControlNet | 陶瓷艺术风格
ComfyUI中的这个工作流程利用AnimateDiff和ControlNet(着重于深度等方面),以及Lora等其他工具,巧妙地将视频转换为陶瓷艺术风格。它使原始内容呈现出独特的艺术风格,有效地将其提升到陶瓷艺术杰作的境界。ComfyUI Vid2Vid (Art) 工作流程
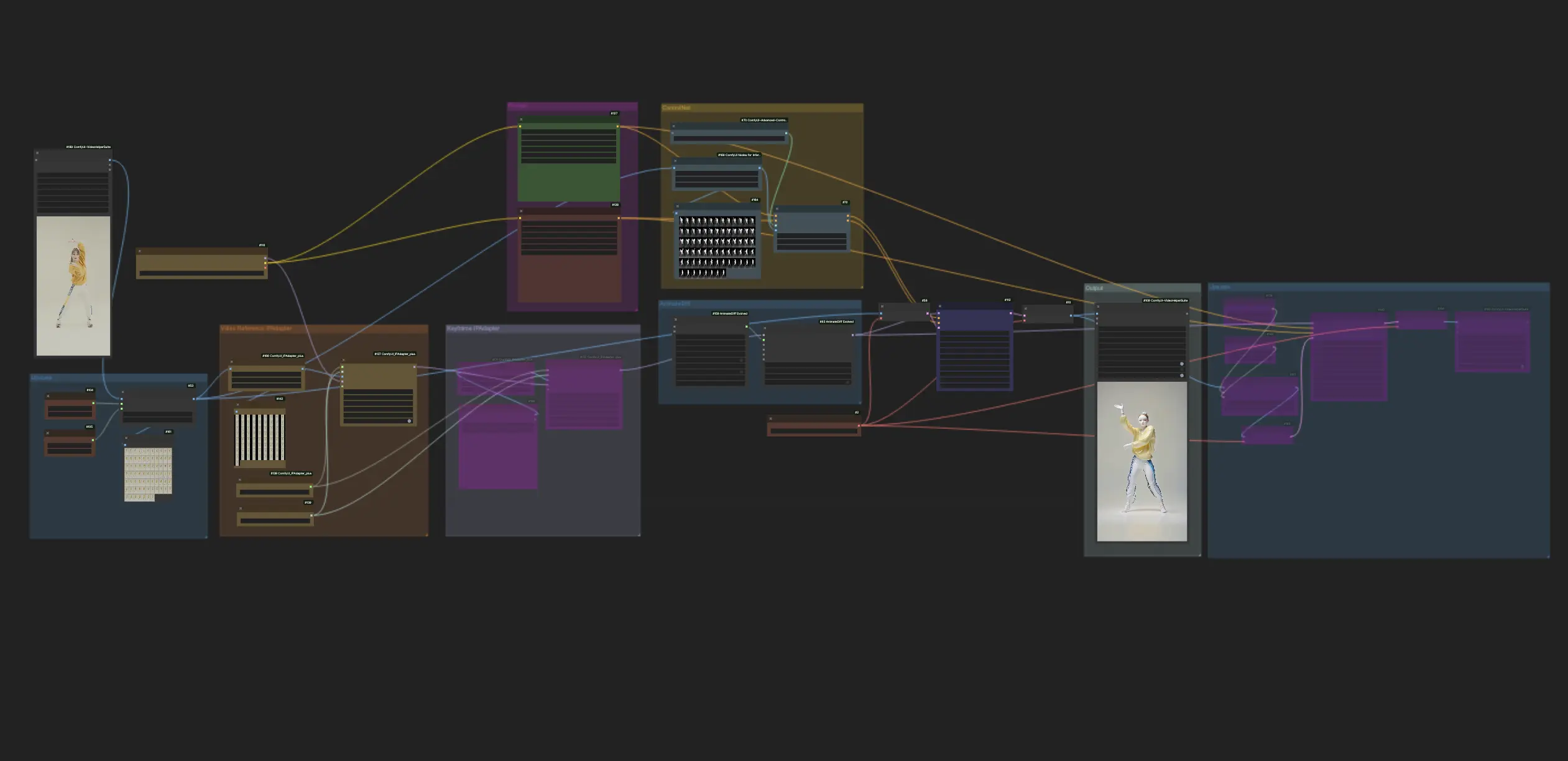
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Vid2Vid (Art) 示例
ComfyUI Vid2Vid (Art) 描述
1. ComfyUI工作流程:AnimateDiff + ControlNet | 陶瓷艺术风格
这个工作流程利用AnimateDiff、专注于深度的ControlNet和特定的Lora,巧妙地将视频转换为陶瓷艺术风格。我们鼓励您使用不同的提示来实现各种艺术风格,将您的创意变为现实。
2. 如何使用AnimateDiff
AnimateDiff旨在利用Stable Diffusion模型和专门的运动模块,将静态图像和文本提示转化为动态视频。它通过预测帧之间的无缝过渡来自动化动画过程,使没有编程技能的用户也能轻松使用。
2.1 AnimateDiff运动模块
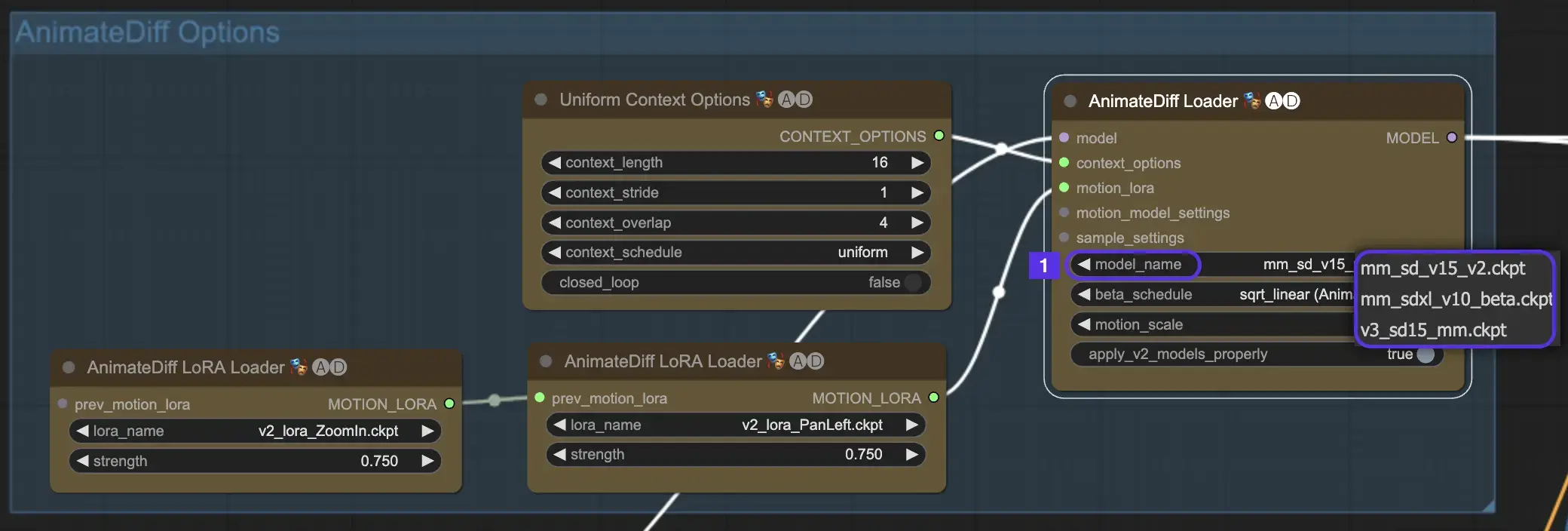
首先,从model_name下拉菜单中选择所需的AnimateDiff运动模块:
- 对于AnimateDiff V3,请使用v3_sd15_mm.ckpt
- 对于AnimateDiff V2,请使用mm_sd_v15_v2.ckpt
- 对于AnimateDiff SDXL,请使用mm_sdxl_v10_beta.ckpt
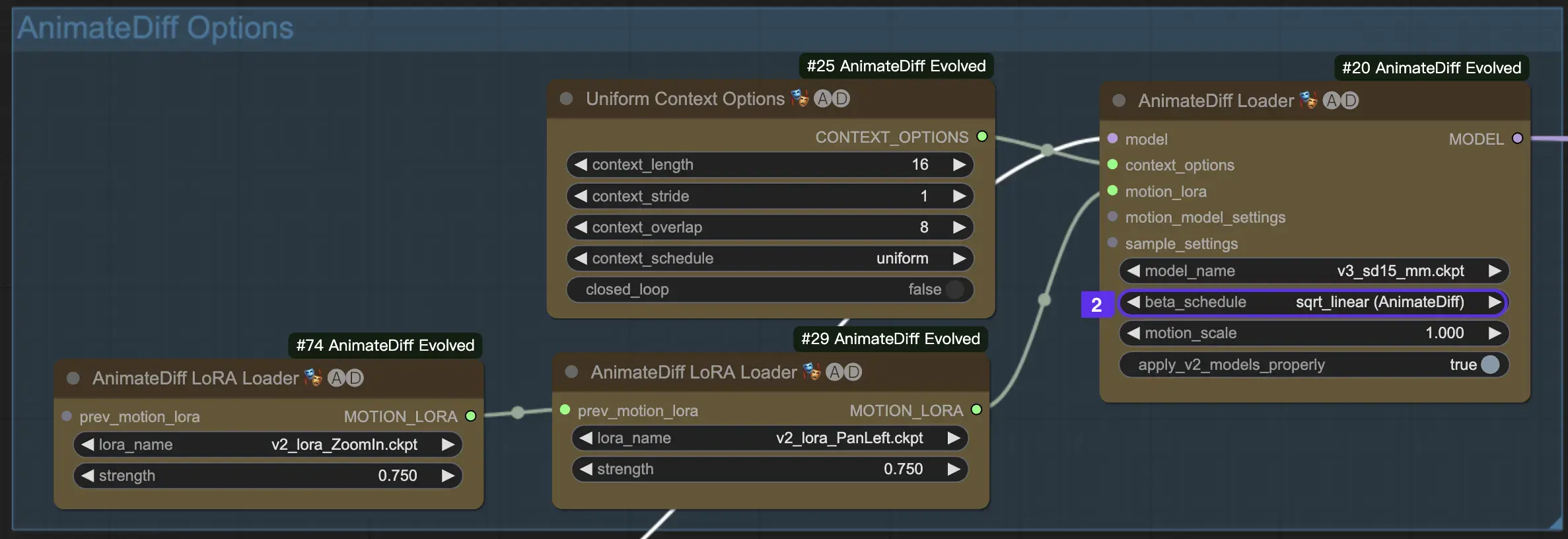
2.2 Beta进度表
AnimateDiff中的Beta进度表对于在整个动画创建过程中调整降噪过程至关重要。
对于AnimateDiff的V3和V2版本,建议使用sqrt_linear设置,尽管尝试使用linear设置可以产生独特的效果。
对于AnimateDiff SDXL,建议使用linear设置(AnimateDiff-SDXL)。
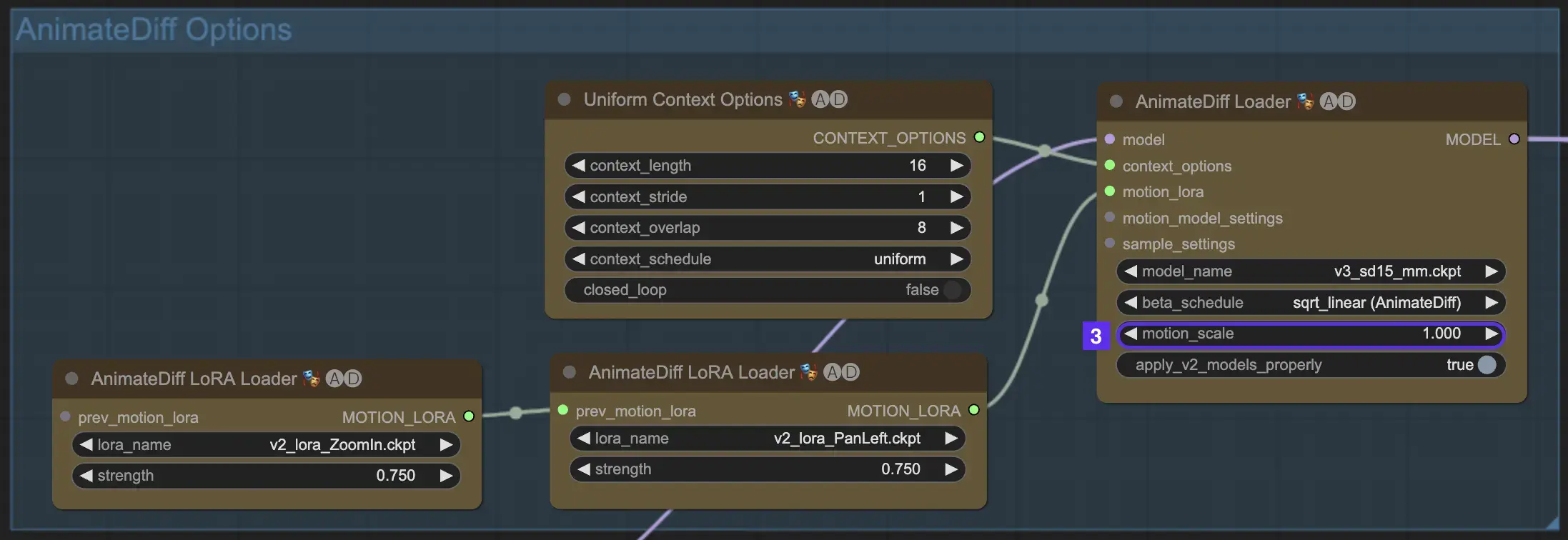
2.3 运动比例
AnimateDiff中的运动比例功能允许您调整动画中的运动强度。低于1的运动比例会产生更微妙的运动,而高于1的比例则会放大运动。
2.4 上下文长度
AnimateDiff中的统一上下文长度对于确保由批量大小定义的场景之间的无缝过渡至关重要。它就像一位专业的编辑,无缝地连接场景,实现流畅的叙事。设置较长的统一上下文长度可以确保更平滑的过渡,而较短的长度则提供更快、更明显的场景变化,有利于某些效果。标准的统一上下文长度设置为16。
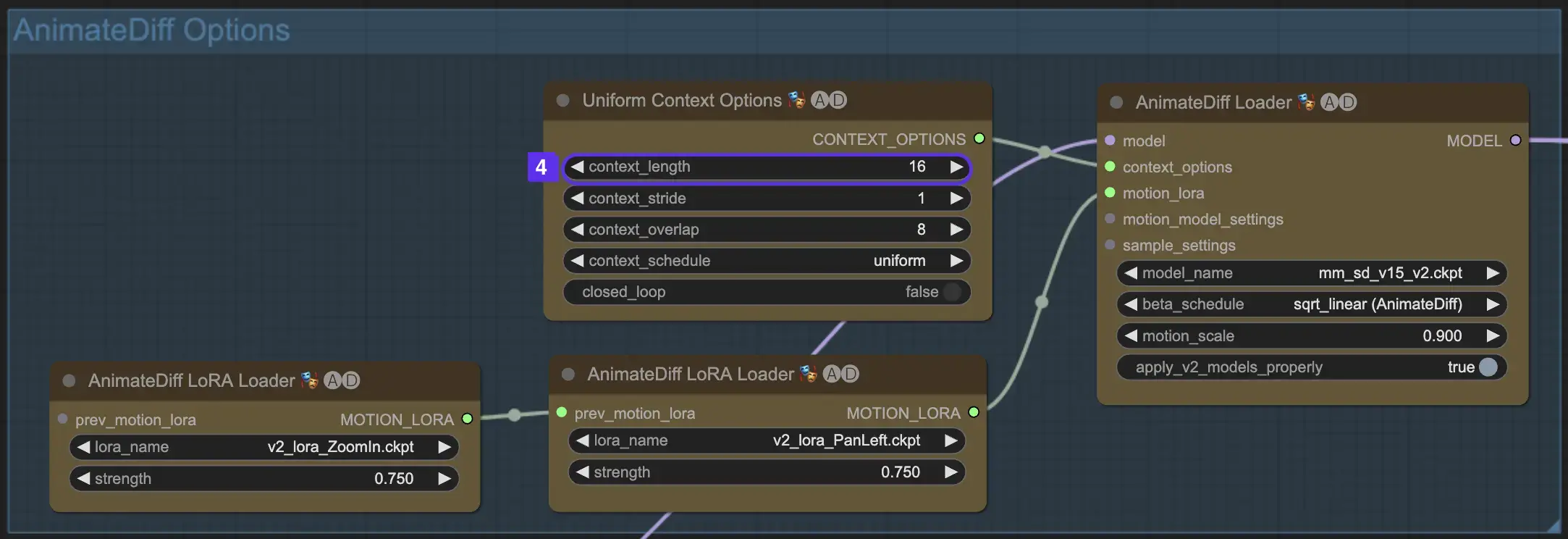
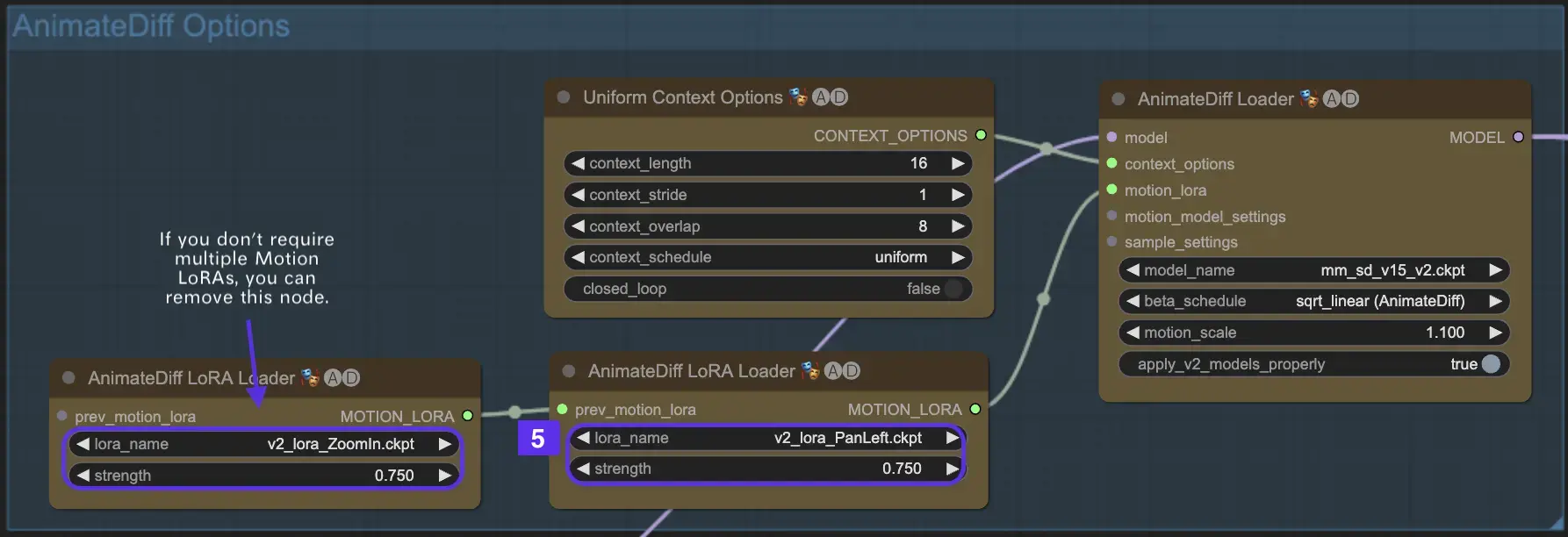
2.5 使用运动LoRA增强相机动态(特定于AnimateDiff v2)
运动LoRA仅与AnimateDiff v2兼容,为动态相机运动引入了一个额外的层次。在LoRA权重方面达到最佳平衡(通常在0.75左右)可以确保平滑的相机运动,避免背景失真。
此外,将各种运动LoRA模型链接起来可以实现复杂的相机动态。这使创作者能够进行试验,发现最理想的组合以提升其动画,使其达到电影级别。
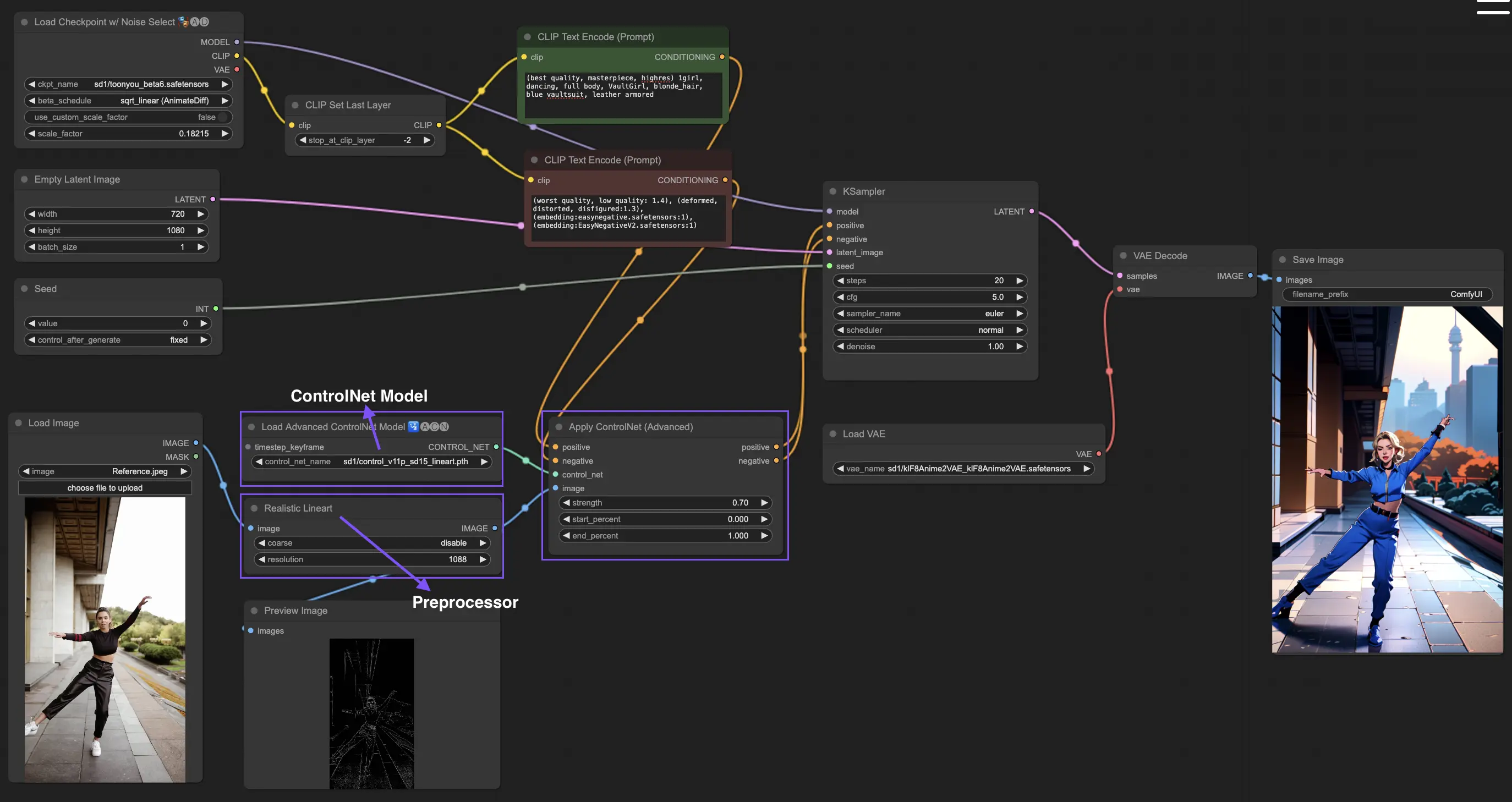
3. 如何使用ControlNet
ControlNet通过为文本到图像模型引入精确的空间控制来增强图像生成,使用户能够以超出文本提示的复杂方式操纵图像,利用来自Stable Diffusion等模型的大型库进行复杂的任务,如素描、映射和分割视觉效果。
以下是使用ControlNet的最简单工作流程。
3.1 加载"Apply ControlNet"节点
在ComfyUI中加载"Apply ControlNet"节点,为将视觉和文本元素结合到设计中做准备。
3.2 "Apply ControlNet"节点的输入
使用正面和负面调节来塑造图像,选择ControlNet模型来定义样式特征,并对图像进行预处理,以确保其符合ControlNet模型的要求,从而为转换做好准备。
3.3 "Apply ControlNet"节点的输出
节点输出指导扩散模型,提供进一步细化图像或添加更多ControlNet以根据ControlNet与您的创意输入的交互来增强细节和自定义的选择。
3.4 调整"Apply ControlNet"以获得最佳结果
通过确定强度、调整起始百分比和设置结束百分比等设置来控制ControlNet对图像的影响,从而精细调整图像的创作过程和结果。
更多详细信息,请查看
本工作流程灵感来自,并进行了一些修改。更多信息,请访问他的YouTube频道。
