舞蹈视频转换 | 场景定制与面部替换
这个舞蹈视频转换工作流程结合了SD1.5模型、AnimateDiff、ControlNet和ReActor面部替换,提供高质量的舞蹈编排转换。它使用三重ControlNet指导(边缘、深度和OpenPose)来保留舞者的动作,同时ReActor和CodeFormer确保准确的面部替换和增强的保真度。该工作流程支持通过批量提示调度进行动态场景控制,允许帧特定定制。通过AnimateDiff的上下文选项和自适应动作缩放,确保整个转换过程中动作的平滑自然保留。ComfyUI Dance Video Transform 工作流程
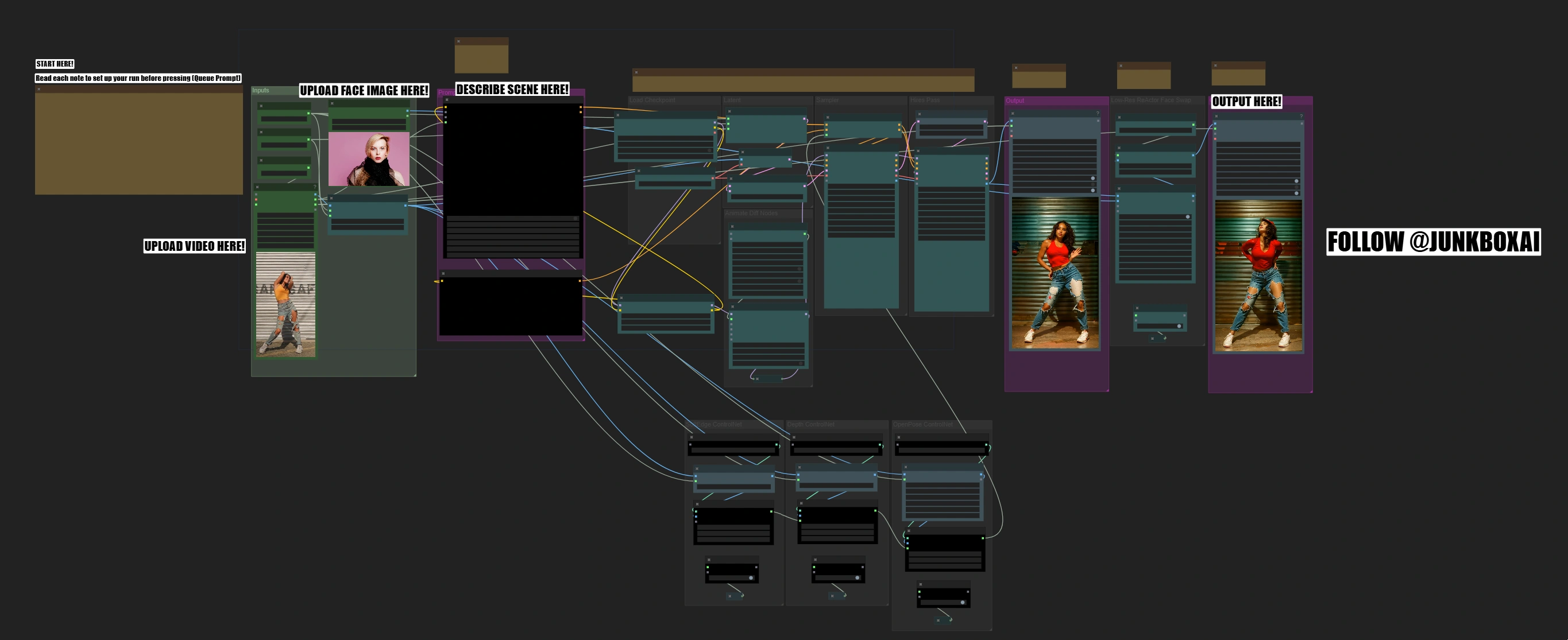
想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Dance Video Transform 示例
ComfyUI Dance Video Transform 描述
舞蹈视频转换ComfyUI工作流程的功能
舞蹈视频转换ComfyUI工作流程将舞蹈视频转换为令人惊叹的新场景,通过专业的面部替换保留原始编舞,并确保高质量输出。该过程分为多个阶段,从动作分析到面部替换,每个步骤都允许质量检查。
舞蹈视频转换ComfyUI工作流程的工作原理
该工作流程通过多个阶段自动化这些复杂的转换,只需您的视频、一张面部图像和场景描述: 动作分析 → 风格转移 → 面部替换
- 分析舞蹈动作和空间信息
- 根据您的描述转换场景
- 在保持表情的同时整合新面孔
舞蹈视频转换ComfyUI工作流程的关键特性
- 为垂直格式(9:16纵横比)优化
- 三重ControlNet系统确保稳定转换
- 专业的面部替换与自然融合
- 快速测试模式(几分钟内处理50帧)
- 支持高分辨率输出(最高896px高度)
- 使用AnimateDiff进行高级动作保留
- 双重输出系统用于质量验证
快速入门指南
步骤1:初始设置
在相应节点中:
-
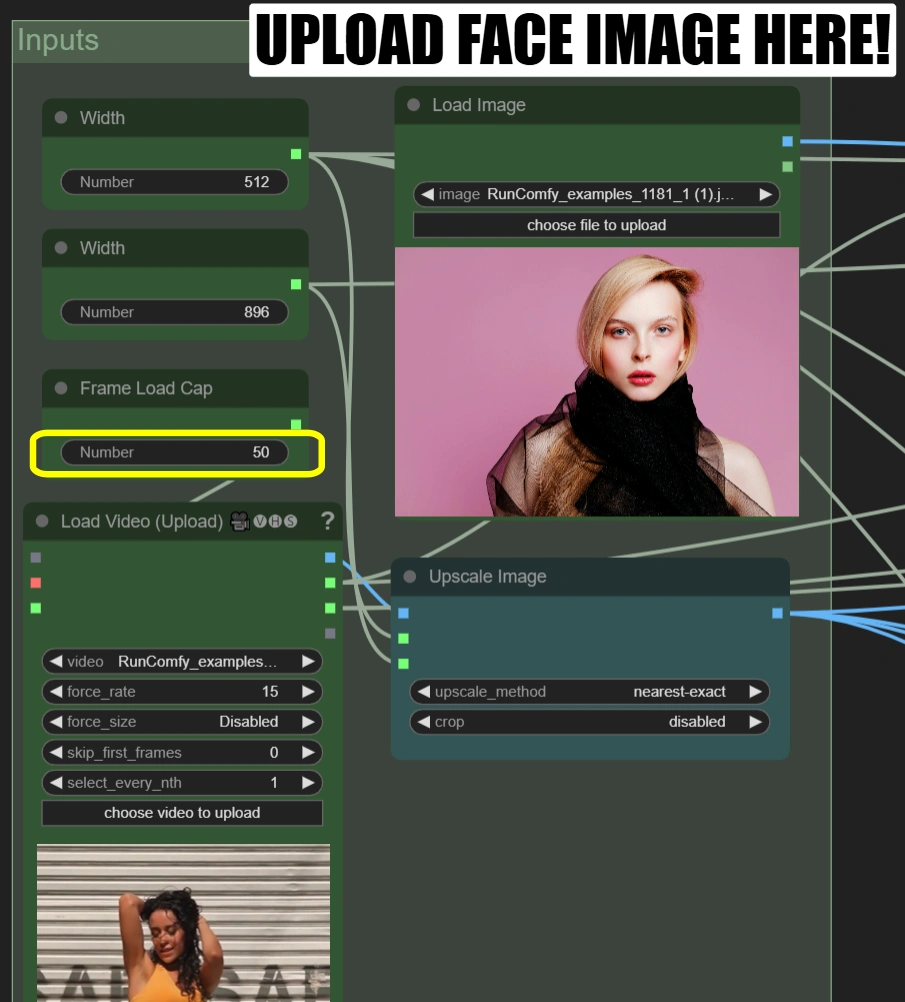
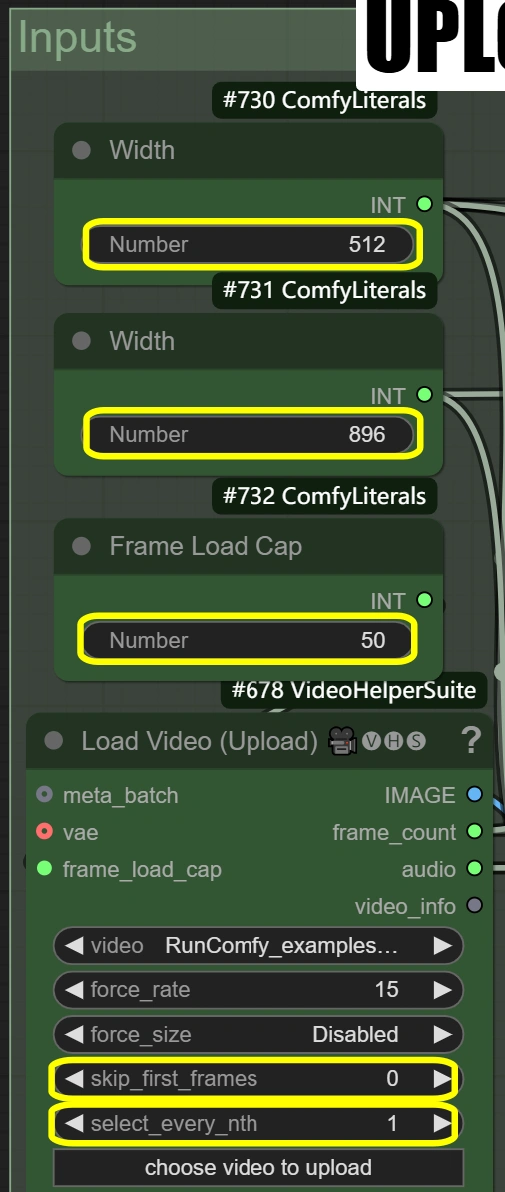
加载视频(上传):
- 上传10-15秒的9:16纵横比舞蹈视频
- 如果您的视频不是9:16,您需要调整参数宽度和高度以匹配您的视频。
- 帧加载上限:50(仅渲染前50帧进行快速测试)
-
加载图像:
- 上传清晰的正面人脸照片
-
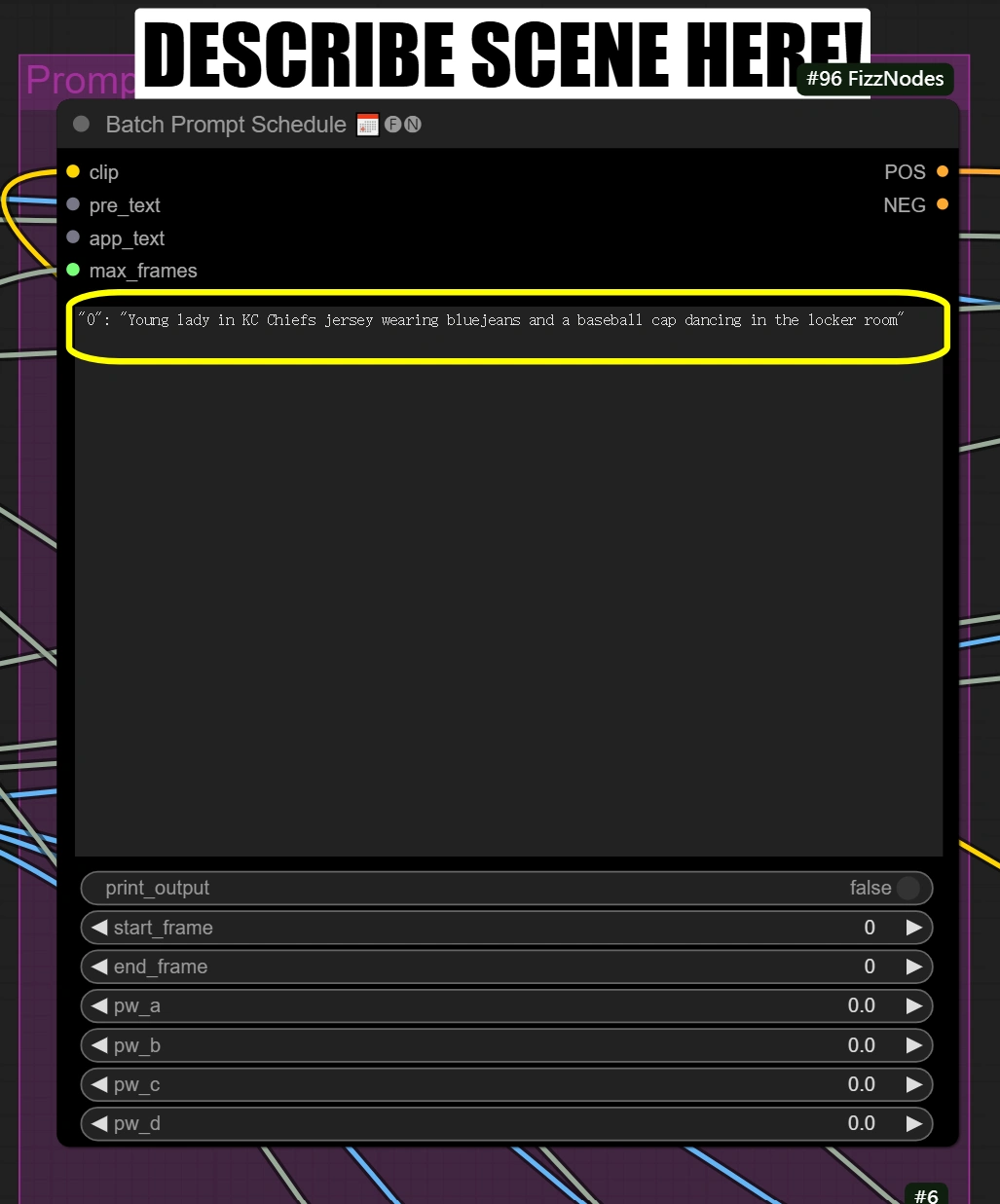
批量提示调度:
- 简要描述您想要转换的场景和其他方面
"0": "[person] in KC Chiefs jersey wearing bluejeans and a baseball cap dancing in the locker room"
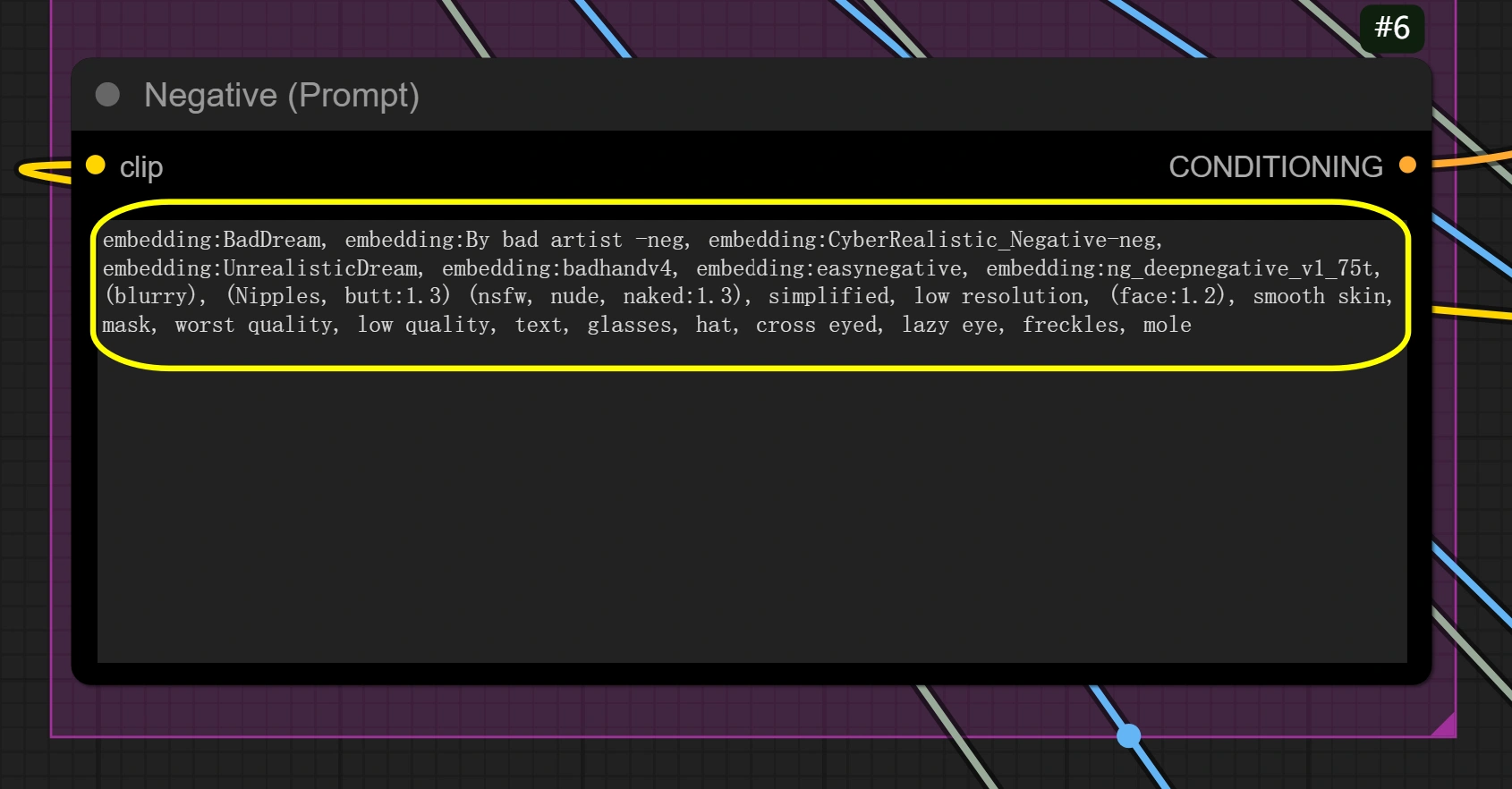
- 根据需要设置负面提示
步骤2:快速测试运行
- 点击"队列提示"
- 处理约2秒的视频
- 您将看到两个输出:
- 第一个输出:仅场景转换
- 第二个输出:应用面部替换

步骤3:完整视频处理
仅在快速测试效果良好后:
- 返回到"加载视频"节点
- 将帧加载上限更改为0以处理完整视频
- 点击"队列提示"进行完整处理 (这将需要更长时间)
初学者提示
- 遵循说明:查找界面中的任何说明,它们将逐步引导您
- 不用担心高级设置:大多数情况下,您只需要调整这里提到的内容
- 纵横比的重要性:确保纵横比正确,否则视频可能会看起来拉伸或裁剪
关键节点参考
AnimateDiff设置
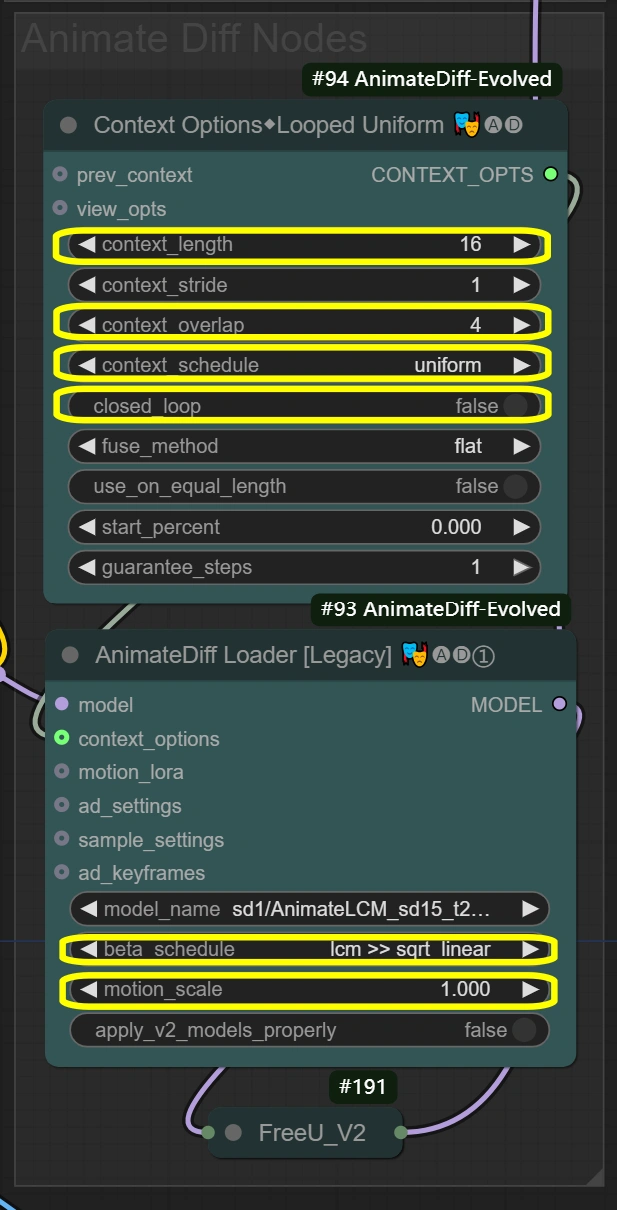
此处的节点创建整个视频转换过程中的平滑动作保留。 上下文选项定义帧如何分组和处理,将这些设置传递给AnimateDiff加载器,然后应用实际的动作保留。上下文长度和重叠设置直接影响AnimateDiff加载器如何保持运动一致性。
- 上下文选项节点(#94): 实现帧分组和时间处理控制以保持一致的运动。
- context_length:
- 控制一起处理的帧数
- 更高=更平滑但更多VRAM使用
- 更低=更快但可能失去动作一致性
- context_overlap:
- 处理帧过渡的平滑度
- 更高=更好的混合但处理更慢
- 更低=更快但可能显示过渡间隙
- context_schedule:
- 控制帧分布
- "uniform"最适合舞蹈动作
- 除非有特定需求,否则不要更改
- closed_loop:
- 控制视频循环行为
- 仅对完美循环的视频为真
- context_length:
- AnimateDiff加载器节点(#93): 使用AnimateDiff模型实现动作保留并应用时间一致性。
- motion_scale:
- 控制运动强度
- 更高:夸张的动作
- 更低:柔和的动作
- beta_schedule: lcm >> sqrt_linear
- 控制采样行为
- 针对此工作流程优化
- 除非必要,否则不要修改
- motion_scale:
ControlNet堆栈
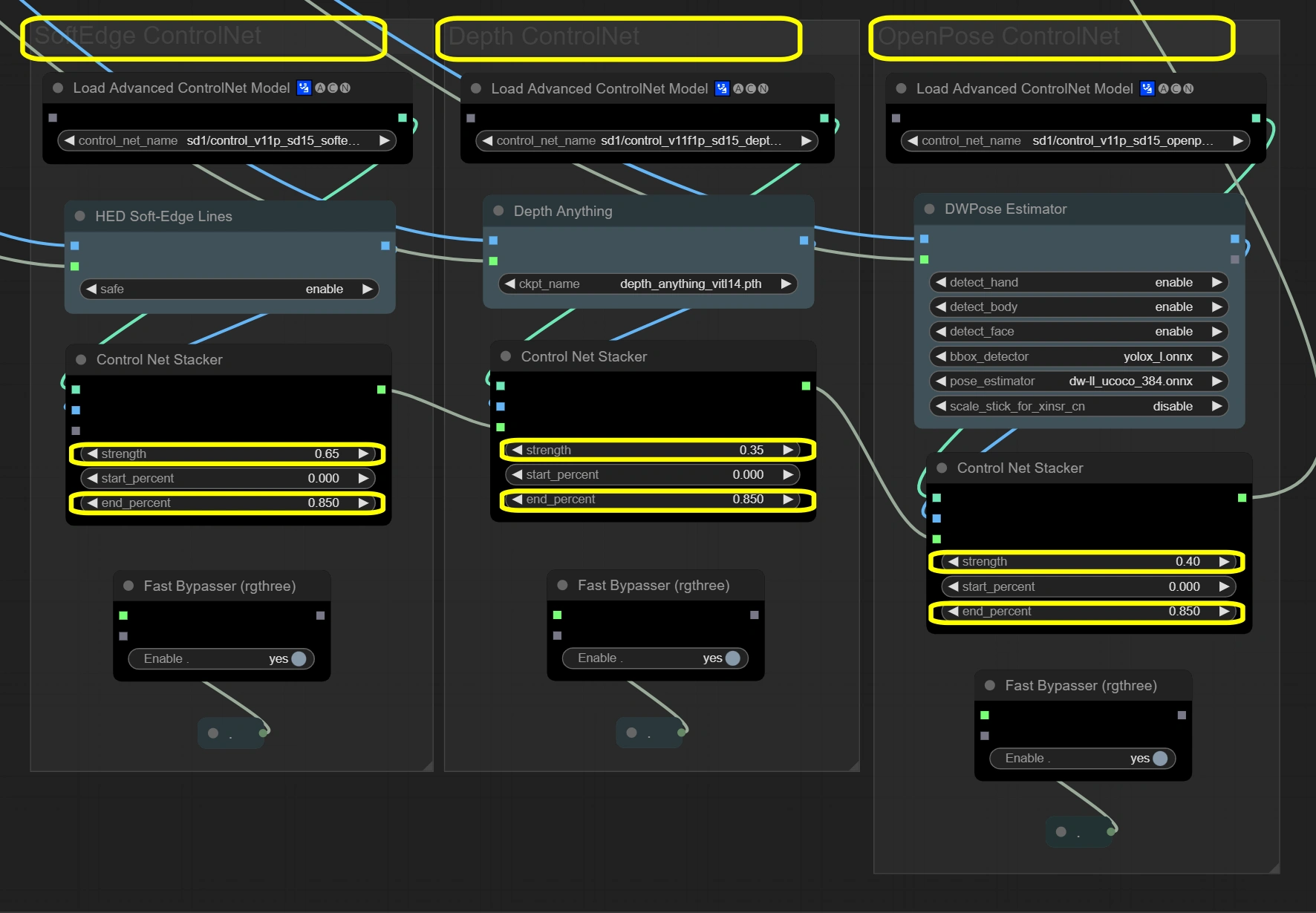
此处的节点通过三层指导系统保持视频完整性。 三个ControlNets同时处理输入帧,每个聚焦于不同的方面。Soft Edge提供基本结构,Depth增加空间理解,OpenPose确保动作准确性。结果通过堆栈器组合,总强度不超过1.4以确保稳定性。
- Soft Edge ControlNet: 从原始帧中提取和保留结构元素和形状。
- Strength:
- 控制结构保留
- 更高=更强的原始形状遵循
- 更低=形状修改的更多创意自由
- End percent:
- 控制影响停止时间
- 更高=在过程中的更长影响
- 更低=允许后期步骤的更多偏差
- Strength:
- Depth ControlNet: 处理空间关系并保持3D一致性。
- Strength:
- 控制空间感知
- 更高=更强的3D一致性
- 更低=空间创作的更多自由
- End percent:
- 保持深度影响的持续时间
- 应与Soft Edge匹配以保持一致性
- Strength:
- OpenPose ControlNet: 捕捉和传递姿势信息以确保准确的动作。
- Strength:
- 控制姿势保留
- 更高=更严格的姿势遵循
- 更低=姿势解释的更多灵活性
- End percent:
- 保持姿势影响
- 确保整个过程中的动作自然
- Strength:
面部处理
此处的节点处理面部替换和增强以获得自然结果。 该过程分为两个阶段:FaceRestore首先增强原始面部质量,然后ReActor使用增强的面部作为参考进行替换。此两阶段过程确保自然整合,同时保留表情。
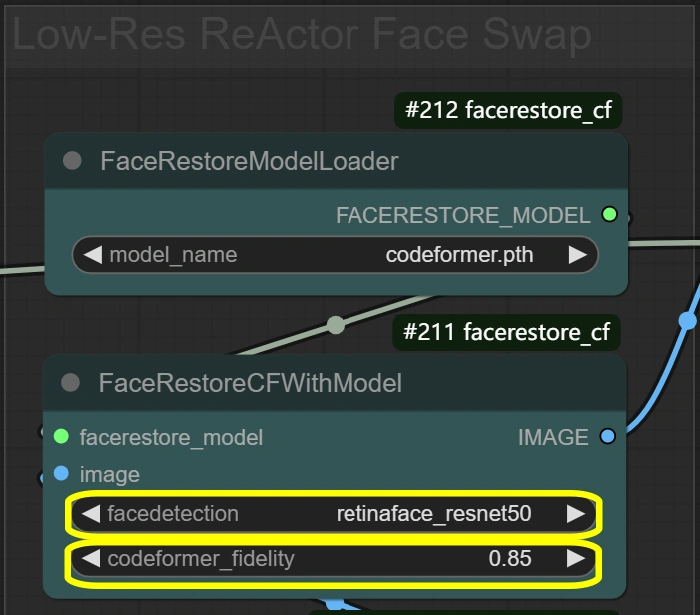
- FaceRestore系统: 增强面部细节并为替换做准备。
- Fidelity:
- 控制修复中的细节保留
- 更高=更详细但可能出现伪影
- 更低=更平滑但可能失去细节
- Detection:
- 面部检测模型选择
- 对大多数场景可靠
- 除非未检测到面部,否则不要更改
- Fidelity:
- ReActor面部替换: 执行面部替换和融合并保留表情。
- Visibility:
- 控制替换的可见性
- 更高=更强的面部替换效果
- 更低=更柔和的融合
- Weight:
- 面部特征保留平衡
- 更高=更强的源面部特征
- 更低=更好地与目标融合
- Console log level:
- 控制调试信息
- 更高=更详细的日志
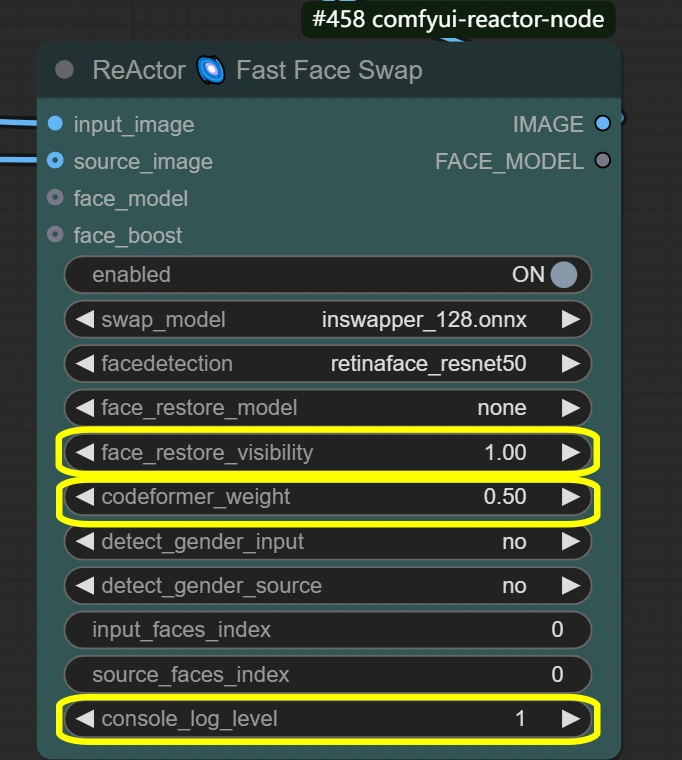
- Visibility:
其他节点细节
输入与预处理
目的:加载视频,调整尺寸,并为处理准备VAE模型。
- 加载视频:
- 帧加载上限:
- 控制要处理的帧数
- 50 = 快速测试(处理约2秒)
- 0 = 处理整个视频
- 影响总处理时间
- 跳过前几帧:
- 定义视频中的起始点
- 更高=视频中更晚开始
- 有助于跳过介绍
- 选择每第N帧:
- 控制帧采样率
- 更高的数字跳过帧
- 1 = 使用每帧
- 2 = 使用每第二帧,等等。
- 帧加载上限:
- 图像缩放:
- 宽度: 512
- 控制输出帧宽度
- 必须保持与高度的9:16比例
- 高度: 896
- 控制输出帧高度
- 必须保持与宽度的9:16比例
- 方法: nearest-exact
- 最适合保持清晰度
- 替代方法可能会模糊内容
- 推荐用于舞蹈视频
- 除非有特定需求,否则不要更改
- 宽度: 512
- VAE加载器:
- 模型: vae-ft-mse-840000-ema-pruned
- 针对稳定性和质量优化
- 处理图像编码/解码
- 平衡压缩比
- 除非有特定需求,否则不要更改
- VAE模式: 不要更改
- 针对当前工作流程优化
- 影响编码质量
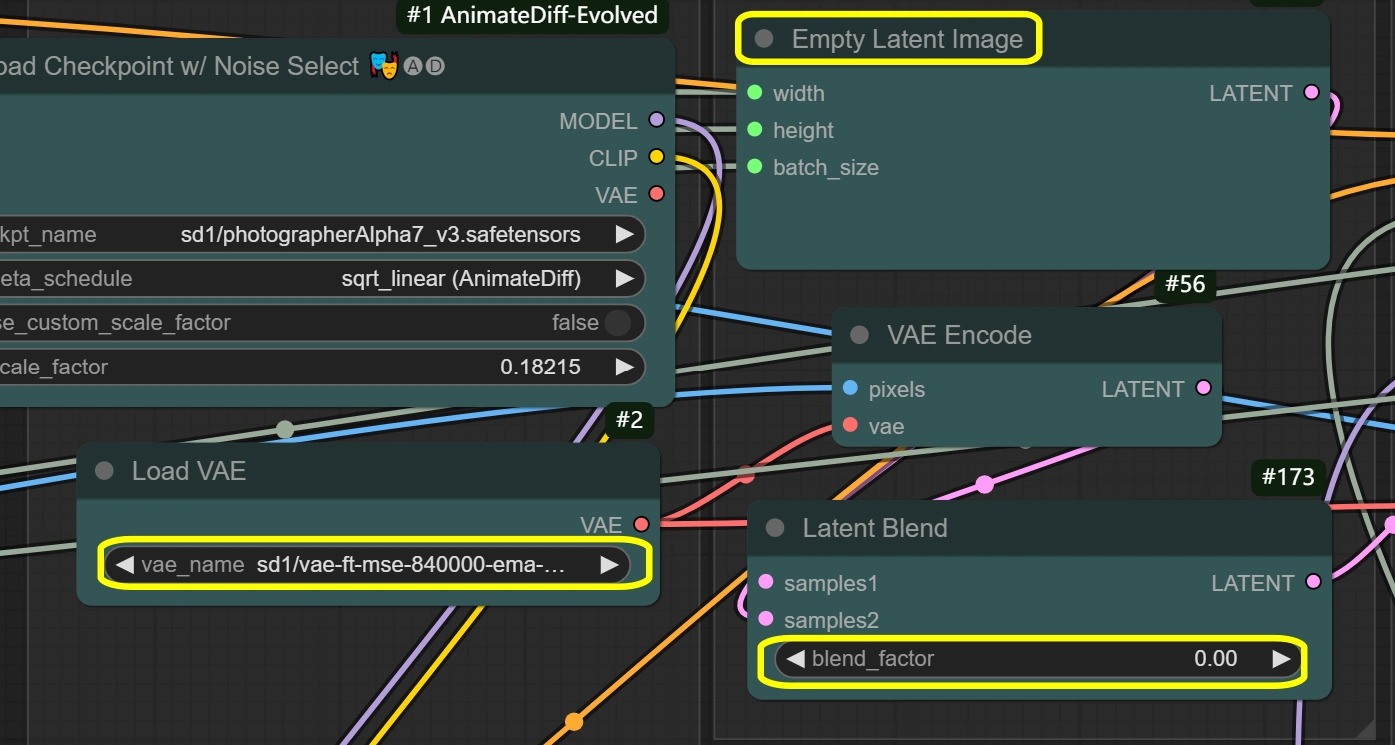
- 模型: vae-ft-mse-840000-ema-pruned
潜在处理
目的:处理所有潜在空间操作和转换。
- 空潜在图像:
- 宽度/高度: 匹配输入
- 必须与图像缩放尺寸匹配
- 直接影响内存使用
- 较大尺寸需要更多VRAM
- 不能小于输入
- 批量大小: 来自视频帧
- 从帧数自动设置
- 影响处理速度和VRAM
- 更高=需要更多内存
- 宽度/高度: 匹配输入
- VAE编码:
- VAE模型: 来自VAE加载器
- 使用VAE加载器的设置
- 保持一致性
- 解码: 启用
- 控制解码质量
- 仅在VRAM有限时禁用
- 影响输出质量
- VAE模型: 来自VAE加载器
- 潜在混合:
- 混合因子:
- 控制潜在空间的混合
- 0 = 完全源内容
- 更高=更多空潜在影响
- 影响风格转移强度
- 混合因子:
- 潜在放大:
- 方法: nearest-exact
- 最适合保持清晰度
- 替代方法可能会模糊
- 保留动作细节
- 比例:
- 控制尺寸增加
- 更高=更好细节但更多VRAM
- 更低=更快处理
- 1.6对大多数情况最优
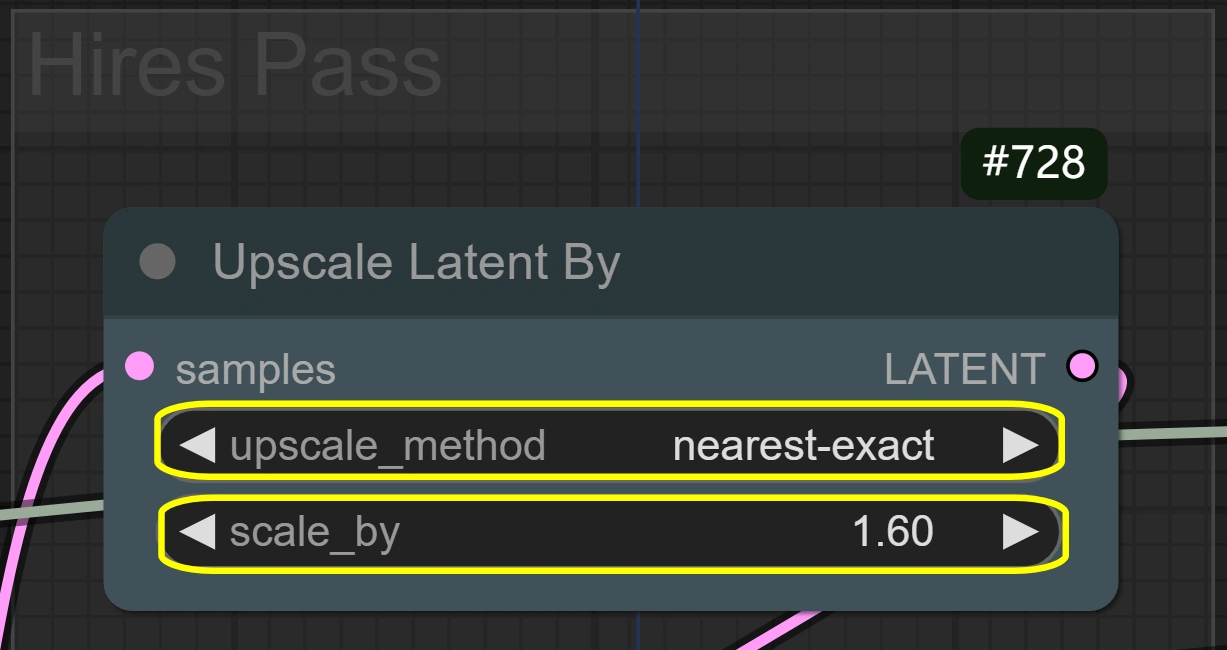
- 方法: nearest-exact
采样与精炼
目的:为质量转换进行的两阶段采样过程。
- KSampler(第一次):
- 步骤:
- 去噪步骤数量
- 更高=更好质量但更慢
- 6对lcm采样器最优
- CFG:
- 控制提示影响
- 更高=更强风格遵循
- 更低=更多自由
- 采样器: lcm
- 针对速度优化
- 良好的质量/速度平衡
- 调度器: sgm_uniform
- 与lcm最佳配合
- 保持时间一致性
- 去噪:
- 第一次全强度
- 控制转换强度
- 步骤:
- KSampler(高分辨率):
- 步骤:
- 与第一次一致性匹配
- 更高不需要精炼
- CFG:
- 保持风格一致性
- 平衡细节保留
- 采样器: lcm
- 与第一次相同
- 保持一致性
- 调度器: sgm_uniform
- 保持与第一次一致性
- 适合细节精炼
- 去噪:
- 低于第一次
- 保留更多原始细节
- 适合精炼的良好平衡
- 步骤:
输出处理
目的:创建有和没有面部替换的最终视频输出。
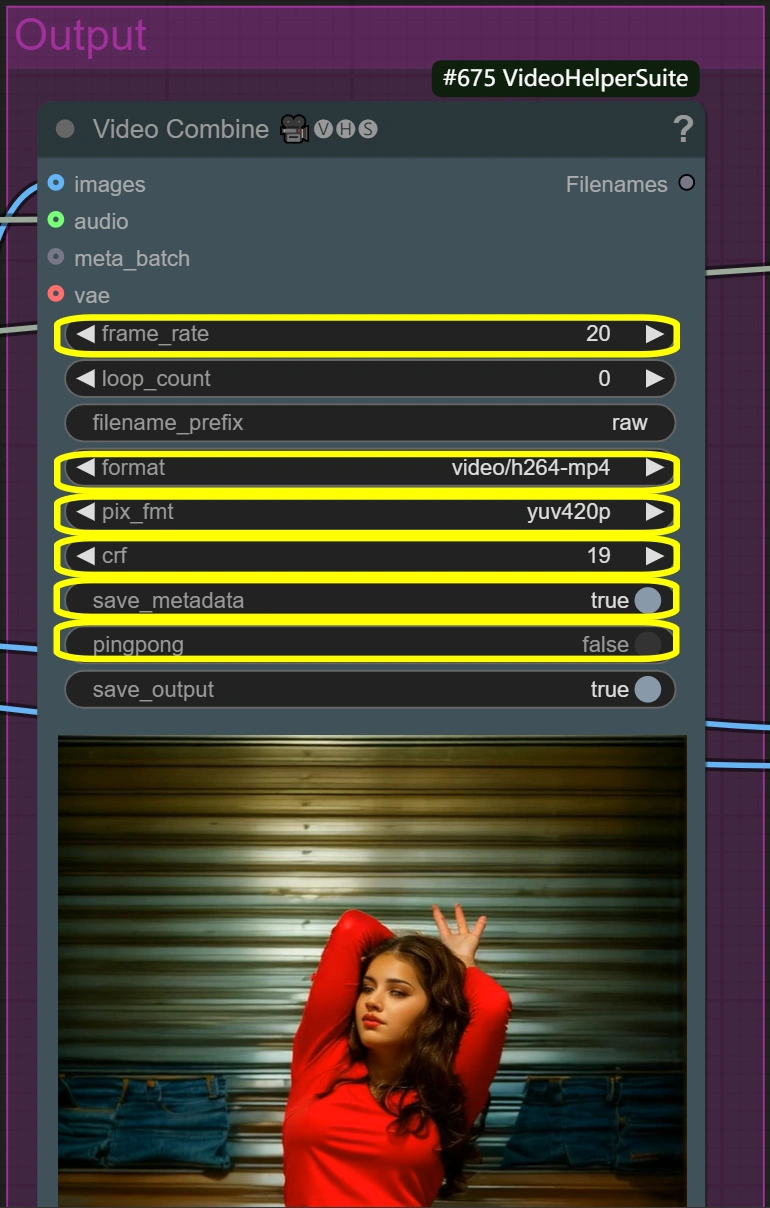
- 视频合成(原始):
- 帧率:
- 标准视频帧率
- 控制播放速度
- 更低=更小文件大小
- 更高=更平滑的动作
- 格式: video/h264-mp4
- 标准格式以确保兼容性
- 良好的质量/大小平衡
- 广泛支持
- CRF:
- 控制压缩质量
- 更低=更好质量但更大文件
- 更高=更小文件但质量更低
- 19是高质量设置
- 像素格式: yuv420p
- 标准格式以确保兼容性
- 除非需要否则不要更改
- 确保广泛的播放支持
- 帧率:
- 视频合成(面部替换):
- 与原始输出相同的参数
- 使用相同的设置以确保一致性
- 增加面部替换整合
- 保持视频质量设置
优化提示
质量与速度权衡
- 分辨率平衡:
- 标准:512x896
- 更快的处理
- 适合大多数用途
- 高质量:768x1344
- 更好的细节
- 2-3倍更长的处理时间
- 标准:512x896
- 面部替换质量:
- 标准:默认设置
- 自然整合
- 平衡的处理时间
- 最高质量:
- 增加codejson former_fidelity到0.9
- 更慢但面部更详细
- 标准:默认设置
- 动作平滑度:
- 更快的处理:
- 将context_overlap减少到2
- 略低的平滑过渡
- 更好的动作:
- 将overlap增加到6
- 使用更多VRAM,处理更慢
- 更快的处理:
常见问题与解决方案
- 面部融合:
- 问题:面部过渡不自然
- 解决方案:调整codeformer_weight
- 尝试范围0.4-0.7
- 更低=更好的融合
- 更高=更多的面部细节
- 风格强度:
- 问题:风格转移弱
- 解决方案:增加cfg
- 尝试范围7-8
- 更高=更强的风格
- 可能影响动作质量
- 内存管理:
- 问题:VRAM限制
- 解决方案:
- 启用VAE切片
- 降低分辨率
- 处理较短段落
更多信息
有关更多细节和精彩创作,请访问 。


