混元视频 | 视频到视频
在ComfyUI中的混元工作流程允许您将现有视觉效果转化为令人惊叹的新视觉效果。通过输入文本提示和源视频,混元模型生成的翻译作品将源视频中的运动和关键元素融入其中。凭借先进的架构和训练技术,混元生产出高质量、多样化且稳定的内容。ComfyUI Hunyuan Video to Video 工作流程
想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Hunyuan Video to Video 示例
ComfyUI Hunyuan Video to Video 描述
混元视频是由腾讯开发的开源AI模型,让您可以轻松生成令人惊叹的动态视觉效果。混元模型利用先进的架构和训练技术来理解和生成高质量、运动多样性和稳定性的内容。
关于混元视频到视频工作流程
在ComfyUI中的混元工作流程利用混元模型,通过将输入文本提示与现有驱动视频结合来创建新的视觉内容。利用混元模型的能力,您可以生成令人印象深刻的视频翻译,这些翻译作品无缝地将驱动视频中的运动和关键元素融入其中,同时使输出与您期望的文本提示对齐。
如何使用混元视频到视频工作流程
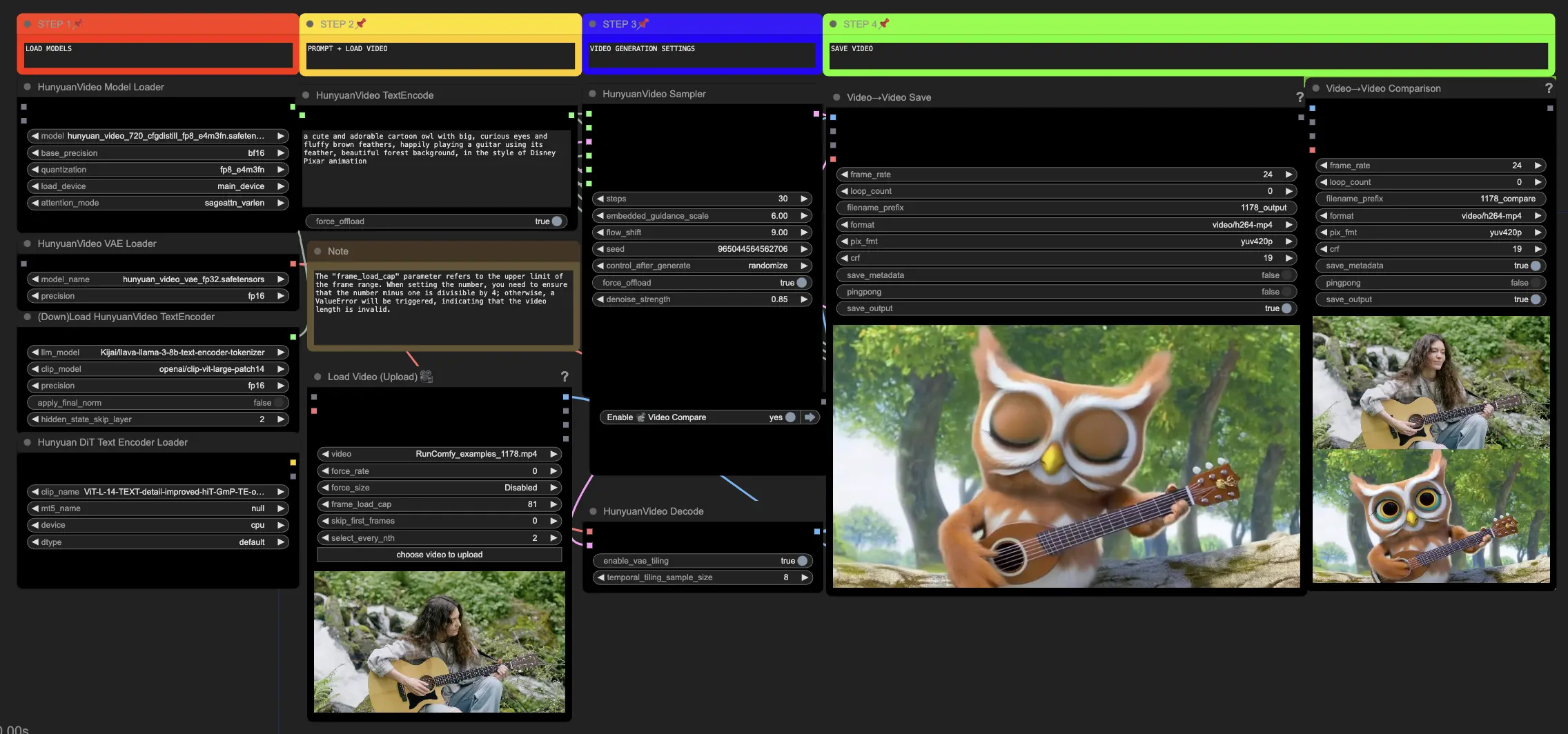
🟥 步骤1:加载混元模型
- 在HyVideoModelLoader节点中选择"hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors"文件来加载混元模型。这是主要的转换器模型。
- 混元视频VAE模型将在HunyuanVideoVAELoader节点中自动下载。它用于编码/解码视频帧。
- 在DownloadAndLoadHyVideoTextEncoder节点中加载一个文本编码器。工作流程默认使用"Kijai/llava-llama-3-8b-text-encoder-tokenizer" LLM编码器和"openai/clip-vit-large-patch14" CLIP编码器,它们将被自动下载。您也可以使用其他与先前模型一起工作的CLIP或T5编码器。
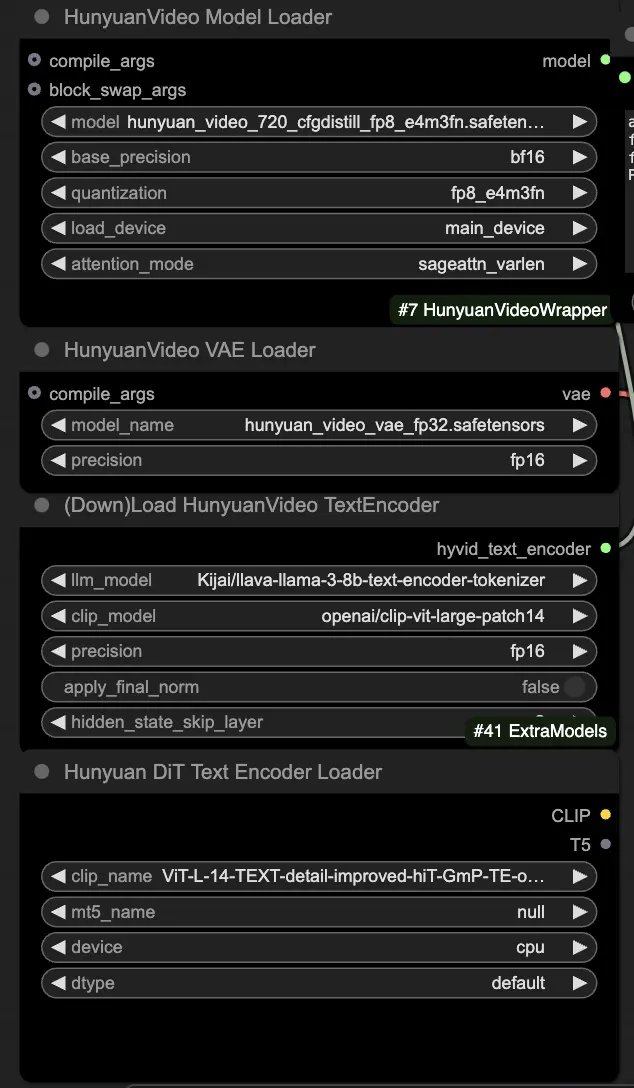
🟨 步骤2:输入提示并加载驱动视频
- 在HyVideoTextEncode节点中输入您想生成的视觉效果的文本提示。
- 在VHS_LoadVideo节点中加载您想用作运动参考的驱动视频。
- frame_load_cap:要生成的帧数。在设置数量时,您需要确保数量减一可以被4整除;否则,会触发ValueError,指示视频长度无效。
- skip_first_frames:调整此参数以控制视频的哪个部分被使用。
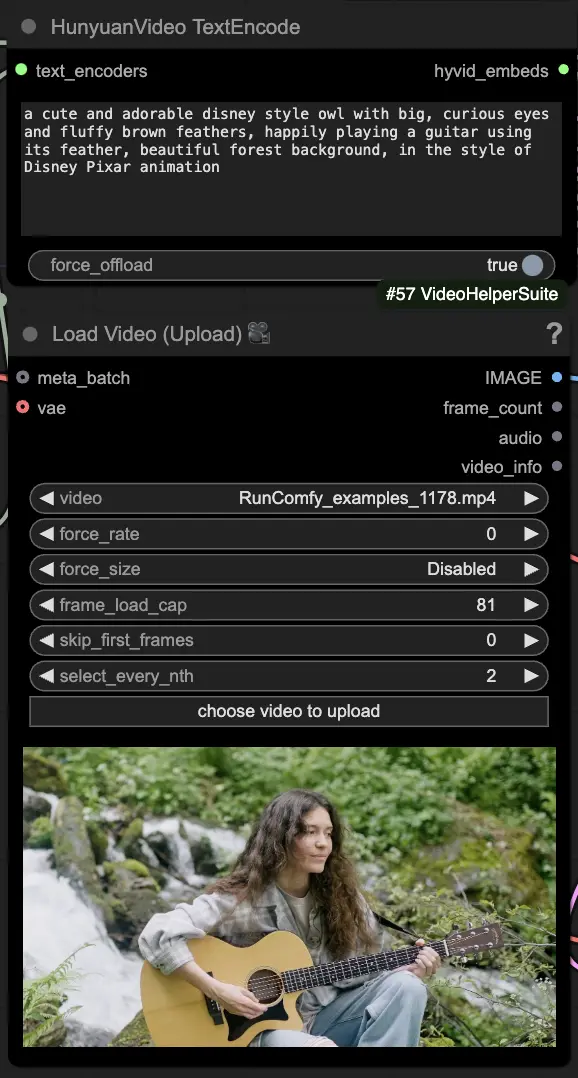
🟦 步骤3:混元生成设置
- 在HyVideoSampler节点中配置视频生成的超参数:
- Steps:每帧的扩散步骤数,越高质量越好但生成速度越慢。默认30。
- Embedded_guidance_scale:遵循提示的程度,值越高越接近提示。
- Denoise_strength:控制使用初始驱动视频的强度。较低的值(例如0.6)使输出更像初始视频。
- 在"Fast Groups Bypasser"节点中选择附加组件和切换功能,以启用/禁用额外功能,如对比视频。
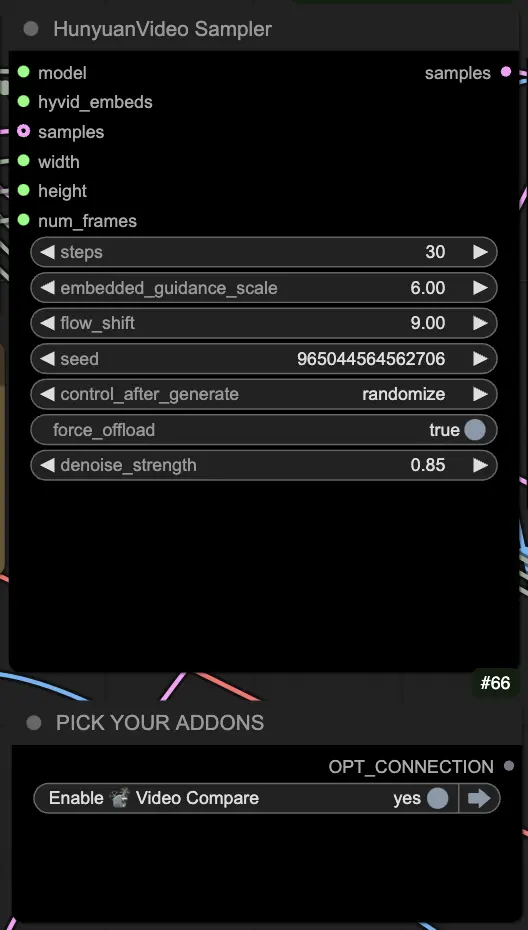
🟩 步骤4:生成混元视频
- VideoCombine节点将默认生成并保存两个输出:
- 翻译视频结果
- 显示驱动视频和生成结果的对比视频
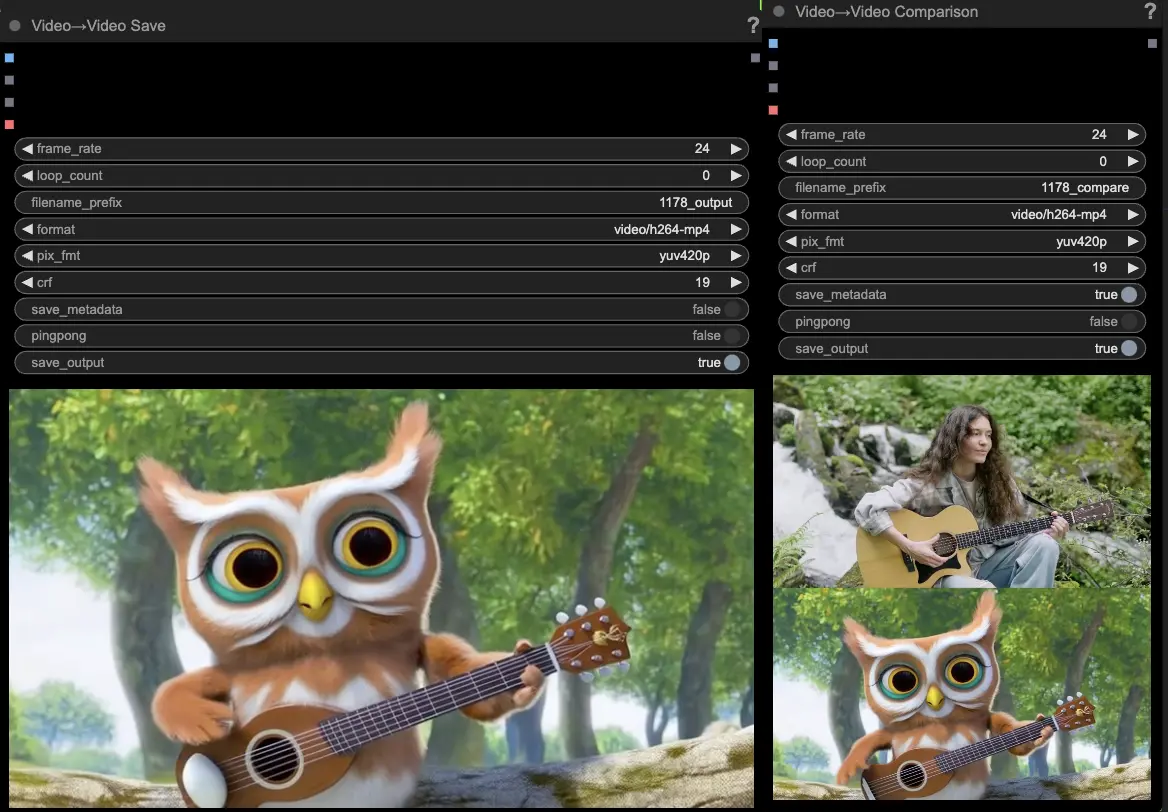
调整提示和生成设置可以灵活地创建由现有视频运动驱动的新视频,使用混元模型。尽情探索此混元工作流程的创造性可能性吧!
此混元工作流程由Black Mixture设计。请访问以获取更多信息。特别感谢节点和工作流程示例。

