Linear Mask Dilation | Stunning Animations
ComfyUI Linear Mask Dilation is a powerful workflow for creating stunning video animations. By transforming your subject, such as a dancer, you can seamlessly have them travel through different scenes using a mask dilation effect. This workflow is specifically designed for single subject videos. Follow the step-by-step guide to learn how to use Linear Mask Dilation effectively, from uploading your subject video to setting prompts and adjusting various parameters for optimal results. Unleash your creativity and bring your video animations to life with ComfyUI Linear Mask Dilation.ComfyUI Linear Mask Dilation Workflow
Want to run this workflow?
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI Linear Mask Dilation Examples
ComfyUI Linear Mask Dilation Description
ComfyUI Linear Mask Dilation
Create stunning video animations by transforming your subject (dancer) and have them travel through different scenes via a mask dilation effect. This workflow is designed to be used with single subject videos.
How to use ComfyUI Linear Mask Dilation Workflow:
- Upload a subject video in the Input section
- Select the desired width and height of the final video, along with how many frames of the input video should be skipped with “every_nth”. You can also limit the total number of frames to render with “frame_load_cap”.
- Fill out the positive and negative prompt. Set batch frame times to match when you’d like the scene transitions to occur.
- Upload images for each of the IP Adapter subject mask colors:
- White = subject (dancer)
- Black = First background
- Red = Red dilation mask background
- Green = Green dilation mask background
- Blue = Blue dilation mask background
- Load a good LCM checkpoint (I use ParadigmLCM by Machine Delusions) in the “Models” section.
- Add any loras using the Lora stacker below the model loader
- Hit Queue Prompt
Input
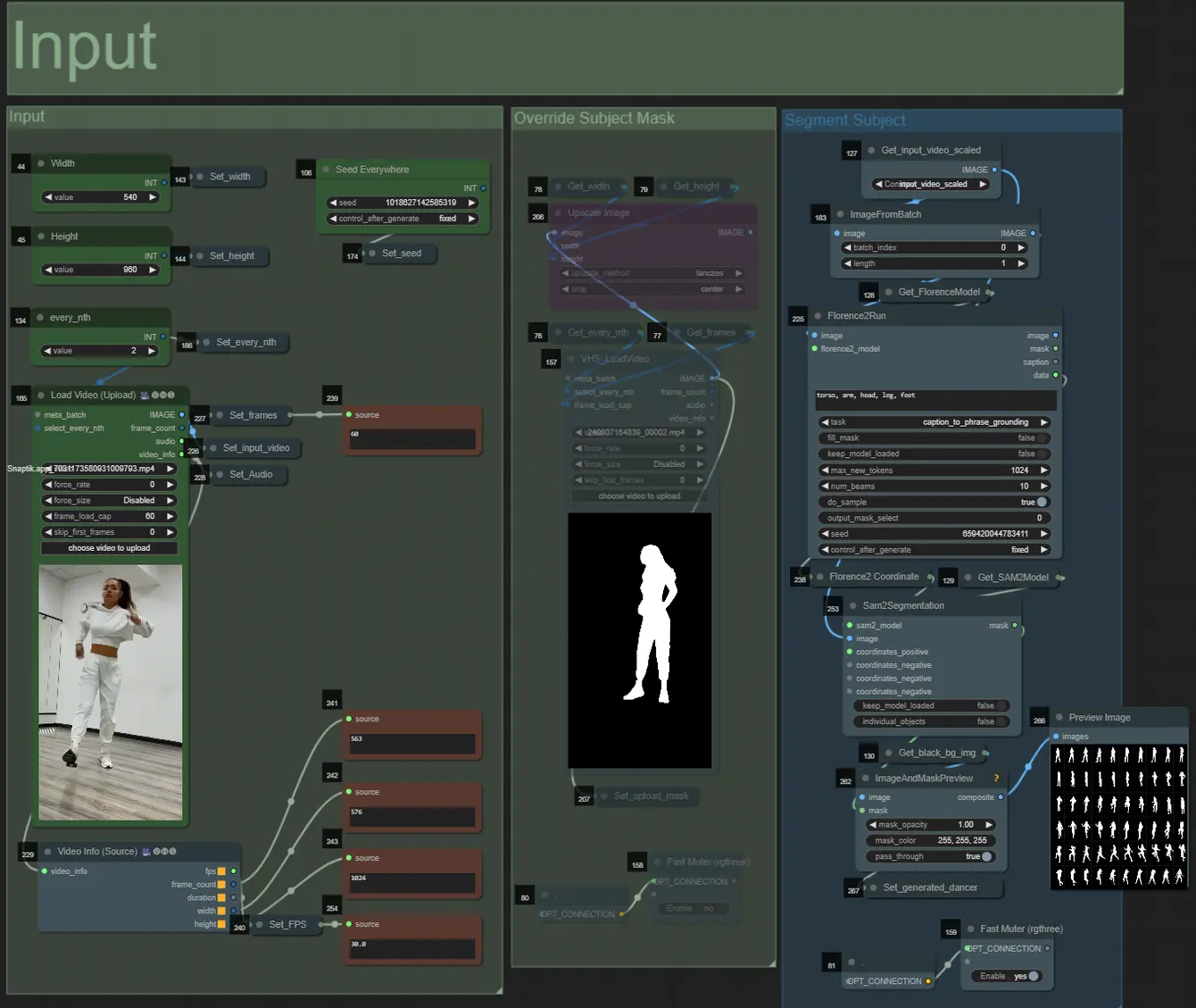
- You can adjust the width, height using the top left two inputs
- every_nth sets how many frames of the input should be skipped (2 = every other frame)
- The number fields in bottom left display info about the uploaded input video: total frames, width, height, and FPS from top to bottom.
- If you already have a mask video of the subject generated (must be white subject on black background), you can un-mute the “Override Subject Mask” section and upload the mask video. Optionally you can mute the “Segment Subject” section to save some processing time.
- Sometimes the segmented subject will not be perfect, you can check the mask quality using the preview box in the bottom right seen above. If that is the case you can play around with the prompt in the “Florence2Run” node to target different body parts such as “head”, “chest”, “legs”, etc. and see if you get a better result.
Prompt
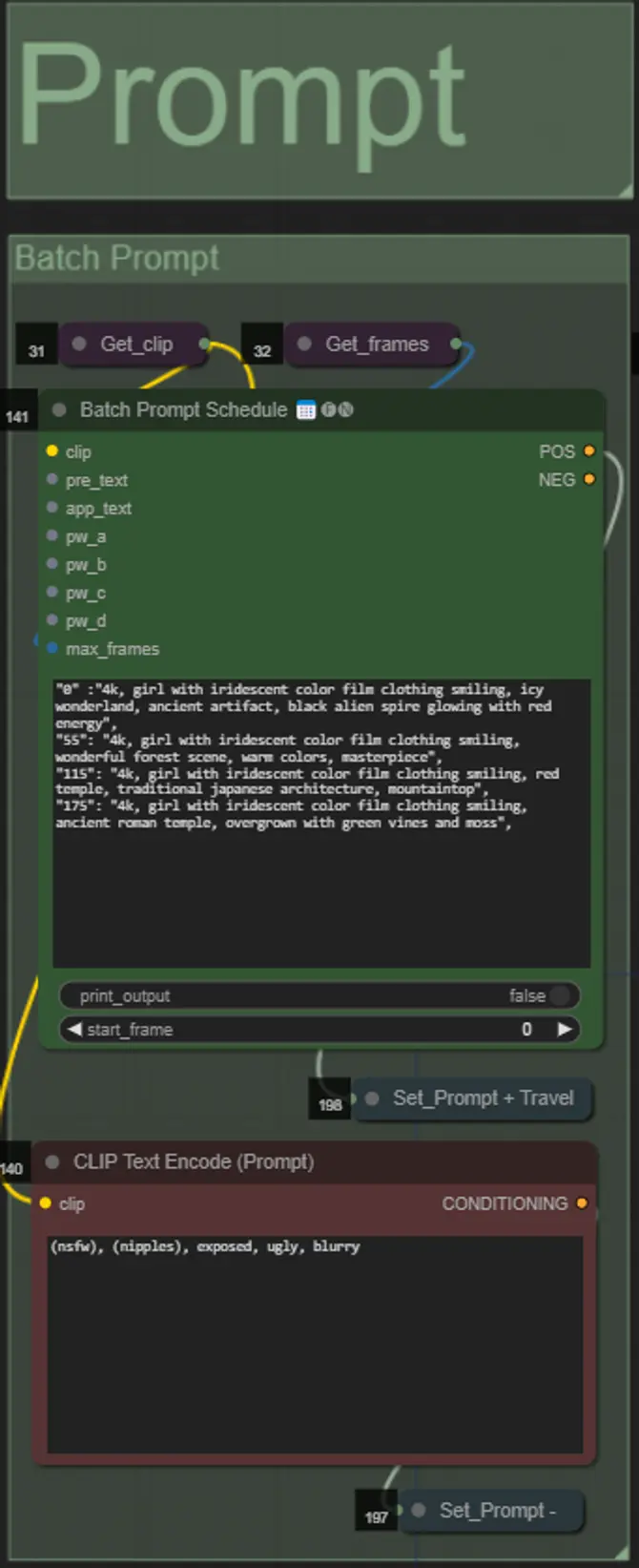
- Set the positive prompt using batch formatting:
- e.g. “0”: “4k, masterpiece, 1girl standing on the beach, absurdres”, “25”: “HDR, sunset scene, 1girl with black hair and a white jacket, absurdres”, …
- Negative prompt is normal format, you can add embeddings if desired.
Mask Dilations
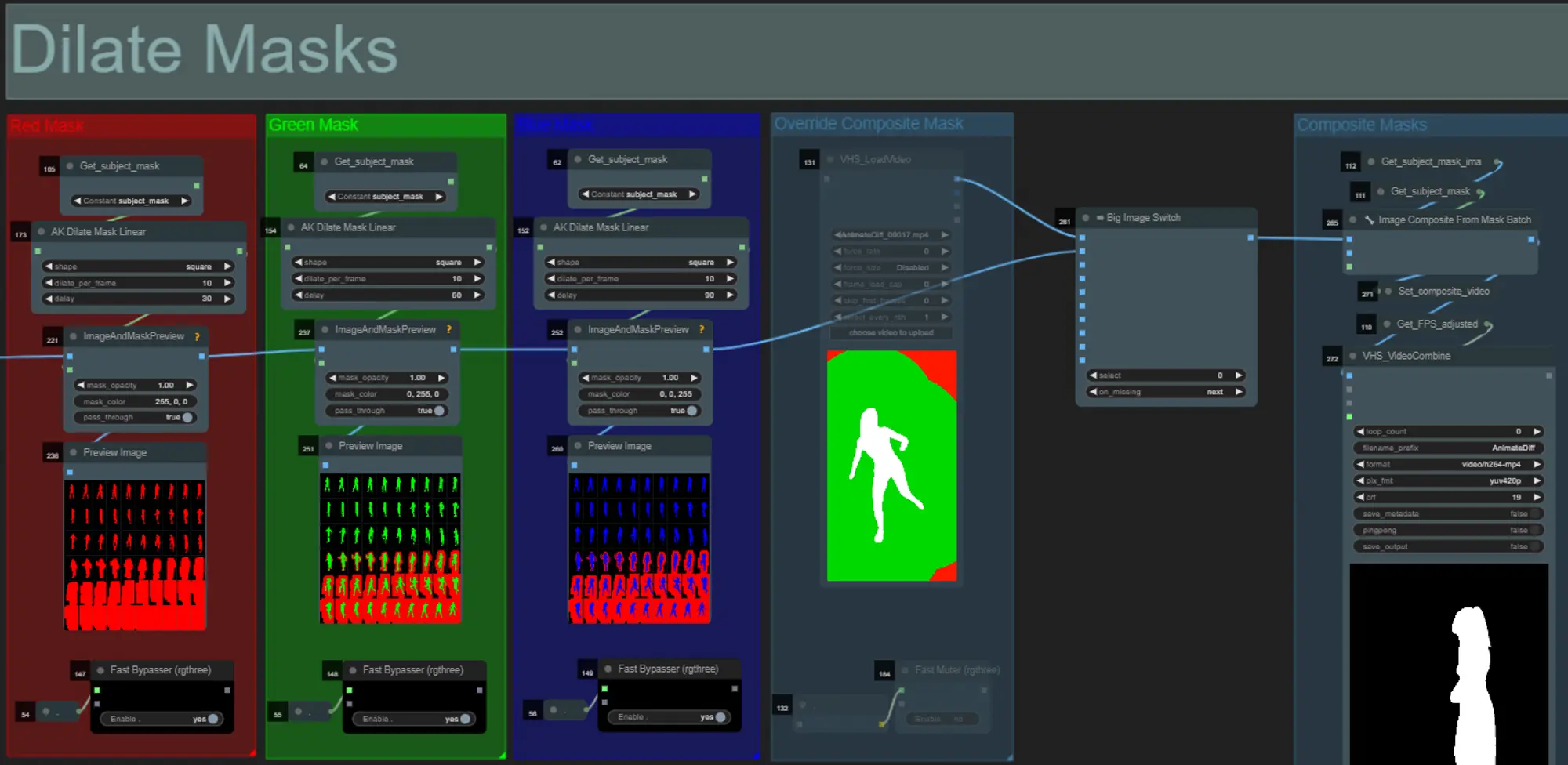
- Each colored group corresponds to the color of dilation mask that will be generated by it.
- You can set the shape of the mask, along with speed of dilation and frame delay with the following node:
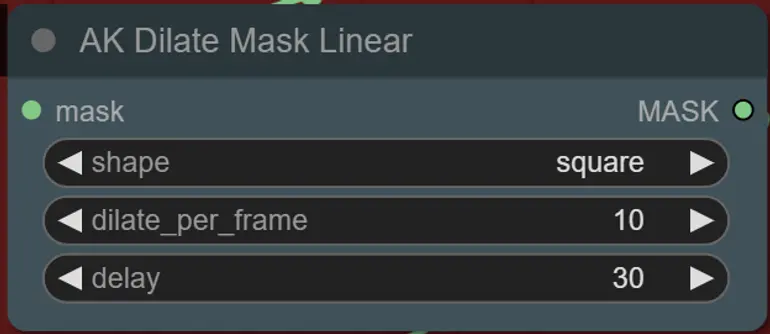
- shape: “circle” is the most accurate but takes longer to generate. Set this when you are ready to perform the final rendering. “square” is fast to compute but less accurate, best for testing out the workflow and deciding on IP adapter images.
- dilate_per_frame: How quickly the mask should dilate, larger numbers = faster dilation speed
- delay: How many frames to wait before the mask begins to dilate.
- If you already have a composite mask video generated you can un-mute the “Override Composite Mask” group and upload it. It’s recommended to bypass the dilation mask groups if overriding to save on processing time.
Models
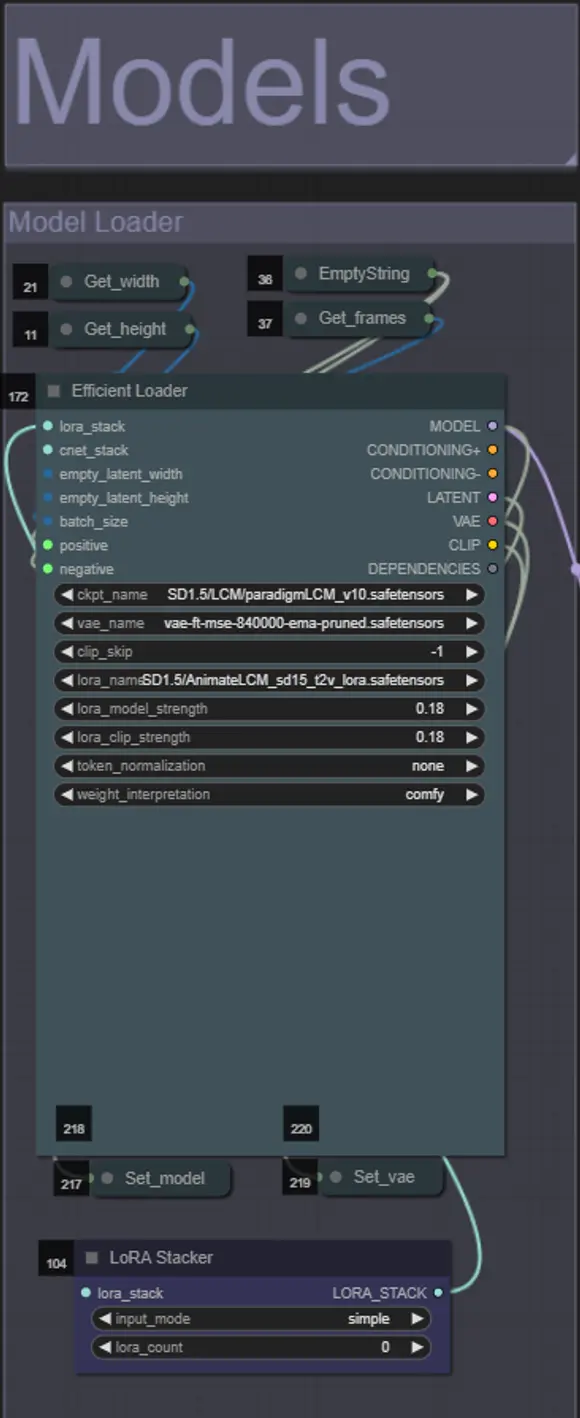
- Use a good LCM model for the checkpoint. I recommend ParadigmLCM by Machine Delusions.
- You can optionally specify the AnimateLCM_sd15_t2v_lora.safetensors with a low weight of 0.18 to further enhance the final result.
- Add any additional Loras to the model using the blue Lora stacker below the model loader.
AnimateDiff
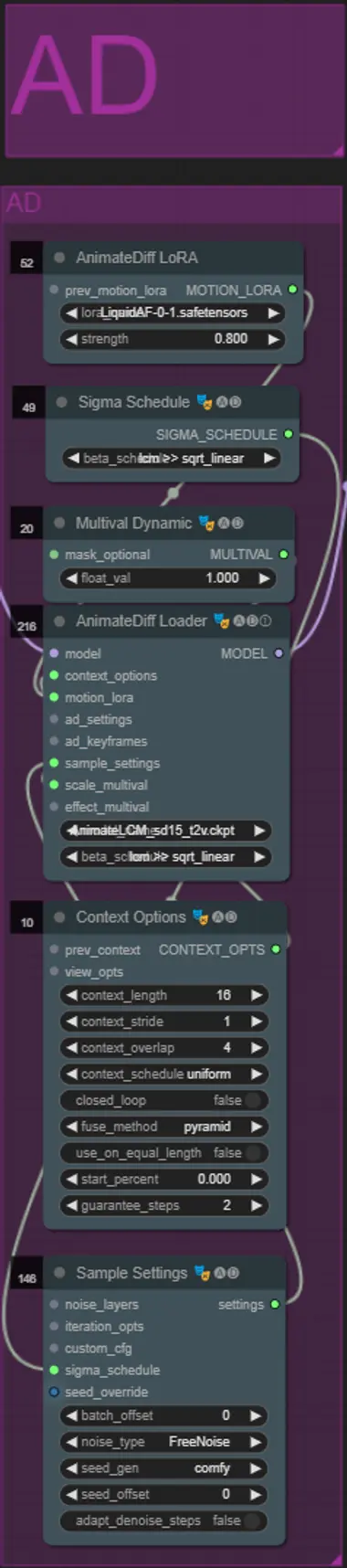
- You can set a different Motion Lora instead of the one I used (LiquidAF-0-1.safetensors)
- Adjust the Multival Dynamic float value higher or lower depending on if you want the result to have more or less motion.
IP Adapters
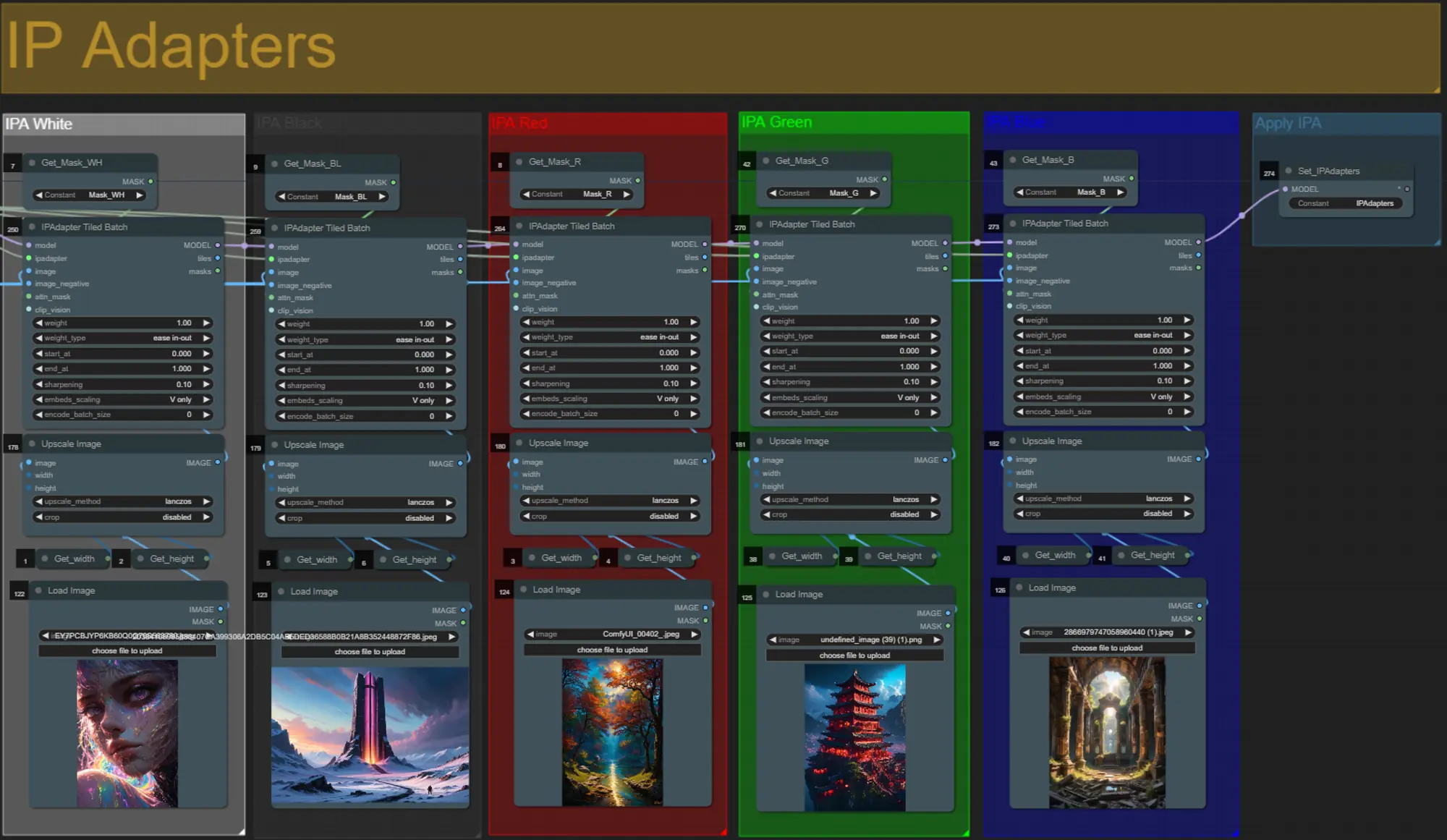
- Here you can specify the reference subjects that will be used to render the backgrounds for each of the dilation masks, as well as your video subject.
- The color of each group represents the mask it targets:
- White = subject (dancer)
- Black = First background
- Red = Red dilation mask background
- Green = Green dilation mask background
- Blue = Blue dilation mask background
- If you want the final render to more closely follow the input IP adapter images, you can change the IPAdapter preset from VIT-G to PLUS in the IPA Unified Loader group.
ControlNet
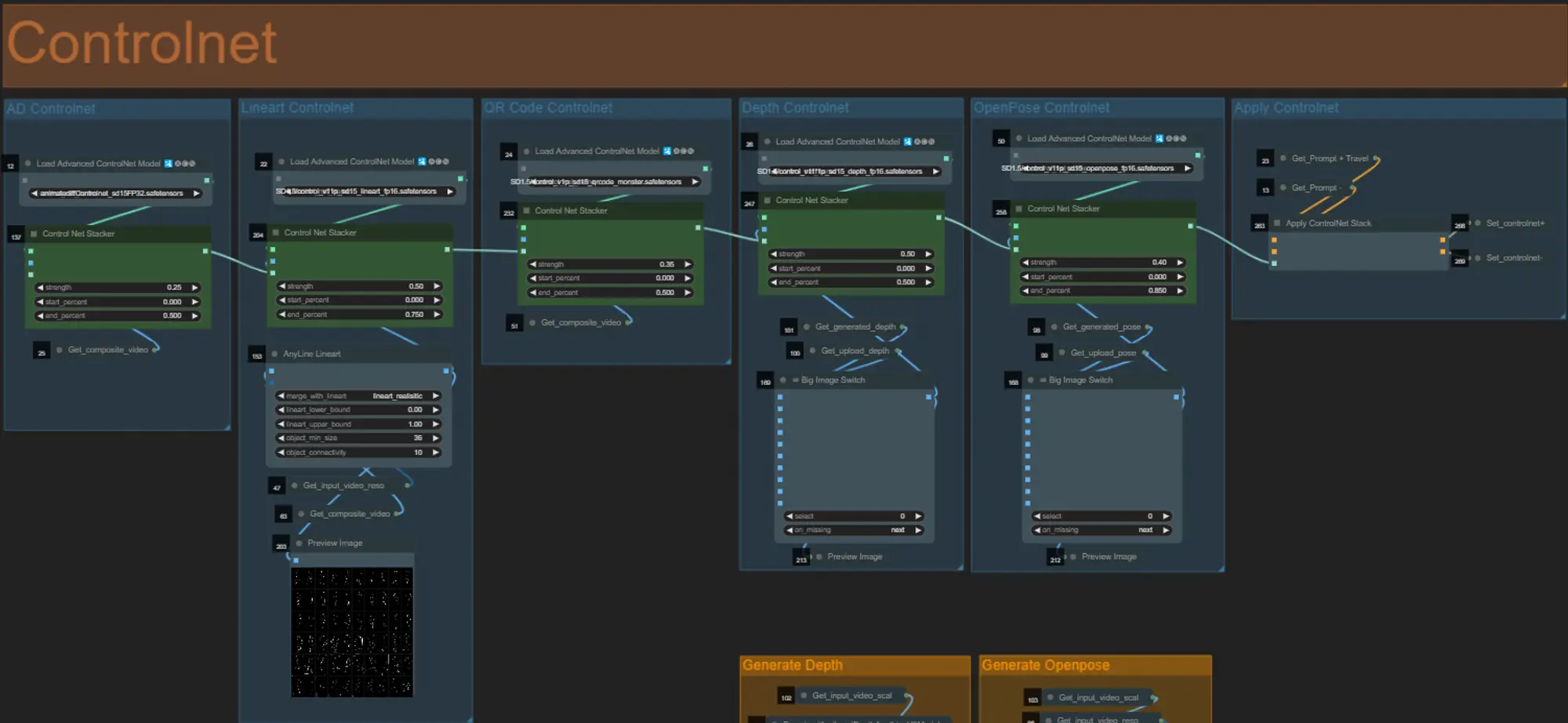
- This workflow makes use of 5 different controlnets, including AD, Lineart, QR Code, Depth, and OpenPose.
- All of the inputs to the controlnets are generated automatically
- You can choose to override the input video for the Depth and Openpose controlnets if desired by un-muting the “Override Depth” and “Override Openpose” groups as seen below:
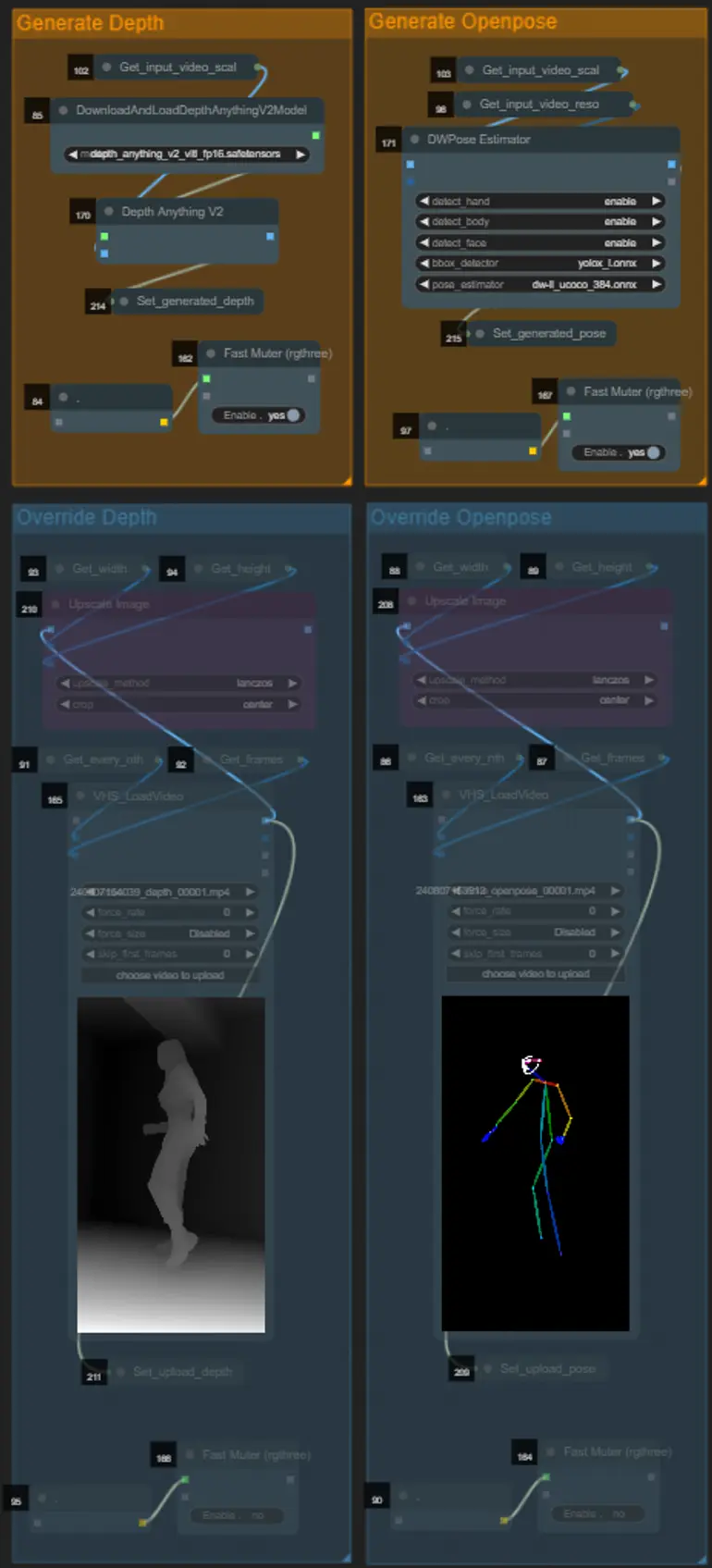
- It is recommended you mute the “Generate Depth” and “Generate Openpose” groups if overriding to save processing time.
Sampler
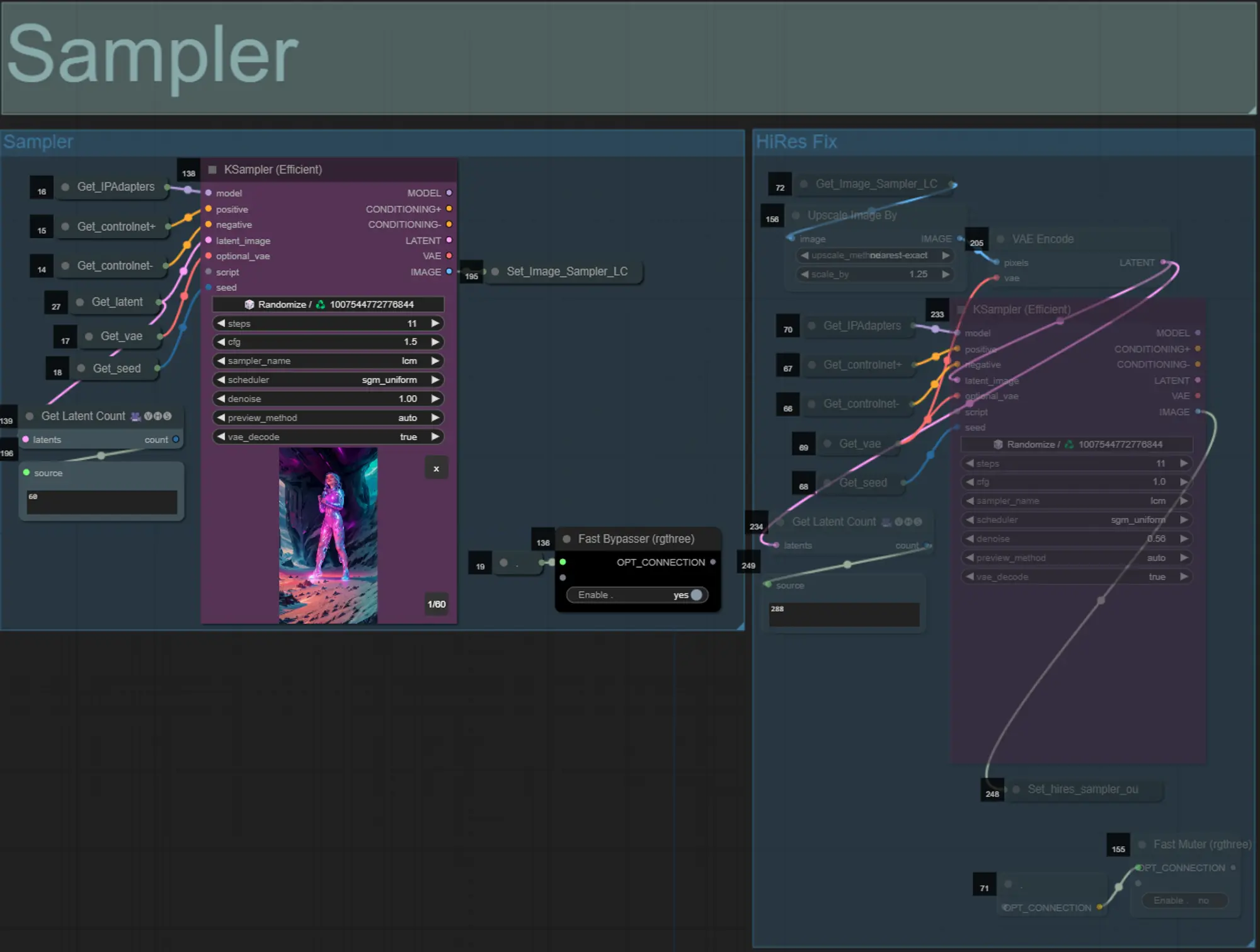
- By default the HiRes Fix sampler group will be muted to save processing time when testing
- I recommend bypassing the Sampler group as well when trying to experiment with dilation mask settings to save time.
- On final renders you can un-mute the HiRes Fix group which will upscale and add details to the final result.
Output

- There are two output groups: the left is for standard sampler output, and the right is for the HiRes Fix sampler output.
- You can change where files will be saved by changing the “custom_directory” string in the “FileNamePrefixDateDirFirst” nodes. By default this node will save output videos in a timestamped directory in the ComfyUI “output” directory
- e.g. …/ComfyUI/output/240812/
<custom_directory>/<my_video>.mp4
- e.g. …/ComfyUI/output/240812/
About Author
Akatz AI:
- Website:
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
Contacts:
- Email: akatzfey@sendysoftware.com

