Hunyuan Image to Video | Breathtaking Motion Creator
Hunyuan Image to Video is Tencent's latest image-to-video model, built on the HunyuanVideo foundation. It transforms static images into high-quality videos with smooth motion. Using image latent concatenation and a pre-trained Multimodal Large Language Model, it merges images with text prompts smoothly. HunyuanVideo I2V supports up to 720p resolution at 24fps for videos up to 5 seconds. It also enables customizable effects via LoRA training, allowing unique transformations like hair growth or emotional embraces. The Hunyuan Image to Video workflow includes wrapper nodes and native compatibility, with memory optimization through FP8 weights for efficiency.ComfyUI Hunyuan image-to-video Workflow
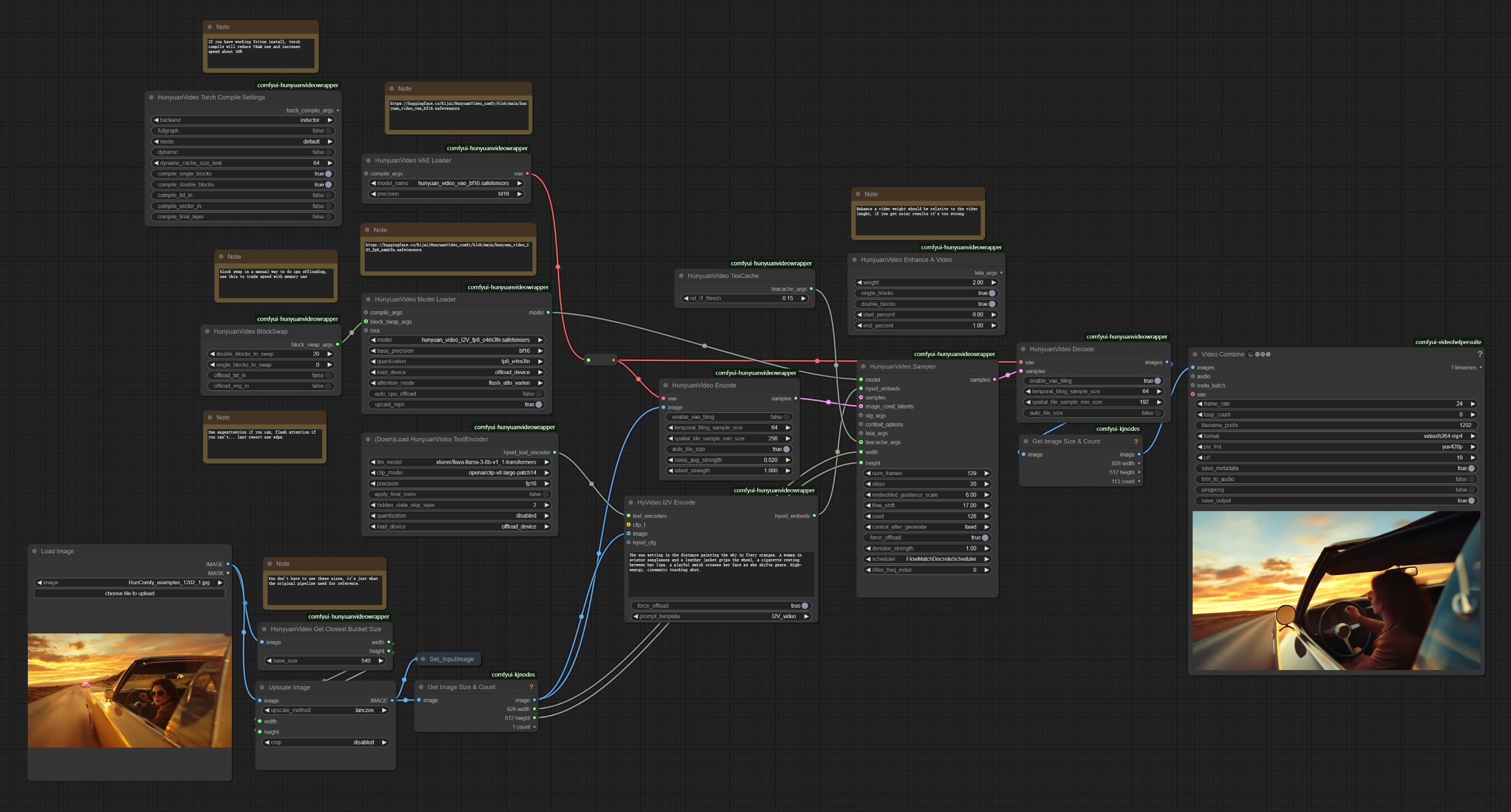
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI Hunyuan image-to-video Examples
ComfyUI Hunyuan image-to-video Description
ComfyUI Hunyuan Image-to-Video Workflow Description
1. What is Hunyuan Image-to-Video Workflow?
The Hunyuan Image-to-Video workflow is a powerful pipeline designed to transform still images into high-quality videos with natural motion. Developed by Tencent, this cutting-edge technology enables users to create cinematic animations with smooth 24fps playback at resolutions up to 720p. By leveraging latent image concatenation and a Multimodal Large Language Model, Hunyuan Image-to-Video interprets image content and applies consistent motion patterns based on text prompts.
2. Benefits of Hunyuan Image-to-Video:
- High-Resolution Output - Generates videos up to 720p at 24fps
- Natural Motion Generation - Creates fluid, realistic animations from static images
- Text-Guided Animation - Uses text prompts to guide motion and visual effects
- Cinematic Quality - Produces professional-grade videos with high fidelity
- Customizable Effects - Supports LoRA-trained effects like hair growth, facial expressions, and style adjustments
- Optimized Memory Usage - Utilizes FP8 weights for better resource management
3. How to Use Hunyuan Image-to-Video Workflow
3.1 Generation Methods with Hunyuan Image-to-Video
Example Workflow:
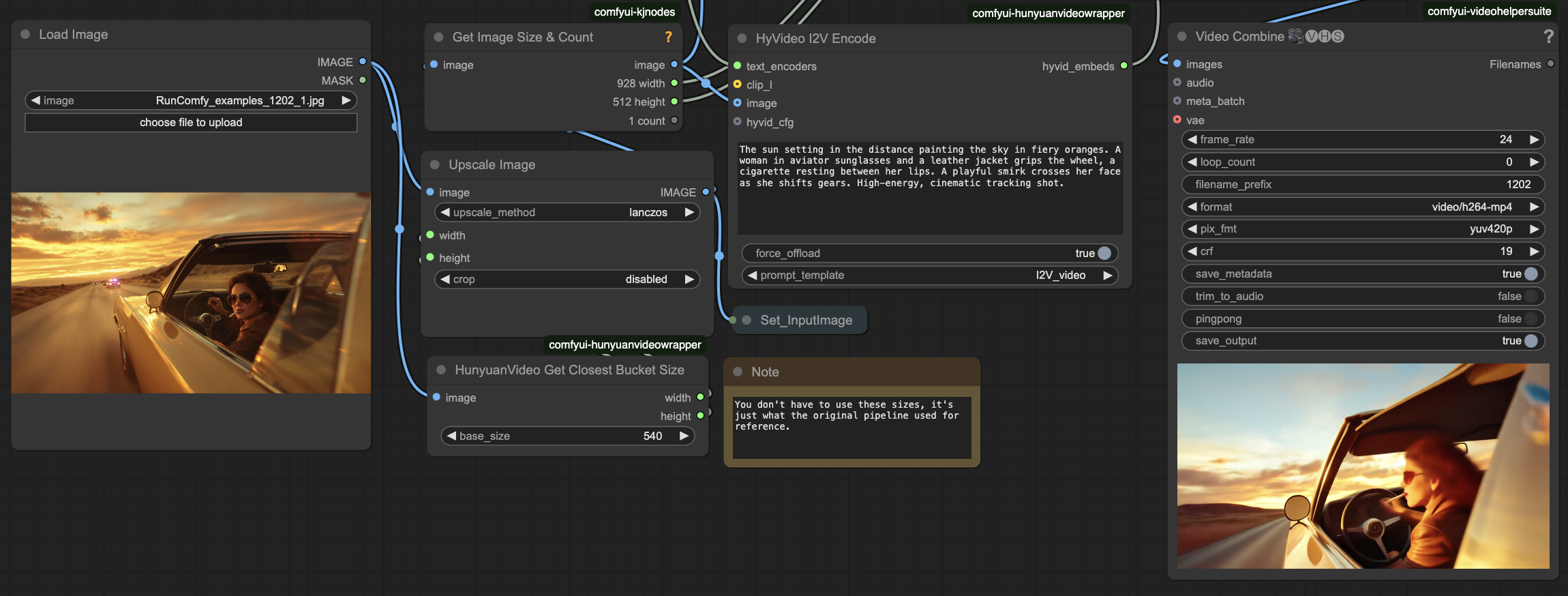
- Prepare Inputs
- In Load Image: Upload your source image
- Enter Motion Description
- In HyVideo I2V Encode: Input a descriptive text prompt for the desired motion
- Refinement (Optional)
- In HunyuanVideo Sampler: Adjust
framesto control video length (default: 129 frames ≈ 5 seconds) - In HunyuanVideo TeaCache: Modify
cache_factorfor optimized memory usage - In HunyuanVideo Enhance A Video: Enable for temporal consistency and flickering reduction
- In HunyuanVideo Sampler: Adjust
- Output
- In Video Combine: Check the preview and find saved result in ComfyUI > Output folder
3.2 Parameter Reference for Hunyuan Image-to-Video
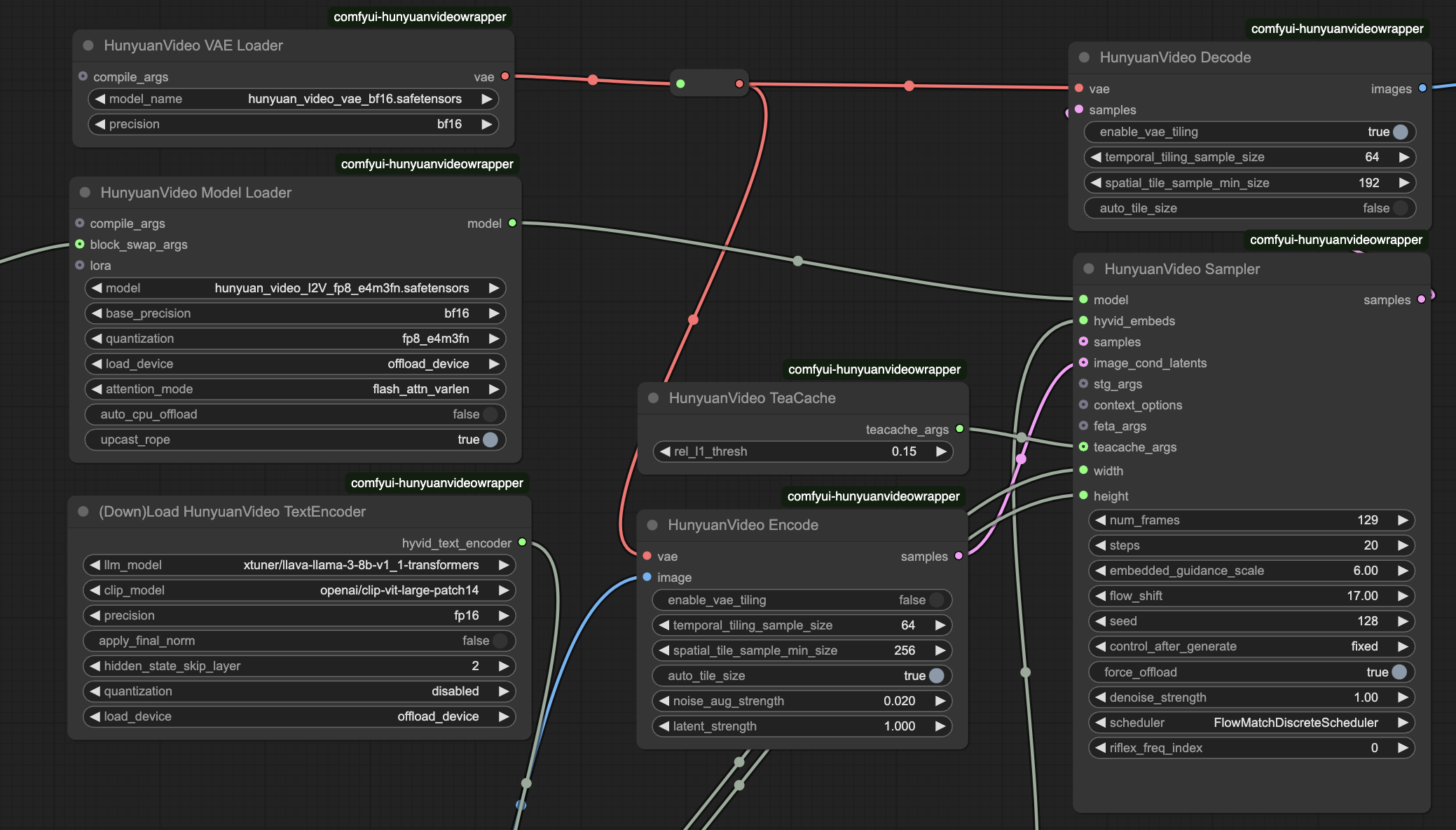
- HunyuanVideo Model Loader
model_name: hunyuan_video_I2V_fp8_e4m3fn.safetensors - Core model for image-to-video conversionweight_precision: bf16 - Defines precision level for model weightsscale_weights: fp8_e4m3fn - Optimizes memory useattention_implementation: flash_attn_varlen - Controls attention processing efficiency
- HunyuanVideo Sampler
frames: 129 - Number of frames (5.4 seconds at 24fps)steps: 20 - Sampling steps (higher values improve quality)cfg: 6 - Controls prompt adherence strengthseed: varies - Ensures generation consistency
- HyVideo I2V Encode
prompt: [text field] - Descriptive prompt for motion and styleadd_prepend: true - Enables automatic text formatting
3.3 Advanced Optimization with Hunyuan Image-to-Video
- Memory Optimization
- HunyuanVideo BlockSwap: CPU offloading for VRAM efficiency
- HunyuanVideo TeaCache: Controls cache behavior to balance memory vs. speed
- scale_weights: FP8 weights (
e4m3fn format) for memory reduction
- Speed Optimization
- HunyuanVideo Torch Compile Settings: Enables Torch compile for faster processing
- attention_implementation: Selects efficient attention mechanisms for performance boost
- offload_device: Configures GPU/CPU memory management
More Information
For more details on the Hunyuan Image-to-Video workflow, visit .
Acknowledgements
This workflow is powered by Hunyuan Image-to-Video, developed by Tencent. The ComfyUI integration includes wrapper nodes created by Kijai, enabling advanced features such as context windowing and direct image embedding support. Full credit goes to the original creators for their contributions to Hunyuan Image-to-Video workflow!
