
Hunyuan Video is an innovative open-source video foundation model that offers performance in video generation comparable to, if not better than, top closed-source models, developed by Tencent, a leading technology company. Hunyuan Video employs cutting-edge technologies for model learning, such as data curation, image-video joint model training, and an efficient infrastructure for large-scale model training and inference. Hunyuan Video boasts the largest open-source video generative model with over 13 billion parameters.
Key features of Hunyuan Video include#
- Hunyuan Video offers a unified architecture for generating both images and videos. It uses a special Transformer model design called "Dual-stream to Single-stream." This means that the model first processes the video and text information separately, and then combines them together to create the final output. This helps the model better understand the relationship between the visuals and the text description.
- The text encoder in Hunyuan Video is based on a Multimodal Large Language Model (MLLM). Compared to other popular text encoders like CLIP and T5-XXL, MLLM is better at aligning the text with the images. It can also provide more detailed descriptions and reasoning about the content. This helps Hunyuan Video generate videos that more accurately match the input text.
- To efficiently handle high-resolution and high frame rate videos, Hunyuan Video uses a 3D Variational Autoencoder (VAE) with CausalConv3D. This component compresses the videos and images into a smaller representation called the latent space. By working in this compressed space, Hunyuan Video can train on and generate videos at their original resolution and frame rate without using too much computational resources.
- Hunyuan Video includes a prompt rewrite model that can automatically adapt the user's input text to better suit the model's preferences. There are two modes available: Normal and Master. The Normal mode focuses on improving the model's understanding of the user's instructions, while the Master mode emphasizes creating videos with higher visual quality. However, the Master mode may sometimes overlook certain details in the text in favor of making the video look better.
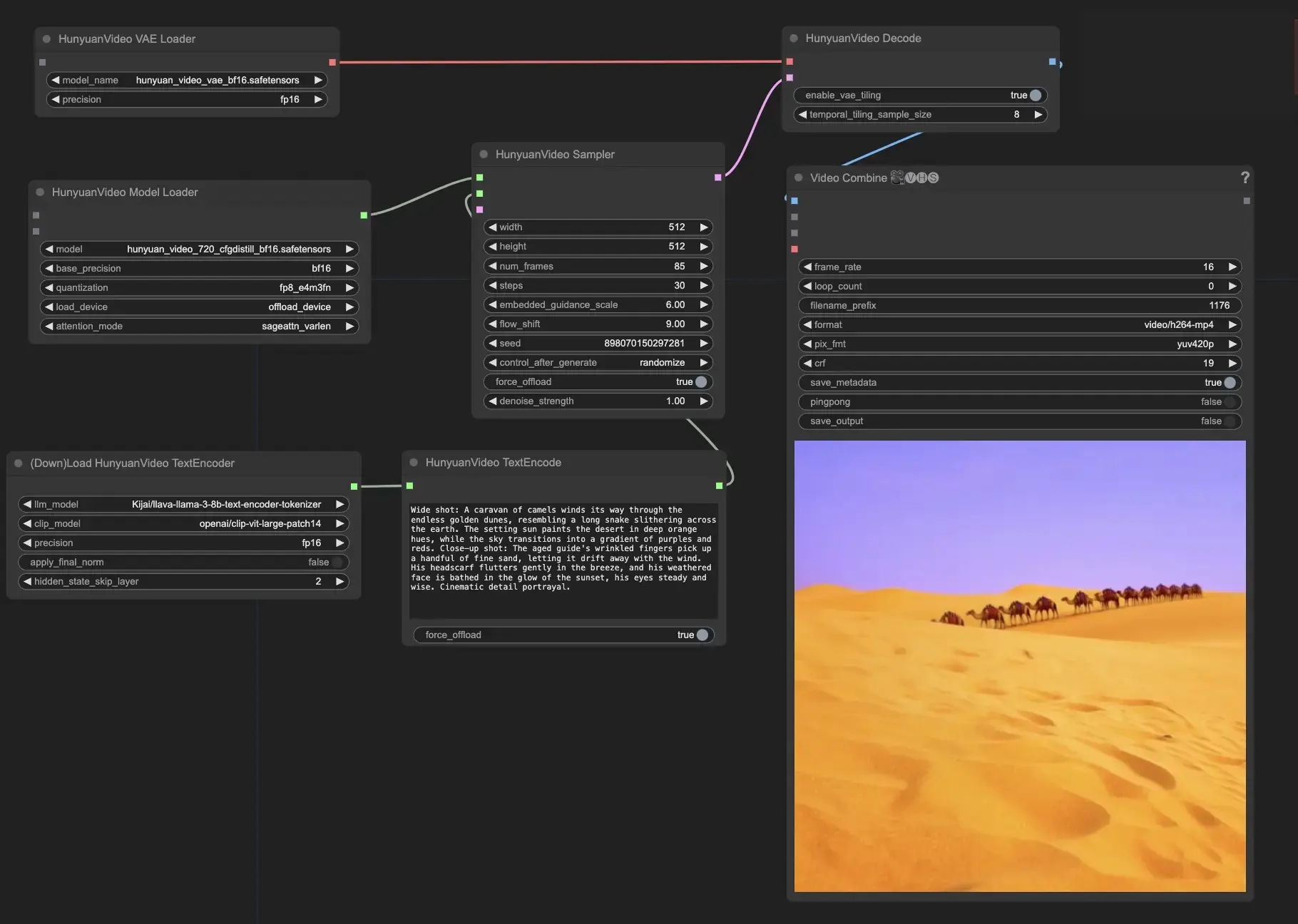
Use Hunyuan Video in ComfyUI#
This ComfyUI-HunyuanVideoWrapper nodes and related workflows was developed by Kijai. We give all due credit to Kijai for this innovative work. On the RunComfy platform, we are simply presenting his contributions to the community.
- Provide your text prompt: In the HunyuanVideoTextEncode node, enter your desired text prompt in the "prompt" field. Here are some prompt examples for your reference.
- Configure the output video settings in HunyuanVideoSampler node:
- Set the "width" and "height" to your preferred resolution
- Set the "num_frames" to the desired video length in frames
- "steps" controls the number of denoising/sampling steps (default: 30)
- "embedded_guidance_scale" determines the strength of prompt guidance (default: 6.0)
- "flow_shift" affects the video length (larger values result in shorter videos, default: 9.0)