Hunyuan Video | Image-Prompt to Video
Hunyuan IP2V is a workflow designed to convert an image and a text prompt into a video using Hunyuan Video model. While Hunyuan Video itself is a text-to-video model, this workflow allows users to generate motion from a static image, offering a creative way to animate concepts without relying solely on text descriptions. Although Hunyuan has not yet released an official image-to-video model, IP2V provides an alternative approach, making it a valuable tool for AI-driven animation, concept visualization, and creative storytelling.ComfyUI Hunyuan Video - IP2V Workflow
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI Hunyuan Video - IP2V Examples
ComfyUI Hunyuan Video - IP2V Description
Hunyuan Video is an open-source foundation model that challenges the dominance of closed-source systems by delivering cutting-edge text-to-video generation capabilities. Built on innovations in large-scale data curation, adaptive architectural design, and optimized infrastructure, Hunyuan Video sets new benchmarks in visual quality.
While Hunyuan Video primarily focuses on text-to-video generation, Hunyuan IP2V workflow extends this capability by converting image and text prompt into dynamic video through the same model. This approach enables users to steer content creation using visual references, offering an alternative method for AI-driven content production.
By combining an image with a prompt, Hunyuan IP2V generates motion while preserving the input's key characteristics, making it a useful tool for AI animation, concept visualization, and artistic storytelling. Whether crafting dynamic scenes, stylized movement, or extending static visuals into animated sequences, Hunyuan Video's framework delivers efficient pathways to high-quality results.
How to Use Hunyuan Video - IP2V Workflow?
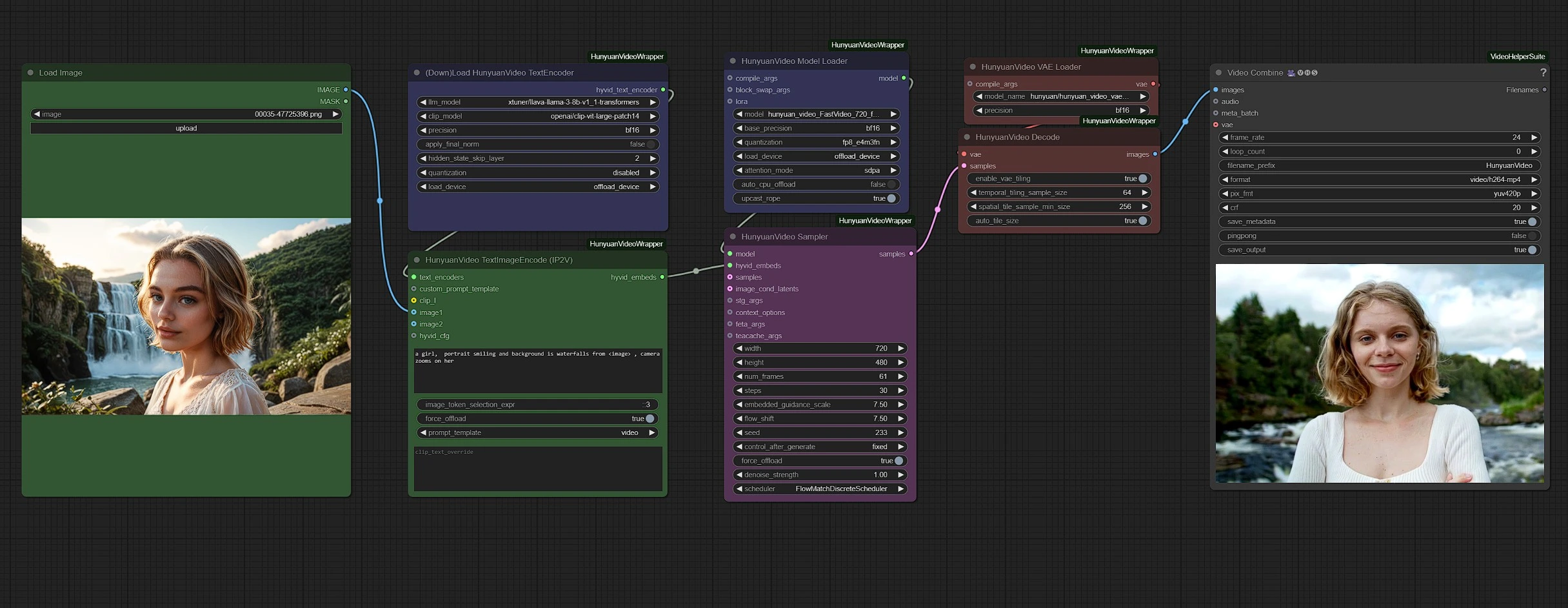
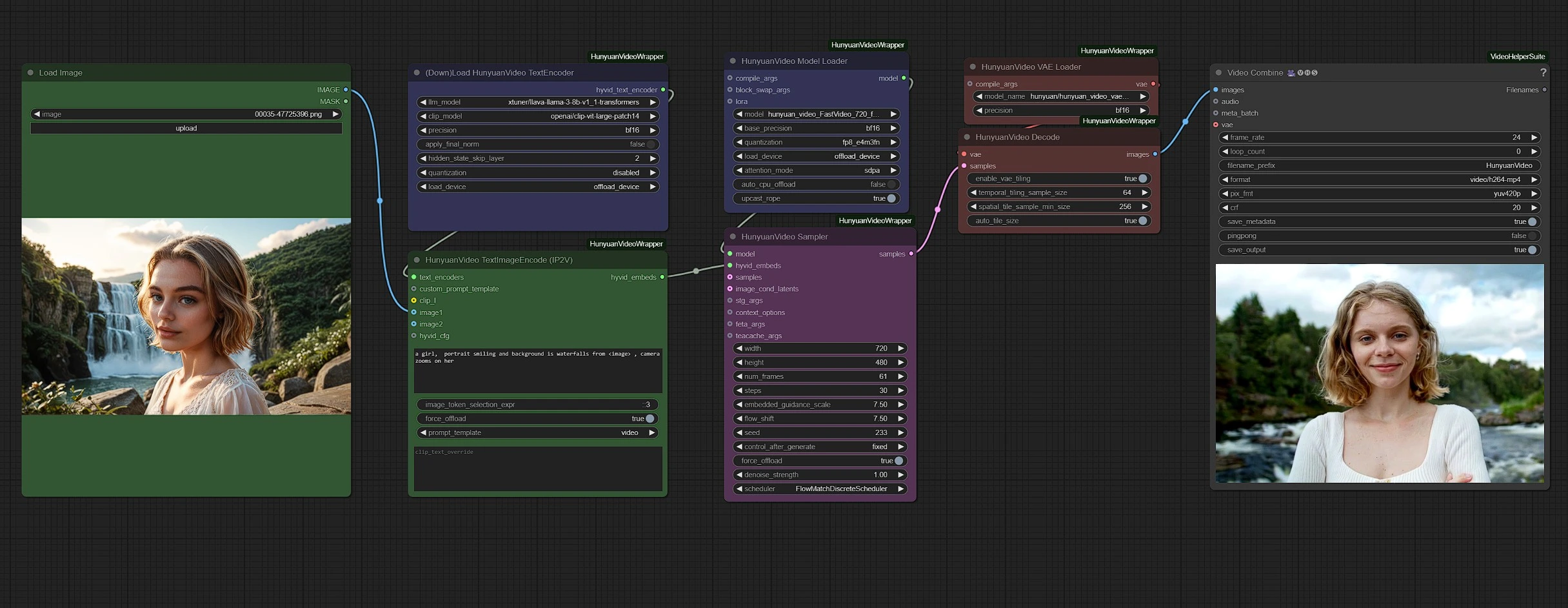
Groups are color-coded for clarity:
- Green - Inputs
- Purple - Models
- Pink - Hunyuan Sampler
- Red - VAE + Decoding
- Grey - Output
Upload your inputs (image and text) in the green nodes and adjust video settings, such as duration and resolution, in the pink sampler node.
Input 1 - Image
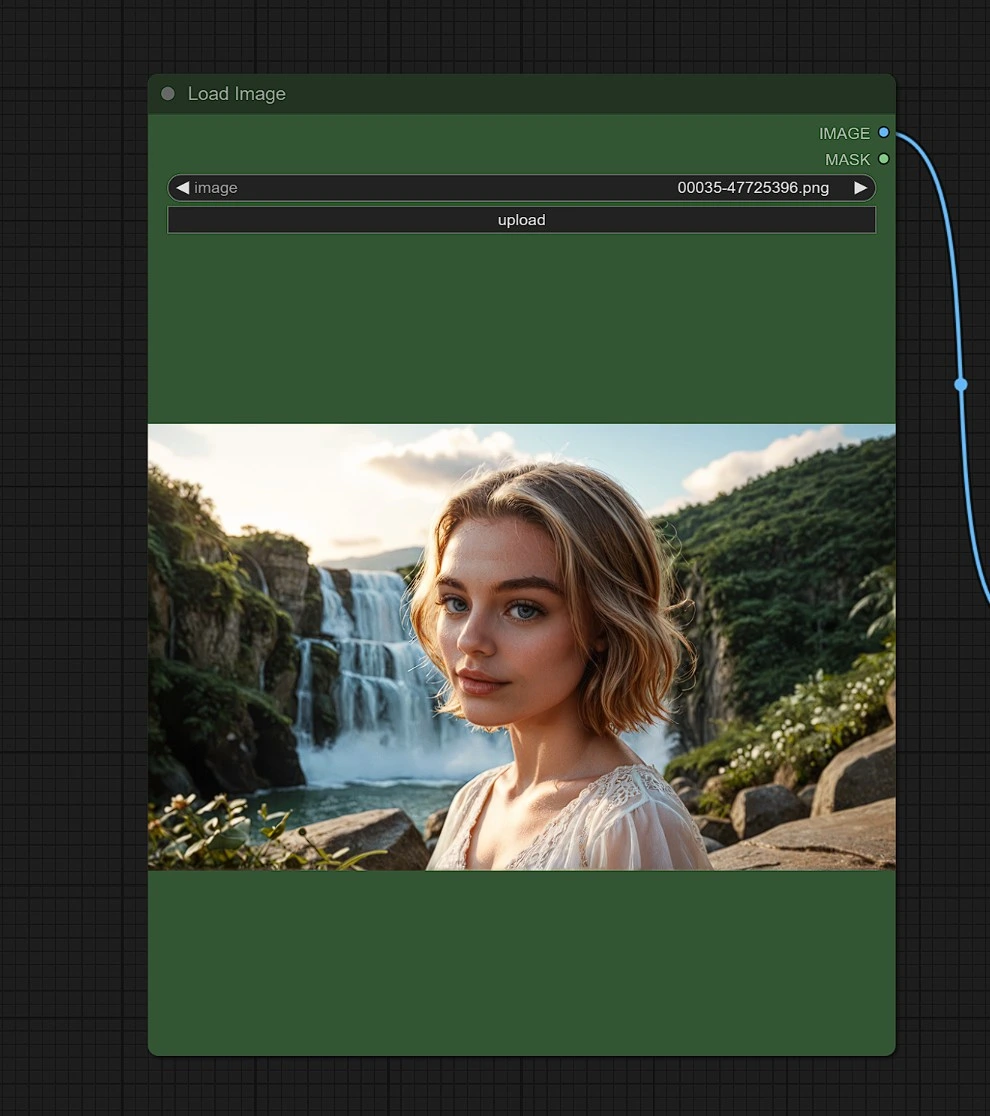
Upload an image for reference of the place, person, or object you seek similar results for.
Input 2 - Text
In the first text box, enter your prompts and include the image using the keyword "<image>".
For example, if your input is "empty street" and you want to add a woman, the prompt would be: "A portrait of a woman, background is <image>."
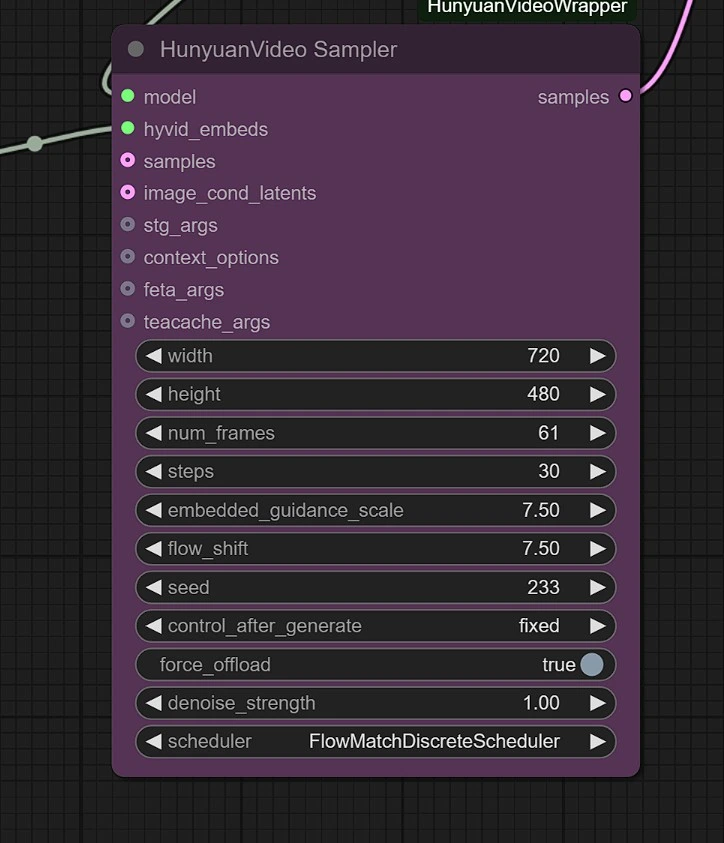
Sampler
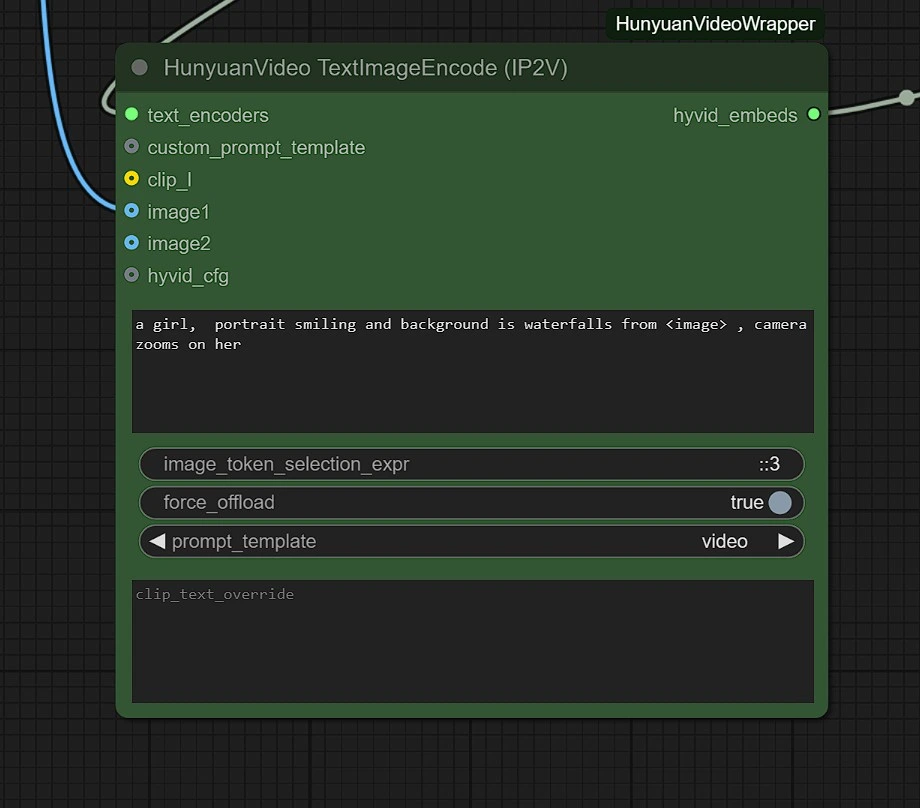
You can adjust the following:
- Image Resolution - Maximum is 1280px 720px , requiring more VRAM.
- Frames - This sets the number of frames (24 frames = 1 second).
Models
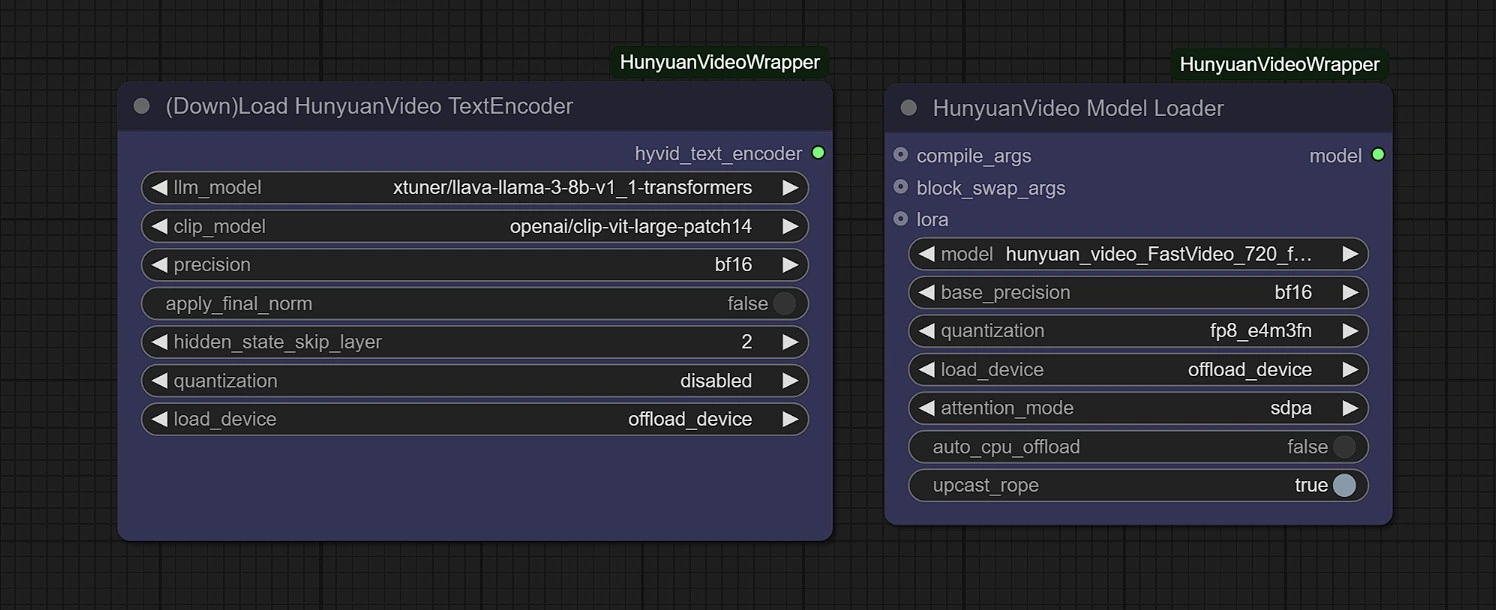
In this Group, the models will auto-download on first run. Please allow 3-5 minutes for the download to complete in your temporary storage.
Links:
- Diffusion: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
- ComfyUI > models > diffusion_models
- Vae: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensors
- ComfyUI > models > vae
Outputs
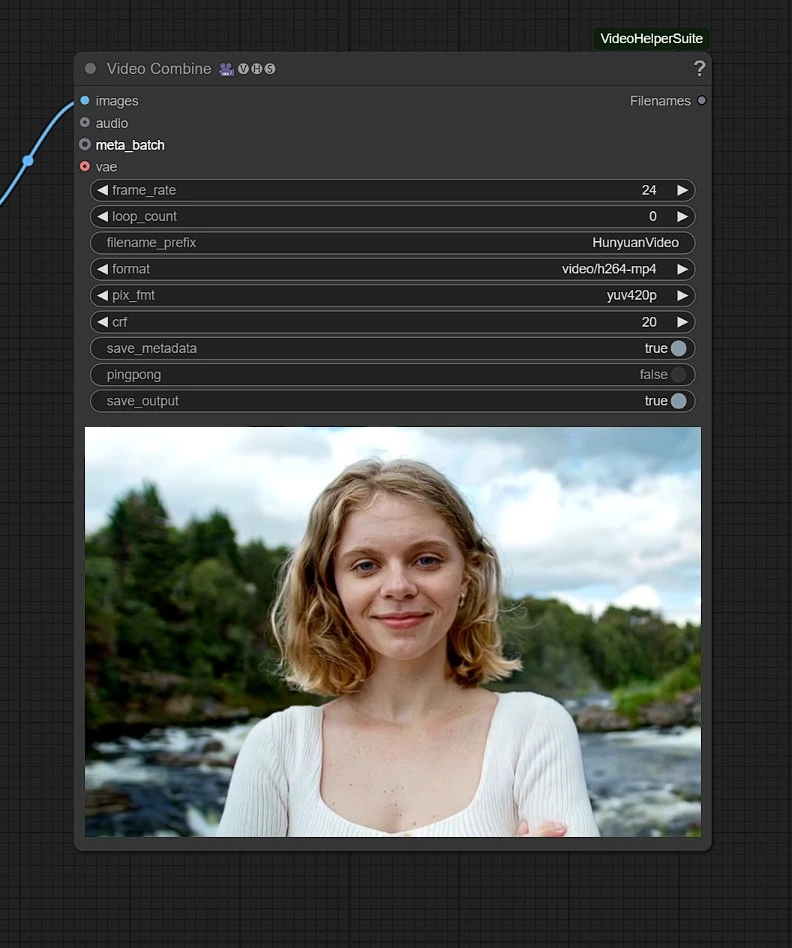
The rendered video will be saved in the Outputs folder in Comfyui.
With Hunyuan IP2V workflow, you’re not limited to text-based video generation now, you can bring your images to life with motion and style. Whether for AI filmmaking, digital art, or creative storytelling, this workflow gives you the power to shape your vision with more control than ever before.