
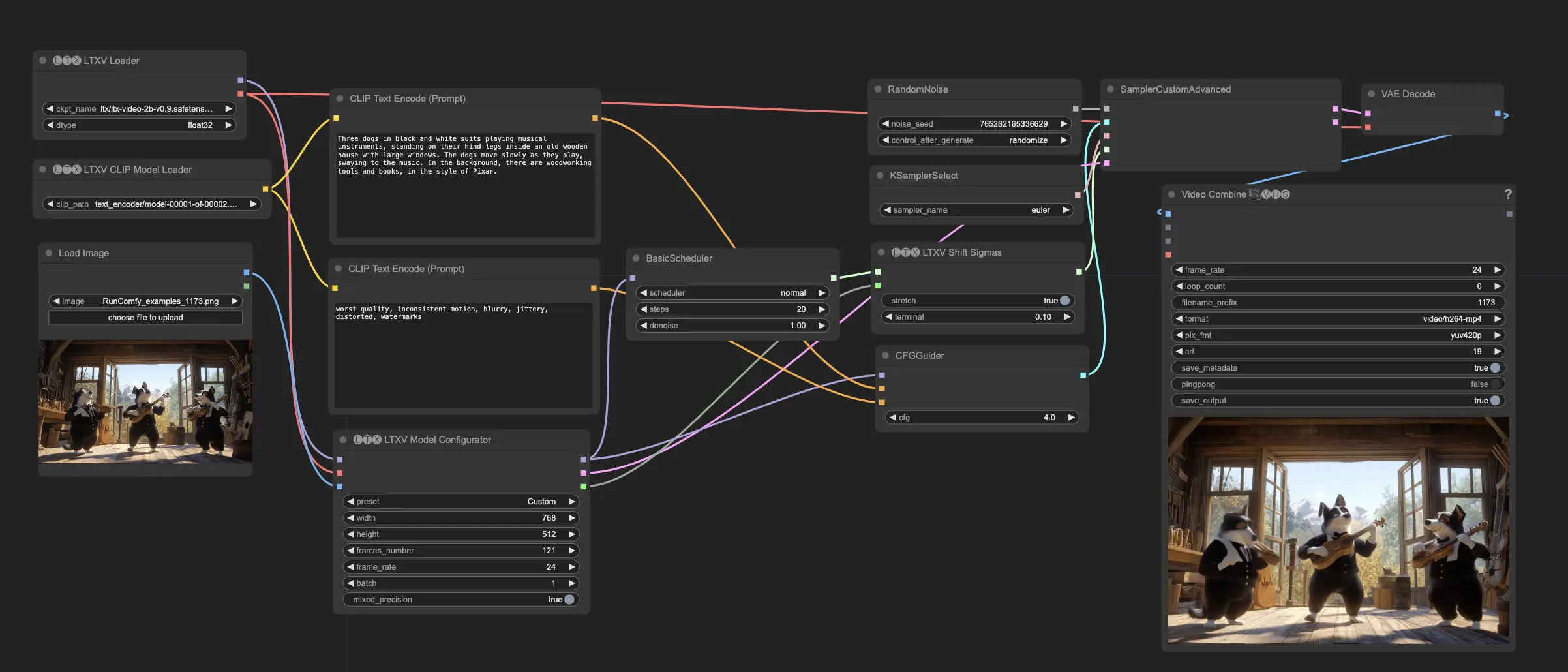
LTX Video is a diffusion-based video generation model developed by Lightricks. It is capable of generating videos from either text prompts (text-to-video) or a combination of image and text prompts (image+text-to-video). LTX Video produces 24 frames per second (FPS) videos at a resolution of 768x512 faster than they can be watched. The model has been trained on a large-scale dataset containing diverse videos, enabling it to generate realistic and varied video content at high resolutions.
LTX Video Model and ComfyUI-LTXVideo Nodes were developed by Lightricks. All credit goes to their work in creating LTX Video. For more information about LTX Video and Lightricks' projects, please visit their GitHub repository at https://github.com/Lightricks/LTX-Video or their website at https://www.lightricks.com/ltxv.
Techniques behind LTX Model#
LTX Video utilizes a Diffusion-based approach for generating videos. Diffusion models work by gradually denoising a noisy input over multiple timesteps to generate the final output. In the case of LTX Video, the model takes a noisy latent representation as input and iteratively denoises it to produce a sequence of video frames. The denoising process is guided by the provided text or image+text prompts, which control the content and style of the generated video.
The key techniques employed by LTX Video include:
- Diffusion-based video generation: By leveraging diffusion models, LTX Video can generate high-quality videos with realistic motion and consistency across frames.
- Text-to-video synthesis: LTX Video can generate videos solely based on textual descriptions, enabling users to create custom videos from scratch using natural language prompts.
- Image+text-to-video synthesis: LTX Video also supports generating videos by combining an initial image with a text prompt. This allows users to provide a starting point for the video and guide its content and style using text.
How to Use LTX Video Workflow in ComfyUI#
- Prepare the Input:
- The default workflow is image + text-to-video generation. Provide an initial image along with a text prompt. The image serves as a starting point, and the model will generate a video based on both the image and the accompanying text. Note that this model requires long, descriptive prompts; if the prompt is too short, the quality will suffer greatly.
- Configure the Model Parameters:
- Set the desired resolution and number of frames for the generated content. The resolution should be divisible by 32, and the number of frames should be divisible by 8 + 1 (e.g., 257 frames). LTX works best with resolutions under 720x1280 pixels and fewer than 257 frames.
- Adjust other parameters such as the diffusion steps, noise schedule, and guidance scale according to your requirements. These parameters control the quality and diversity of the generated output.
- Generate the Content:
- The output will have the specified resolution and number of frames, and it will align with the provided input prompt.
Limitations of LTX Model#
- LTX Video is not intended or able to provide factual information.
- As a statistical model, LTX Video might amplify existing societal biases present in the training data.
- The generated videos may not perfectly match the provided prompts.
- The quality of prompt following heavily depends on the prompting style used.
License#
Please use the model for purposes under the **license**

