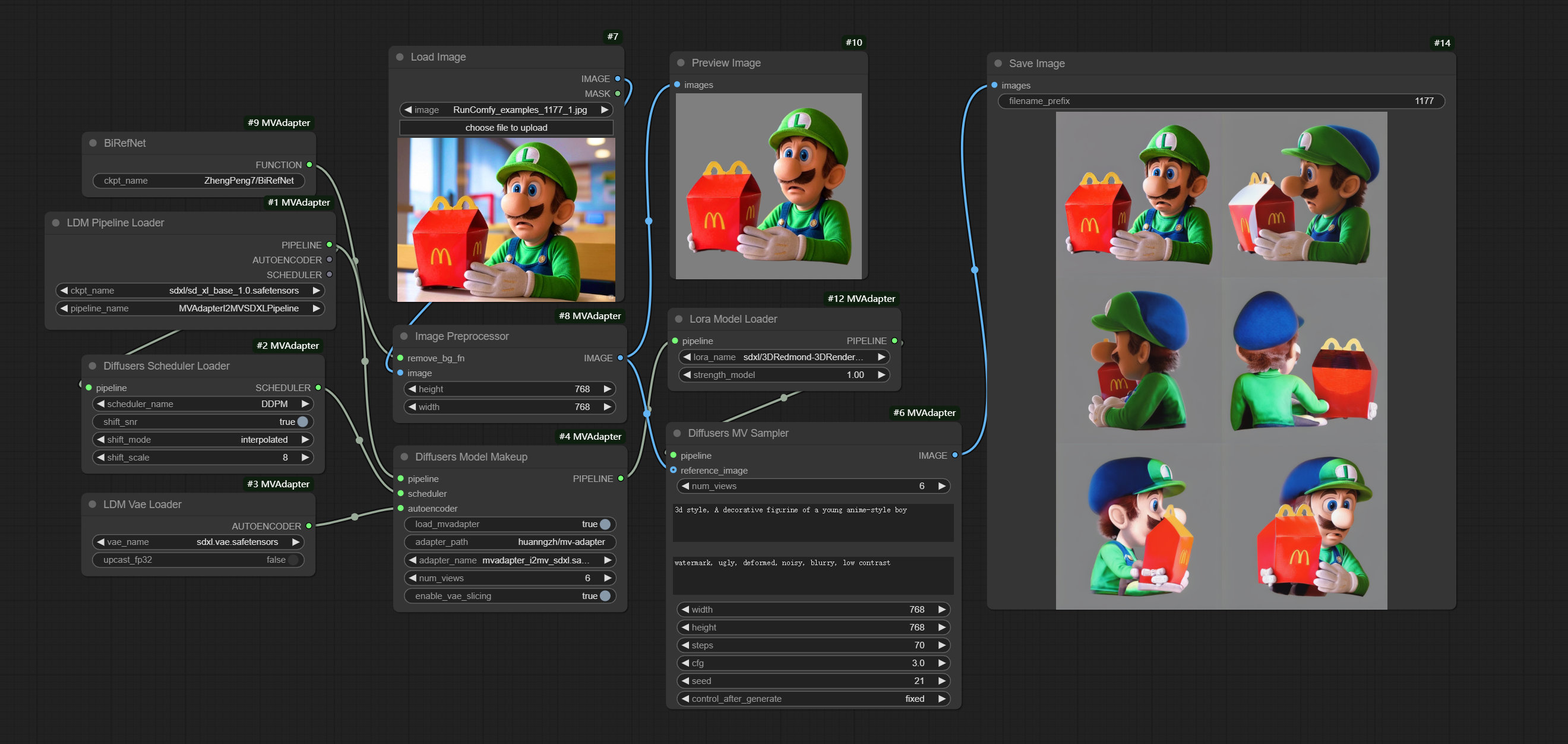
MV-Adapter | High-Resolution Multi-view Generator
ComfyUI MV-Adapter generates consistent multi-view images from a single input automatically with Stable Diffusion XL, producing professional 768px resolution outputs from either images or text prompts. The advanced MV-Adapter technology ensures view consistency while supporting both anime-style generation through Animagine XL and photorealistic renders via DreamShaper, with additional customization through LoRA and ControlNet.ComfyUI MV-Adapter Workflow
Want to run this workflow?
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI MV-Adapter Examples



ComfyUI MV-Adapter Description
1. What is the ComfyUI MV-Adapter Workflow?
The Multi-View Adapter (MV-Adapter) workflow is a specialized tool that enhances your existing AI image generators with multi-view capabilities. It acts as a plug-and-play addition that enables models like Stable Diffusion XL (SDXL) to understand and generate images from multiple angles while maintaining consistency in style, lighting, and details. Using the MV-Adapter ensures that multi-view image generation is seamless and efficient.
2. Benefits of ComfyUI MV-Adapter:
- Generate high-quality images up to 768px resolution
- Create consistent multi-view outputs from single images or text
- Preserve artistic style across all generated angles
- Works with popular models (SDXL, DreamShaper, Animagine XL)
- Supports ControlNet for precise control
- Compatible with LoRA models for enhanced styling
- Optional SD2.1 support for faster results
3. How to Use the ComfyUI MV-Adapter Workflow
3.1 Generation Methods with MV-Adapter
Combined Text and Image Generation (Recommended)
- Inputs: Both reference image and text description
- Best for: Balanced results with specific style requirements
- Characteristics:
- Combines semantic guidance with reference constraints
- Better control over final output
- Maintains reference style while following text instructions
- Example MV-Adapter workflow:
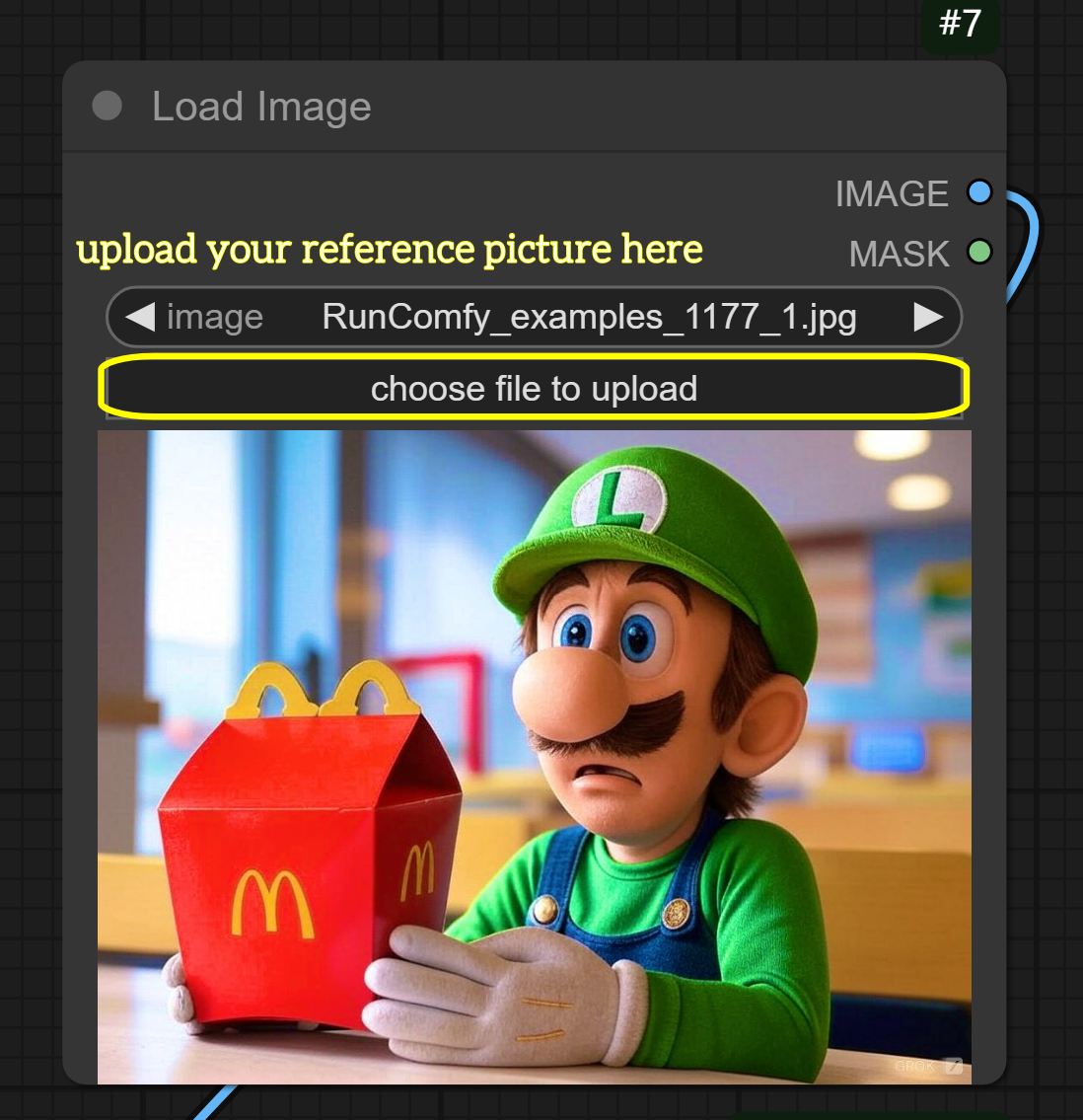
- Prepare inputs:
- Add your reference image in Load Image node
- Write descriptive text (e.g., "a space cat in the style of the reference image") in Text Encode node
- Run workflow (Queue Prompt) with default settings
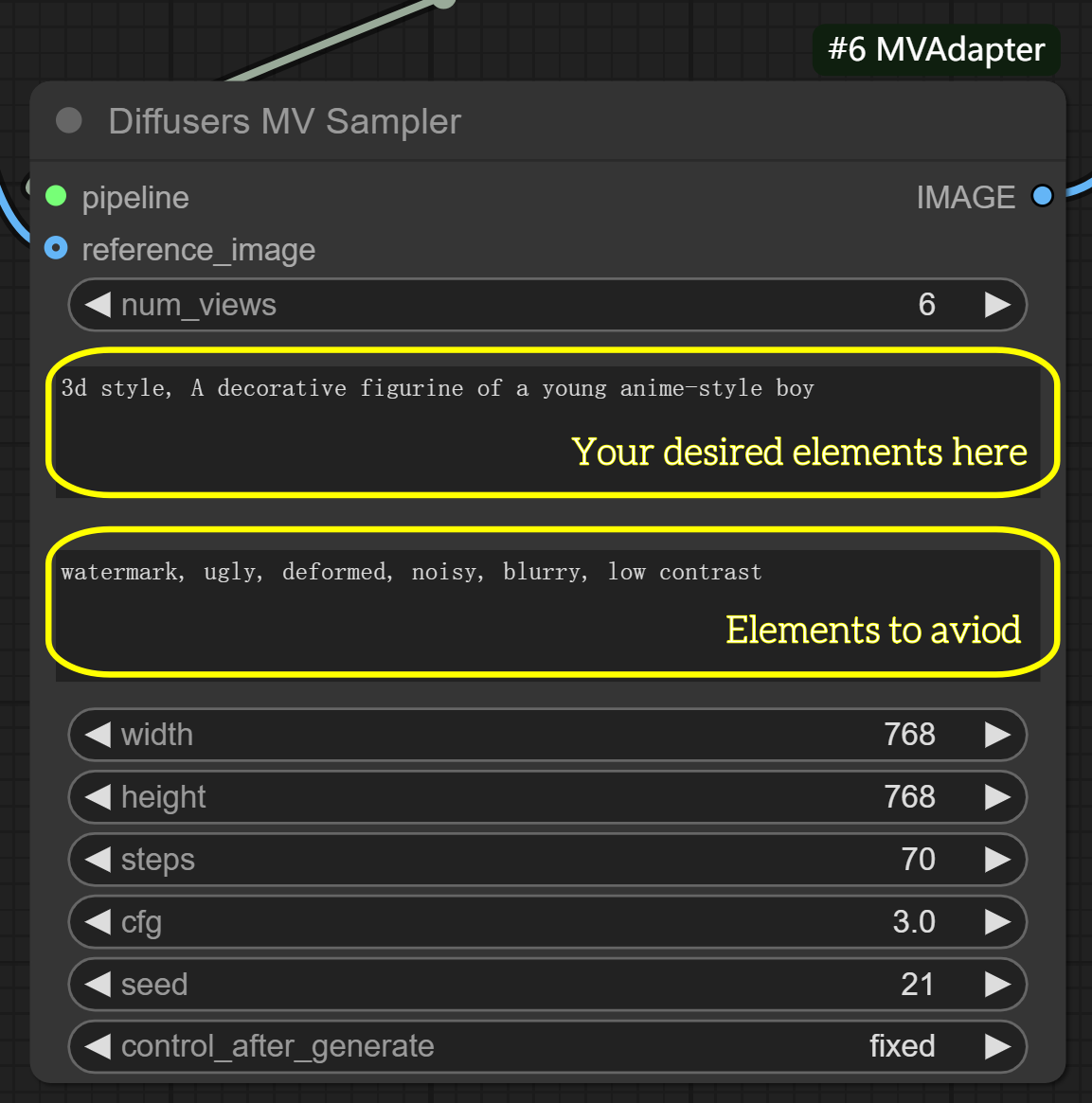
- For further refinement (optional):
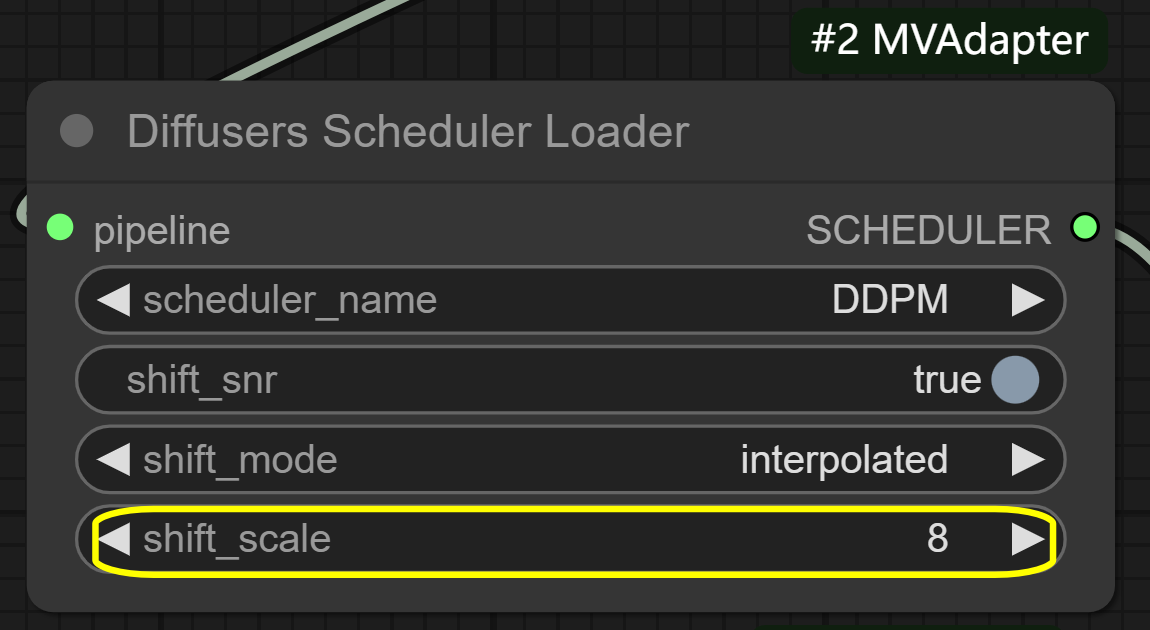
- In MVAdapter Generator node: Adjust
shift_scalefor wider/narrower angle range - In KSampler node: Modify
cfg(7–8) to balance between text and image influence
- In MVAdapter Generator node: Adjust
- Prepare inputs:
Alternative Methods in MV-Adapter:
Text-Only Generation
- Inputs: Text prompt only via Text Encode node
- Best for: Creative freedom and generating novel subjects
- Characteristics:
- Maximum flexibility in subject creation
- Output quality depends on prompt engineering
- May have less style consistency across views
- Requires detailed prompts for good results
Image-Only Generation
- Inputs: Single reference image via Load Image node
- Best for: Style preservation and texture consistency
- Characteristics:
- Strong preservation of reference image style
- High texture and visual consistency
- Limited control over semantic details
- May produce abstract results in multi-view scenarios
3.2 Parameter Reference for MV-Adapter
- MVAdapter Generator node:
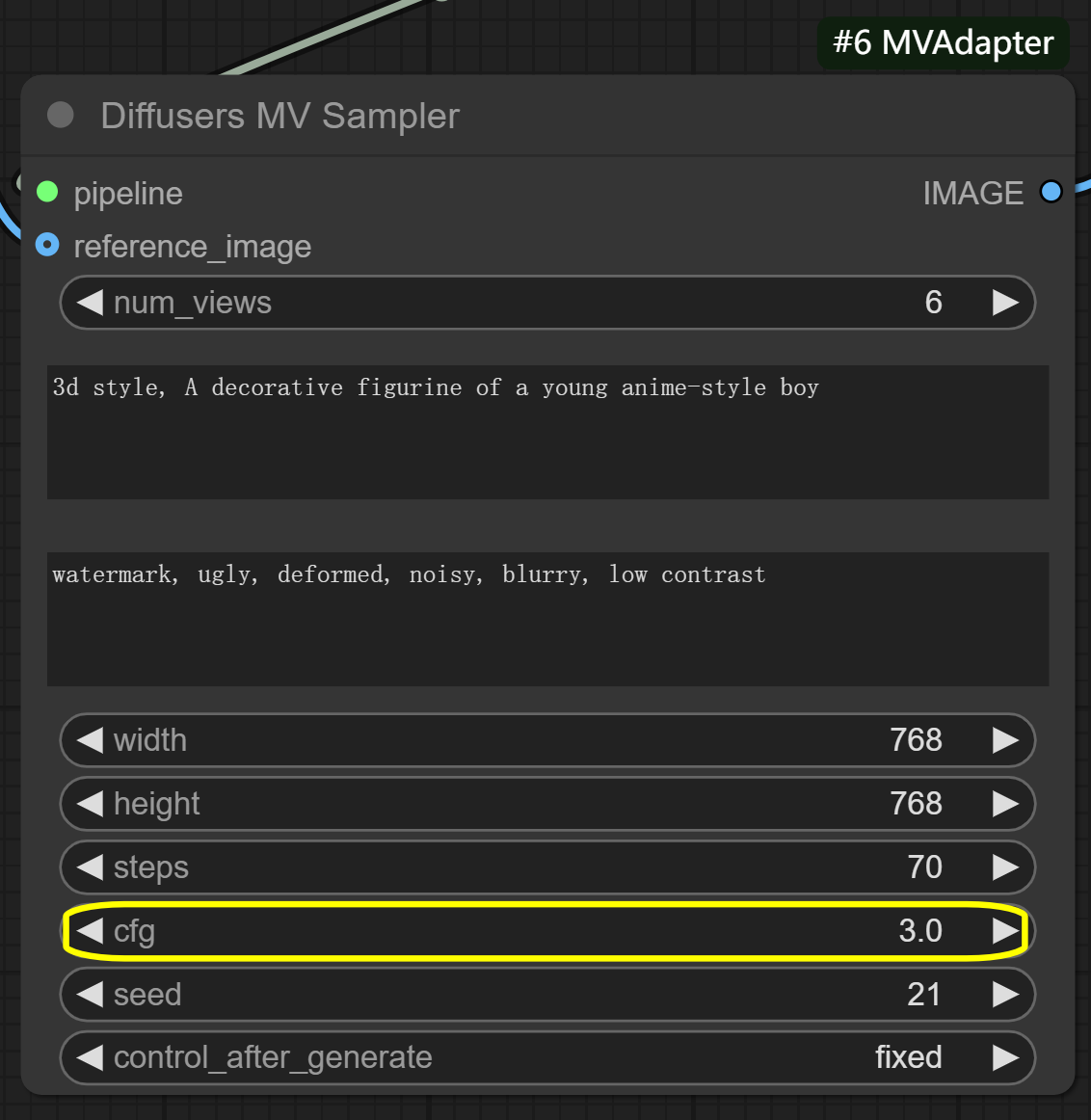
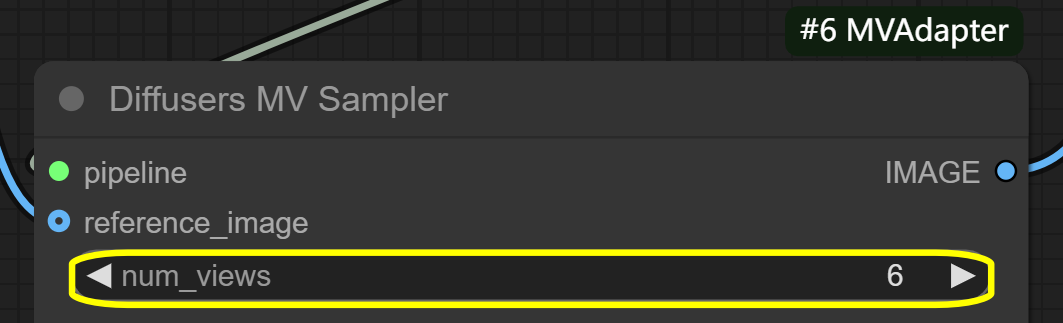
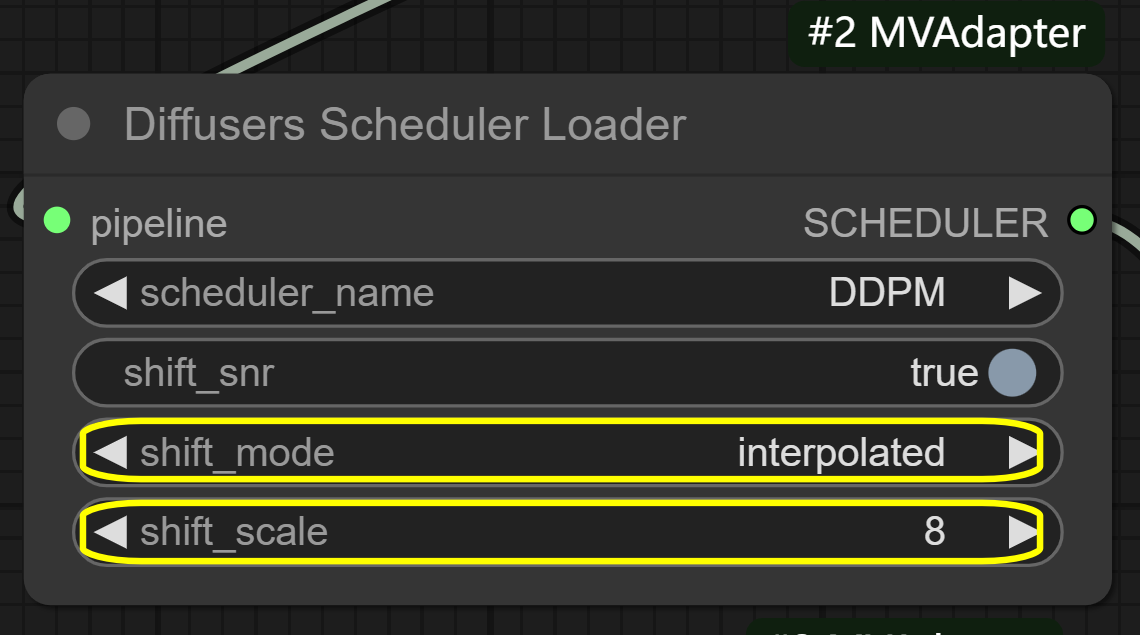
num_views: 6 (default) - controls number of generated anglesshift_mode: interpolated - controls view transition methodshift_scale: 8 (default) - controls angle range between views
- KSampler node:
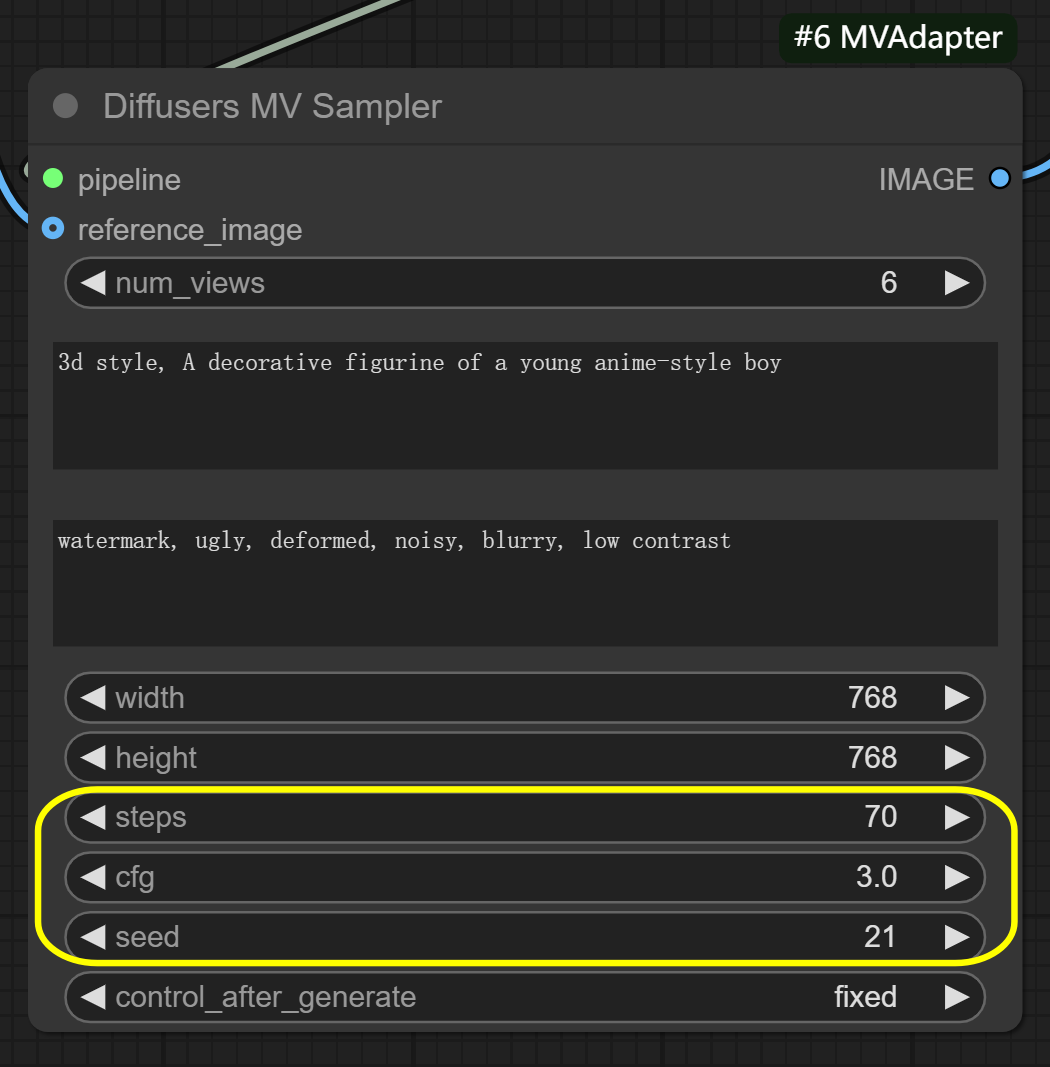
cfg: 7.0-8.0 recommended - balances input influencessteps: 40-50 for more detail (default is optimized for MV-Adapter)seed: Keep same value for consistent results
- LoRA settings (Optional):
- 3D LoRA: Apply first for structural consistency
- Style LoRA: Add after 3D effect, start at
0.5strength
3.3. Advanced Optimization with MV-Adapter
For users seeking performance improvements:
- VAE Decode node options:
- enable_vae_slicing: Reduces VRAM usage
- upcast_fp32: Affects processing speed
More Information
For additional details on the MV-Adapter workflow and updates, please visit .

