FLUX LoRA Training
Questo flusso di lavoro ComfyUI FLUX LoRA Training ti consente di affinare i modelli FLUX preesistenti con i tuoi dataset. Con questa guida dettagliata, imparerai a preparare i tuoi dati di addestramento, configurare il flusso di lavoro, configurare i parametri essenziali ed eseguire il processo di addestramento. Sblocca tutto il potenziale dei modelli di intelligenza artificiale FLUX e crea output su misura che si allineano perfettamente alla tua visione.ComfyUI FLUX LoRA Training Flusso di lavoro
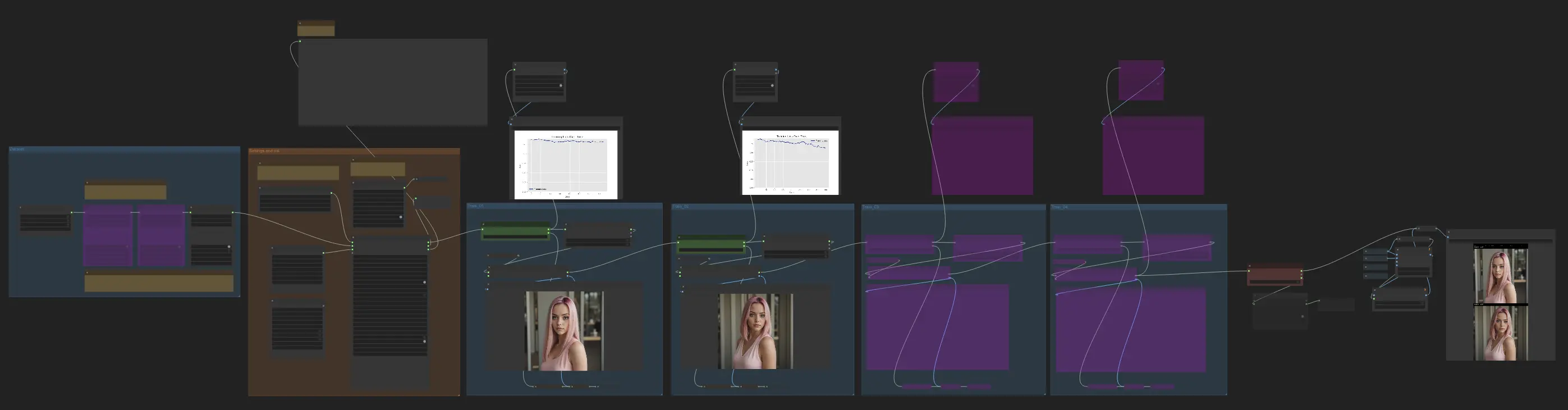
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI FLUX LoRA Training Esempi

ComfyUI FLUX LoRA Training Descrizione
FLUX LoRA ha guadagnato un'enorme popolarità nella comunità AI, in particolare tra coloro che cercano di affinare i modelli AI con i propri dataset. Questo approccio ti consente di adattare senza sforzo i modelli FLUX preesistenti ai tuoi dataset unici, rendendolo altamente personalizzabile ed efficiente per una vasta gamma di progetti creativi. Se sei già familiare con ComfyUI, utilizzare il flusso di lavoro ComfyUI FLUX LoRA Training per addestrare il tuo modello FLUX LoRA sarà un gioco da ragazzi. Il flusso di lavoro e i nodi correlati sono stati creati da Kijai, quindi un grande grazie a lui per il suo contributo! Dai un'occhiata al per maggiori informazioni.
Tutorial ComfyUI FLUX LoRA Training
Il flusso di lavoro ComfyUI FLUX LoRA Training è un processo potente progettato per addestrare modelli FLUX LoRA. L'addestramento con ComfyUI offre diversi vantaggi, in particolare per gli utenti già familiari con la sua interfaccia. Con FLUX LoRA Training, puoi utilizzare gli stessi modelli impiegati per l'inferenza, assicurando che non ci siano problemi di compatibilità quando lavori nello stesso ambiente Python. Inoltre, puoi costruire flussi di lavoro per confrontare diverse impostazioni, migliorando il tuo processo di addestramento. Questo tutorial ti guiderà attraverso i passaggi per configurare e utilizzare FLUX LoRA Training in ComfyUI.
Coprirà:
- Preparare il tuo dataset per FLUX LoRA Training
- Il processo di FLUX LoRA Training
- Eseguire FLUX LoRA Training
- Come e dove utilizzare i modelli FLUX e FLUX LoRA
1. Preparare il tuo dataset per FLUX LoRA Training
Quando prepari i tuoi dati di addestramento per FLUX LoRA Training, è essenziale avere immagini di alta qualità per il tuo soggetto target.
In questo esempio, stiamo addestrando un modello FLUX LoRA per generare immagini di un influencer specifico. Per questo, avrai bisogno di un set di immagini di alta qualità dell'influencer in varie pose e ambientazioni. Un modo conveniente per raccogliere queste immagini è utilizzare il , che rende facile generare una raccolta di immagini che mostrano lo stesso personaggio in diverse pose mantenendo il loro aspetto coerente. Per il nostro dataset di addestramento, abbiamo selezionato cinque immagini di alta qualità dell'influencer in varie pose e ambientazioni, assicurando che il dataset sia abbastanza robusto per FLUX LoRA Training per apprendere i dettagli intricati necessari per produrre output coerenti e accurati.
Processo per ottenere i dati di addestramento
Esempio di dati di addestramento

Puoi anche raccogliere il tuo dataset in base alle tue esigenze specifiche——FLUX LoRA Training è flessibile e funziona con vari tipi di dati.
2. Il processo di FLUX LoRA Training
Il flusso di lavoro FLUX LoRA Training è composto da diversi nodi chiave che lavorano insieme per addestrare e validare il tuo modello. Ecco una panoramica dettagliata dei principali nodi, suddivisi in tre parti: Dataset, Impostazioni e Inizializzazione, e Addestramento.
2.1. Impostare i dataset per FLUX LoRA Training
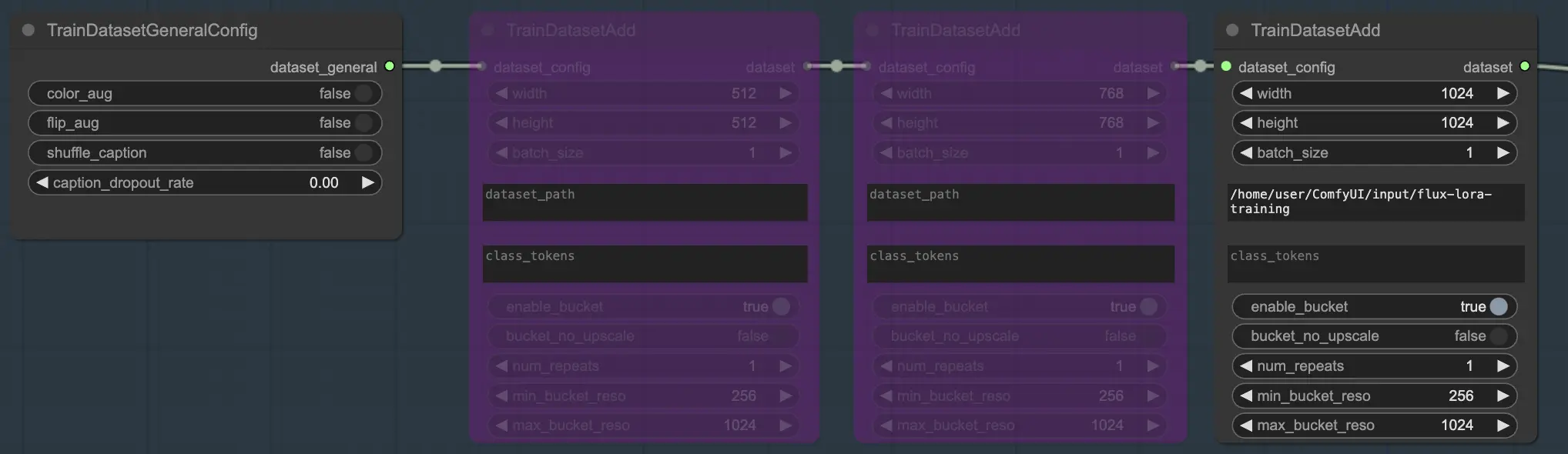
La sezione Dataset è composta da due nodi essenziali che ti aiutano a configurare e personalizzare i tuoi dati di addestramento: TrainDatasetGeneralConfig e TrainDatasetAdd.
2.1.1. TrainDatasetGeneralConfig
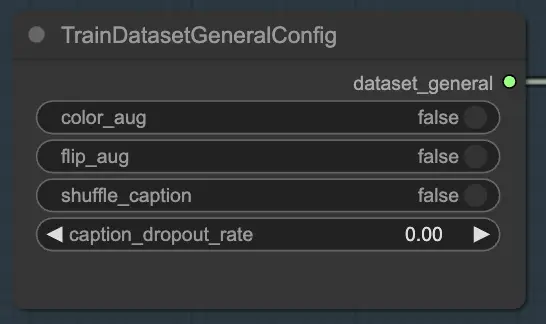
Il nodo TrainDatasetGeneralConfig è dove definisci le impostazioni generali per il tuo dataset di addestramento in FLUX LoRA Training. Questo nodo ti dà il controllo su vari aspetti dell'augmentazione e della pre-elaborazione dei dati. Ad esempio, puoi scegliere di abilitare o disabilitare l'augmentazione dei colori, che può aiutare a migliorare la capacità del modello di generalizzare su diverse variazioni di colore. Allo stesso modo, puoi abilitare l'augmentazione del flip per capovolgere casualmente le immagini orizzontalmente, fornendo campioni di addestramento più diversificati. Inoltre, hai la possibilità di mescolare le didascalie associate a ciascuna immagine, introducendo casualità e riducendo l'overfitting. Il tasso di dropout delle didascalie ti consente di eliminare casualmente le didascalie durante l'addestramento, il che può aiutare il modello a diventare più robusto a didascalie mancanti o incomplete.
2.1.2. TrainDatasetAdd
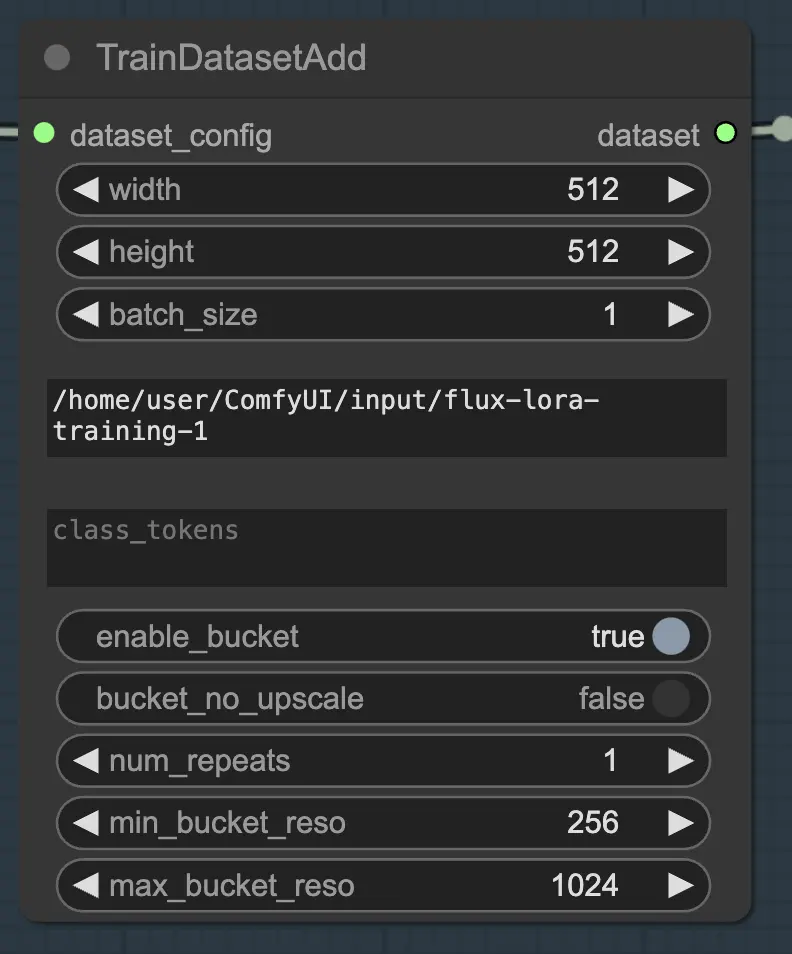
Il nodo TrainDatasetAdd è dove specifichi i dettagli di ciascun dataset individuale da includere nel tuo FLUX LoRA Training.
Directory di input: Percorso del dataset di addestramento
Per sfruttare al massimo questo nodo, è importante organizzare correttamente i tuoi dati di addestramento. Quando utilizzi il file browser di RunComfy, posiziona i dati di addestramento nella directory /home/user/ComfyUI/input/{file-name}, dove {file-name} è un nome significativo che assegni al tuo dataset.
Una volta posizionati i tuoi dati di addestramento nella directory appropriata, devi fornire il percorso a quella directory nel parametro image_dir del nodo TrainDatasetAdd. Questo indica al nodo dove trovare le tue immagini di addestramento.
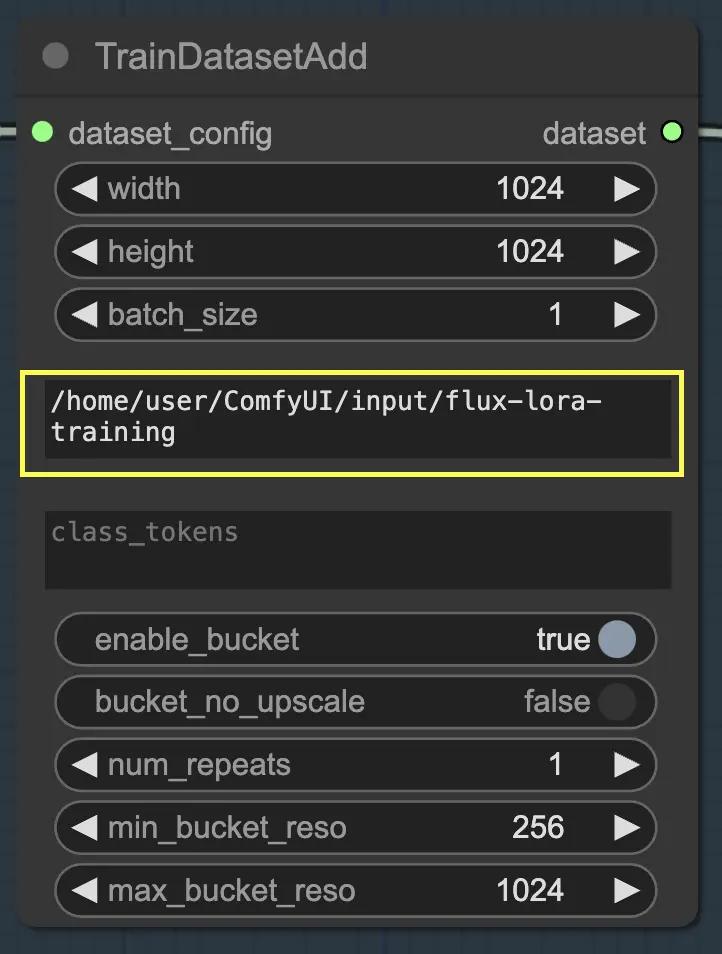
Token di classe
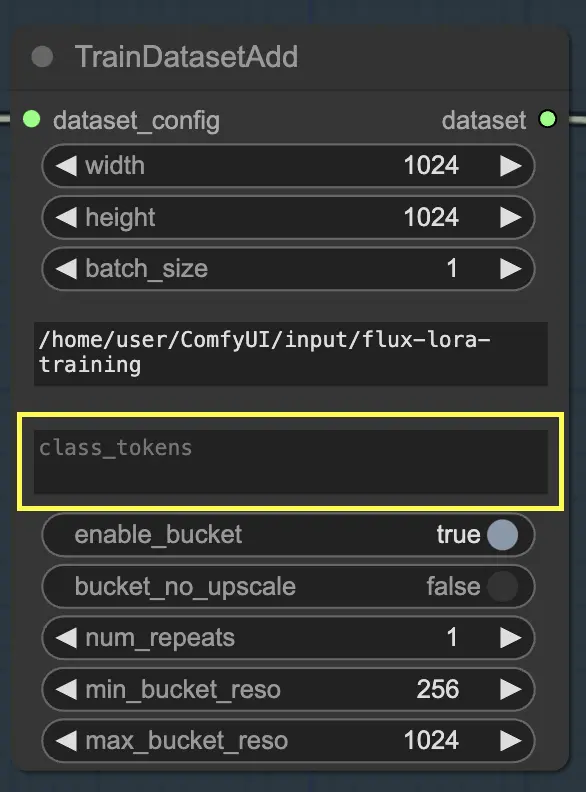
Se il tuo dataset beneficia dell'uso di token di classe specifici o parole chiave, puoi inserirli nel parametro class_tokens. I token di classe sono parole o frasi speciali che vengono preposte a ciascuna didascalia e aiutano a guidare il processo di generazione del modello. Ad esempio, se stai addestrando su un dataset di varie specie animali, potresti utilizzare token di classe come "dog", "cat" o "bird" per indicare l'animale desiderato nelle immagini generate. Quando successivamente utilizzi questi token di classe nei tuoi prompt, puoi controllare quali aspetti specifici desideri che il modello generi.
Imposta la risoluzione (larghezza e altezza), dimensione del batch
Oltre ai parametri image_dir e class_tokens, il nodo TrainDatasetAdd offre diverse altre opzioni per affinare il tuo dataset. Puoi impostare la risoluzione (larghezza e altezza) delle immagini, specificare la dimensione del batch per l'addestramento e determinare il numero di volte in cui il dataset deve essere ripetuto per epoca.
Molteplici dataset
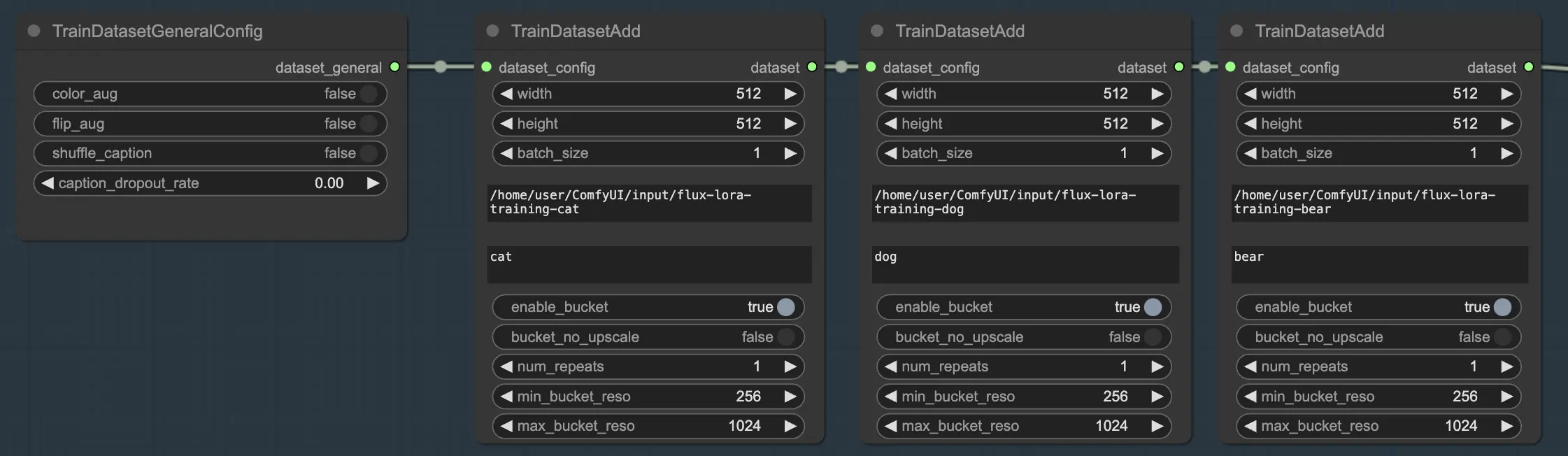
Una delle potenti caratteristiche di FLUX LoRA Training è la capacità di combinare senza problemi più dataset. Nel flusso di lavoro FLUX LoRA Training, ci sono tre nodi TrainDatasetAdd collegati in sequenza. Ciascun nodo rappresenta un dataset distinto con le proprie impostazioni uniche. Collegando questi nodi insieme, puoi creare un set di addestramento ricco e diversificato che incorpora immagini e didascalie da varie fonti.
Per illustrare questo, consideriamo uno scenario in cui hai tre dataset separati: uno per gatti, uno per cani e un altro per orsi. Puoi configurare tre nodi TrainDatasetAdd, ciascuno dedicato a uno di questi dataset. Nel primo nodo, specificheresti il percorso del dataset "cats" nel parametro image_dir, imposteresti il class token su "cat" e regoleresti altri parametri come la risoluzione e la dimensione del batch in base alle tue esigenze. Allo stesso modo, configureresti il secondo e il terzo nodo per i dataset "dogs" e "bears", rispettivamente.
Questo approccio consente al processo di FLUX LoRA Training di sfruttare una gamma diversificata di immagini, migliorando la capacità del modello di generalizzare su diverse categorie.
Esempio
Nel nostro esempio, utilizziamo un solo dataset per addestrare il modello, quindi abilitiamo un nodo TrainDatasetAdd e bypassiamo gli altri due. Ecco come puoi configurarlo:
2.2. Impostazioni e Inizializzazione
La sezione Impostazioni e Inizializzazione è dove configuri i componenti chiave e i parametri per FLUX LoRA Training. Questa sezione include diversi nodi essenziali che lavorano insieme per configurare il tuo ambiente di addestramento.
2.2.1. FluxTrainModelSelect
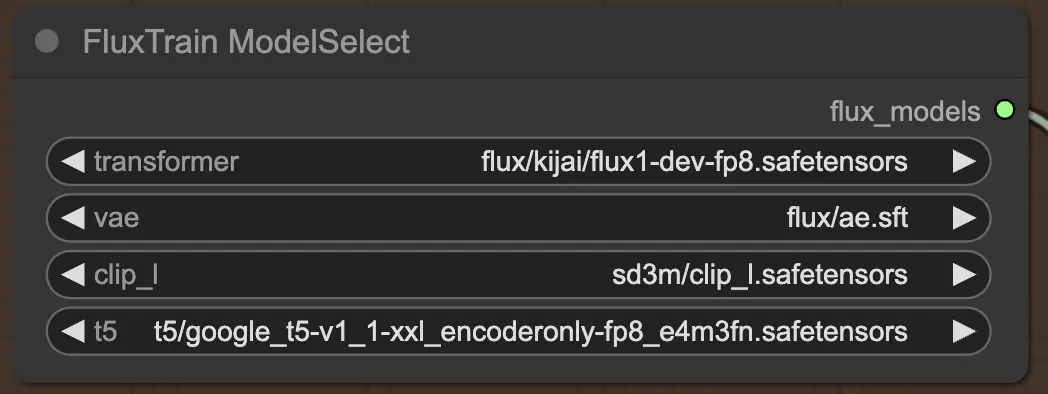
Per prima cosa, hai il nodo FluxTrainModelSelect, che è responsabile della selezione dei modelli FLUX che verranno utilizzati durante FLUX LoRA Training. Questo nodo ti consente di specificare i percorsi verso quattro modelli critici: il transformer, VAE (Variational Autoencoder), CLIP_L (Contrastive Language-Image Pre-training) e T5 (Text-to-Text Transfer Transformer). Questi modelli formano la spina dorsale del processo di addestramento FLUX e sono tutti configurati sulla piattaforma RunComfy.
2.2.2. OptimizerConfig
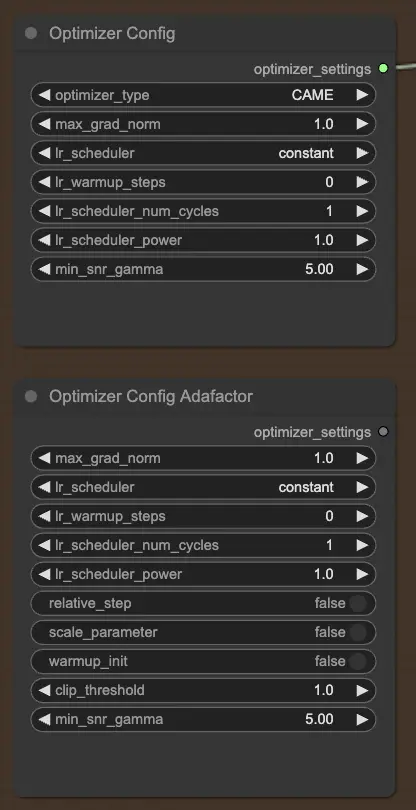
Il nodo OptimizerConfig è cruciale per configurare l'ottimizzatore all'interno di FLUX LoRA Training, che determina come vengono aggiornati i parametri del modello durante l'addestramento. Puoi scegliere il tipo di ottimizzatore (ad esempio, AdamW, CAME), impostare la norma massima del gradiente per il clipping dei gradienti per prevenire gradienti esplosivi e selezionare il regolatore del tasso di apprendimento (ad esempio, costante, coseno decrescente). Inoltre, puoi affinare i parametri specifici dell'ottimizzatore come i passi di warmup e la potenza del regolatore, e fornire argomenti extra per ulteriori personalizzazioni.
Se preferisci l'ottimizzatore Adafactor, noto per la sua efficienza di memoria e capacità di gestire modelli di grandi dimensioni, puoi utilizzare il nodo OptimizerConfigAdafactor.
2.2.3. InitFluxLoRATraining
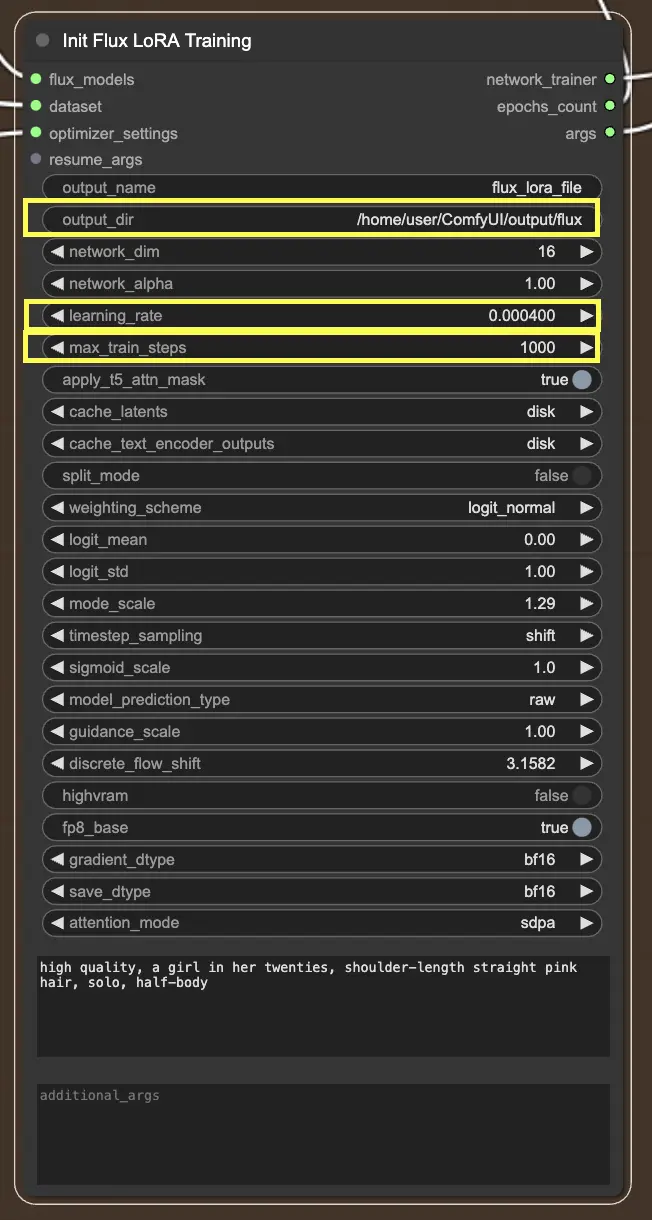
Il nodo InitFluxLoRATraining è il fulcro centrale dove convergono tutti i componenti essenziali per avviare il processo di FLUX LoRA Training.
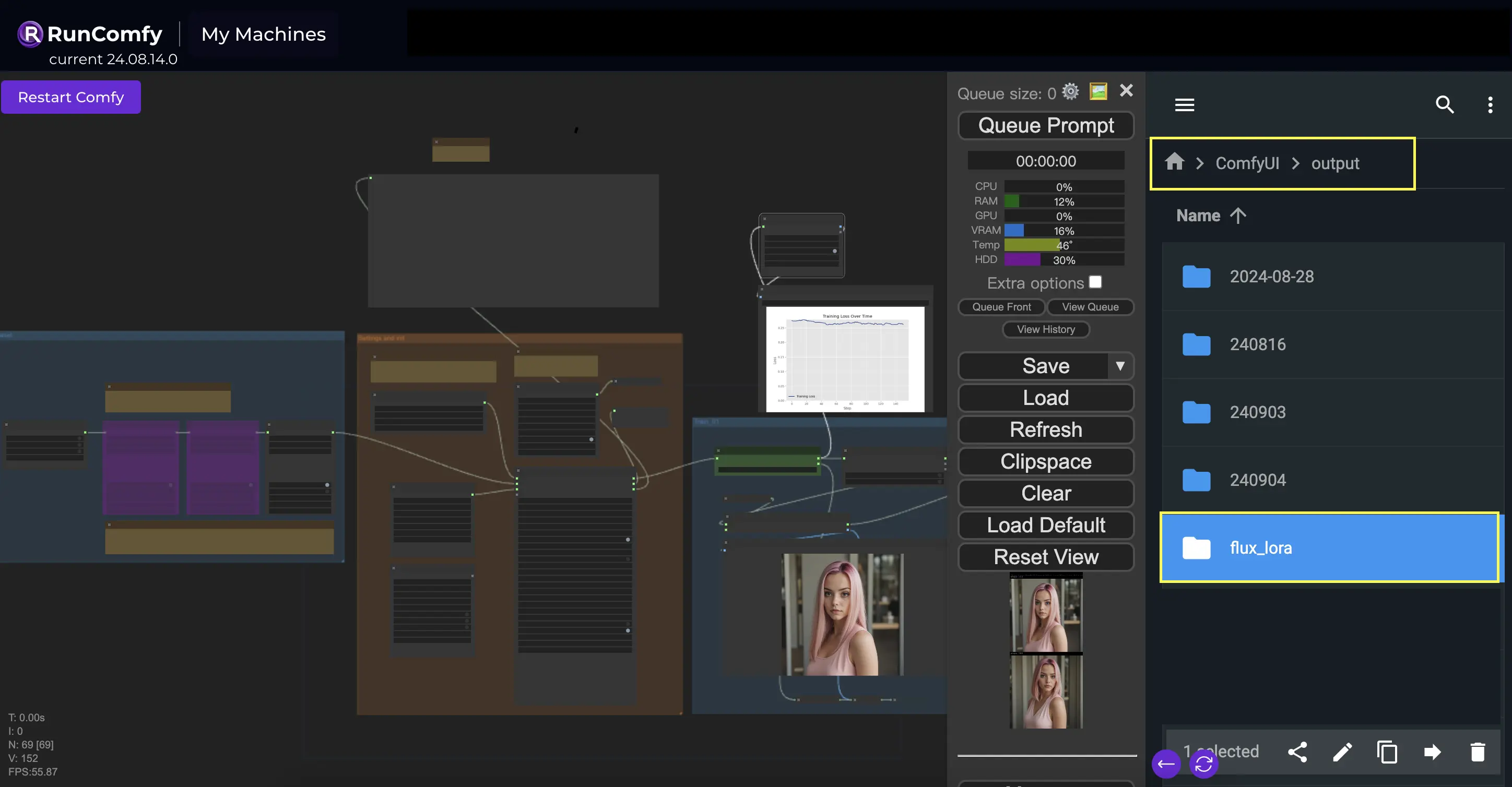
Directory di output: Percorso FLUX LoRA
Una delle cose chiave che dovrai specificare nel nodo InitFluxLoRATraining è la directory di output, dove verrà salvato il tuo modello addestrato. Sulla piattaforma RunComfy, puoi scegliere /home/user/ComfyUI/output/{file_name} come posizione per il tuo output. Una volta completato l'addestramento, potrai visualizzarlo nel file browser.
Dimensioni della rete e tassi di apprendimento
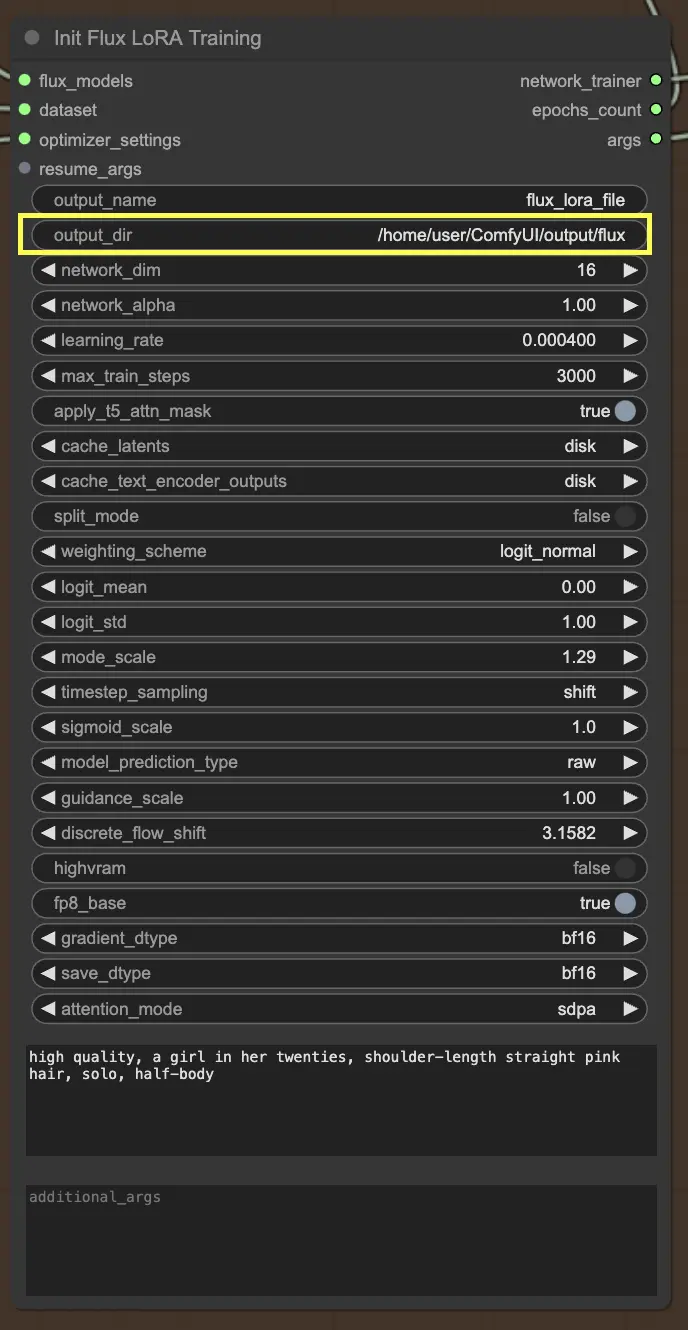
Successivamente, vorrai impostare le dimensioni della rete e i tassi di apprendimento. Le dimensioni della rete determinano la dimensione e la complessità della tua rete LoRA, mentre i tassi di apprendimento controllano la velocità con cui il tuo modello impara e si adatta.
Passi massimi di addestramento
Un altro parametro importante da considerare è max_train_steps. Determina quanto tempo vuoi che il processo di addestramento duri, o in altre parole, quanti passi vuoi che il tuo modello faccia prima che sia completamente cotto. Puoi regolare questo valore in base alle tue esigenze specifiche e alla dimensione del tuo dataset. Si tratta di trovare quel punto dolce in cui il tuo modello ha imparato abbastanza per produrre output appetitosi!
2.3.4. FluxTrainValidationSettings
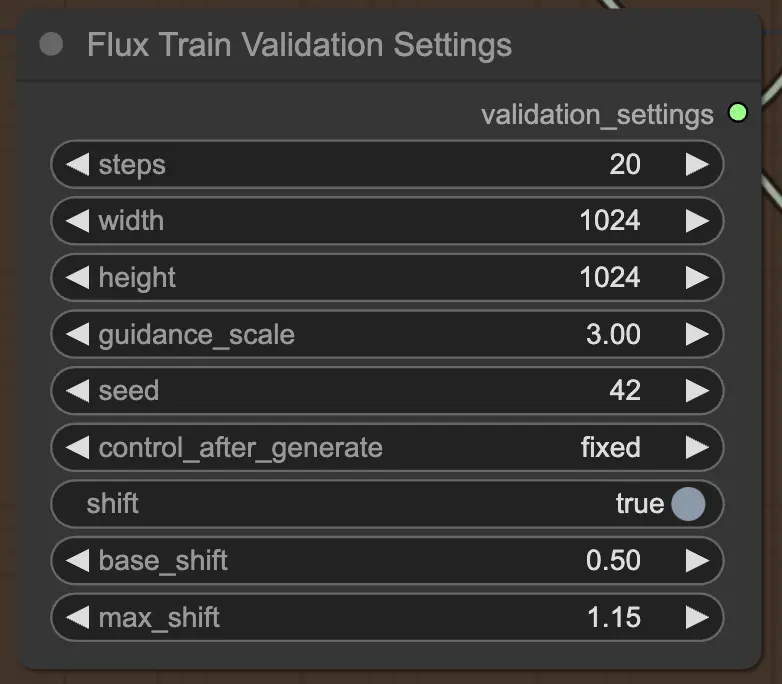
Infine, il nodo FluxTrainValidationSettings ti consente di configurare le impostazioni di validazione per valutare le prestazioni del tuo modello durante il processo di FLUX LoRA Training. Puoi impostare il numero di passi di validazione, la dimensione dell'immagine, la scala di guida e il seme per la riproducibilità. Inoltre, puoi scegliere il metodo di campionamento del timestep e regolare i parametri di scala e spostamento sigmoid per controllare la pianificazione del timestep e migliorare la qualità delle immagini generate.
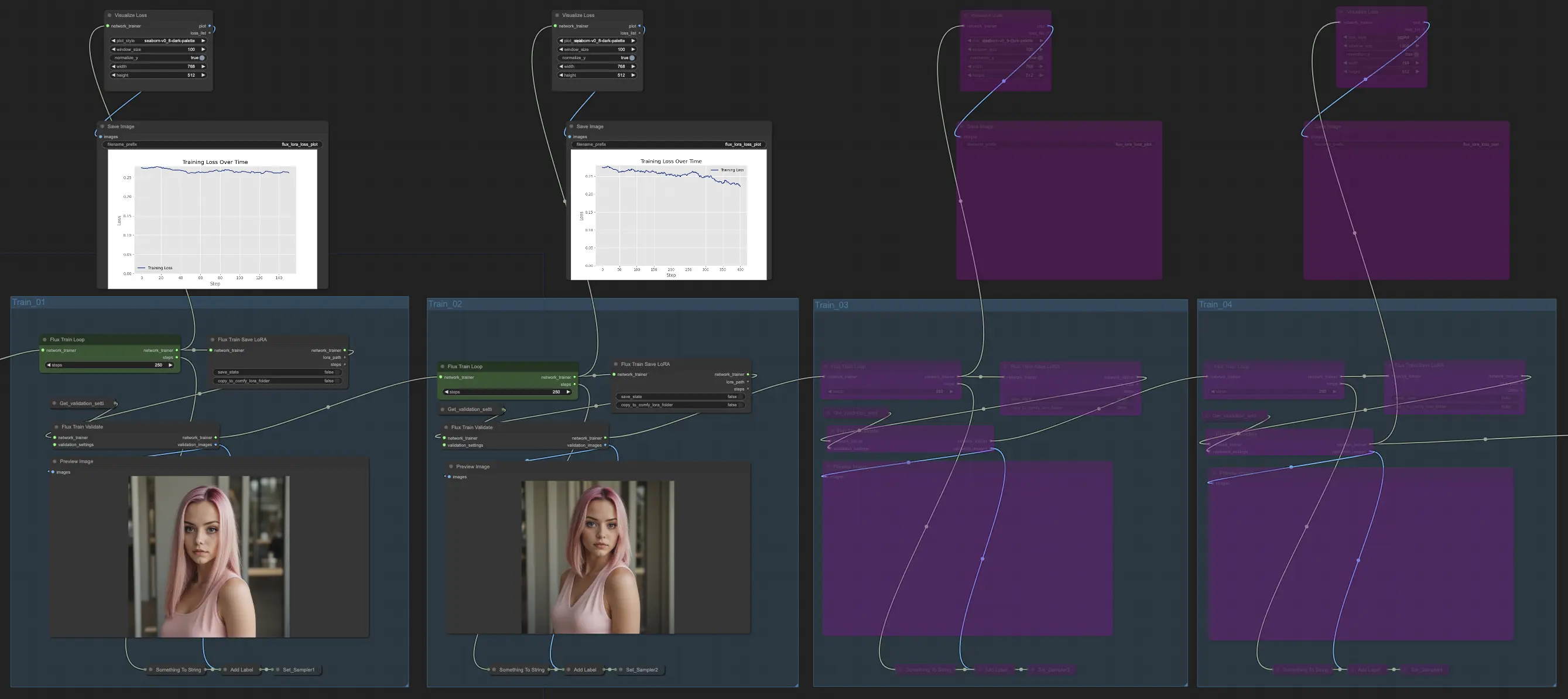
3. Addestramento
La sezione Addestramento di FLUX LoRA Training è dove avviene la magia. È divisa in quattro parti: Train_01, Train_02, Train_03 e Train_04. Ciascuna di queste parti rappresenta una fase diversa del processo di FLUX LoRA Training, consentendoti di affinare e migliorare gradualmente il tuo modello.
3.1. Train_01
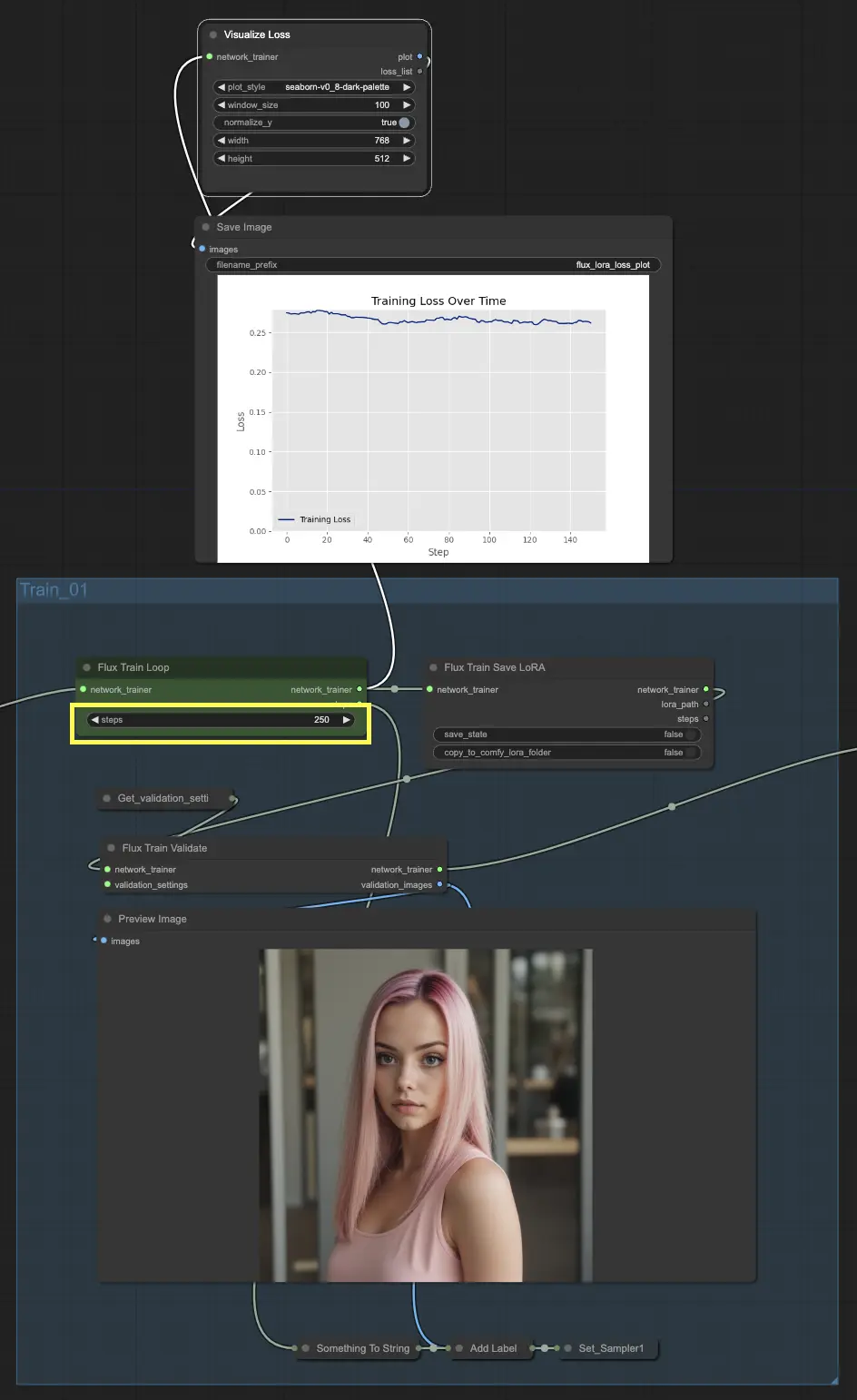
Iniziamo con Train_01. Qui è dove ha luogo il ciclo di addestramento iniziale. La star di questa sezione è il nodo FluxTrainLoop, responsabile dell'esecuzione del ciclo di addestramento per un numero specificato di passi. In questo esempio, lo abbiamo impostato a 250 passi, ma puoi regolarlo in base alle tue esigenze. Una volta completato il ciclo di addestramento, il modello addestrato viene passato al nodo FluxTrainSave, che salva il modello a intervalli regolari. Questo assicura che tu abbia checkpoint del tuo modello in diverse fasi dell'addestramento, che possono essere utili per tracciare i progressi e recuperare da eventuali interruzioni inaspettate.
Ma l'addestramento non riguardajson soltanto il salvataggio del modello. Dobbiamo anche validarne le prestazioni per vedere quanto bene sta facendo. Ecco dove entra in gioco il nodo FluxTrainValidate. Prende il modello addestrato e lo mette alla prova utilizzando un dataset di validazione. Questo dataset è separato dai dati di addestramento e aiuta a valutare quanto bene il modello generalizza su esempi non visti. Il nodo FluxTrainValidate genera immagini campione basate sui dati di validazione, dandoti una rappresentazione visiva dell'output del modello a questo stadio.
Per tenere d'occhio i progressi dell'addestramento, abbiamo il nodo VisualizeLoss. Questo comodo nodo visualizza la perdita durante l'addestramento nel tempo, consentendoti di vedere quanto bene il modello sta imparando e se sta convergendo verso una buona soluzione. È come avere un personal trainer che tiene traccia dei tuoi progressi e ti aiuta a rimanere sulla buona strada.
3.2. Train_02, Train_03, Train_04
In Train_02, continuando da Train_01 nel FLUX LoRA Training, l'output viene ulteriormente addestrato per un ulteriore numero specificato di passi (ad esempio, 250 passi). Train_03 e Train_04 seguono un modello simile, estendendo l'addestramento con connessioni aggiornate per una progressione lineare. Ogni fase produce un modello FLUX LoRA, consentendoti di testare e confrontare le prestazioni.
Esempio
Nel nostro esempio, abbiamo scelto di utilizzare solo Train_01 e Train_02, ciascuno eseguendo 250 passi. Abbiamo bypassato Train_03 e Train_04 per ora. Ma sentiti libero di sperimentare e regolare il numero di sezioni di addestramento e i passi in base alle tue esigenze specifiche e risorse.
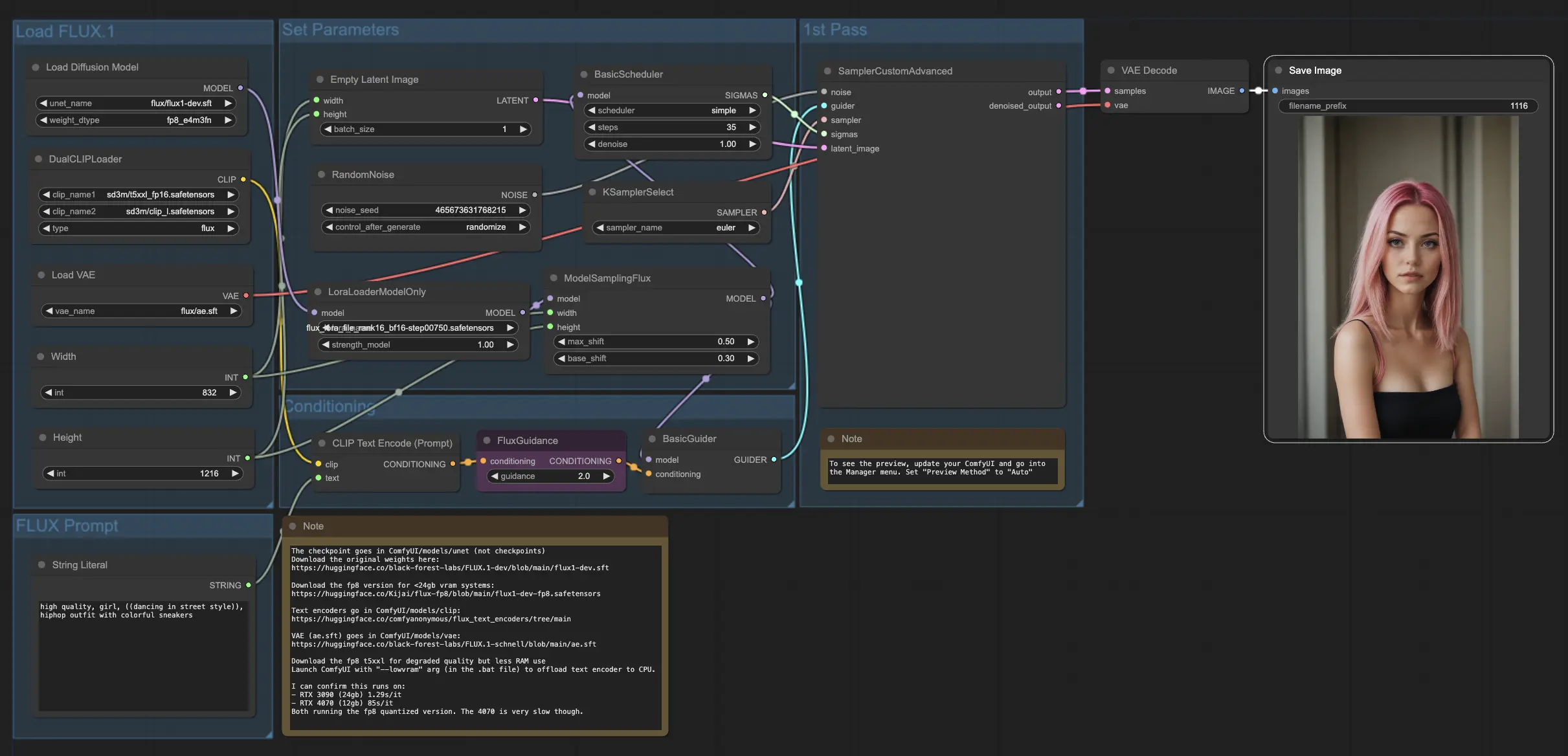
4. Come e dove utilizzare i modelli FLUX e FLUX LoRA
Una volta che hai il modello FLUX LoRA, puoi incorporarlo nel . Sostituisci il modello LoRA esistente con il tuo modello addestrato, quindi testa i risultati per valutarne le prestazioni.
Esempio
Nel nostro esempio, utilizziamo il flusso di lavoro FLUX LoRA per generare più immagini dell'influencer applicando il modello FLUX LoRA e osservandone le prestazioni.
Licenza
Visualizza i file delle licenze:
Il modello FLUX.1 [dev] è concesso in licenza da Black Forest Labs. Inc. sotto la licenza FLUX.1 [dev] Non-Commercial License. Copyright Black Forest Labs. Inc.
IN NESSUN CASO BLACK FOREST LABS, INC. SARÀ RESPONSABILE PER QUALSIASI RECLAMO, DANNI O ALTRE RESPONSABILITÀ, SIA IN UN'AZIONE DI CONTRATTO, TORTO O ALTRO, DERIVANTI DA, FUORI O IN CONNESSIONE CON L'USO DI QUESTO MODELLO.






