Audioreactive Dancers Evolved
The Audioreactive Dancers Evolved Workflow transforms video subjects into captivating animations synced to musical beats, set against dynamic, geometric, and psychedelic backgrounds. Designed for flexibility, it allows users to control video frames, masking, audio responsiveness, and pattern details. With features like dilation masks, ControlNet, and beat-synced noise animation, this ComfyUI workflow empowers creatives to blend art, sound, and motion, creating visually immersive, rhythmic experiences with audioreactive visuals.ComfyUI Audioreactive Dancers Evolved Workflow

- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI Audioreactive Dancers Evolved Examples
ComfyUI Audioreactive Dancers Evolved Description
Create stunning video animations by transforming your subject (dancer) and give them a dynamic audioreactive background made up of various intricate geometries and psychedelic patterns. You can use this workflow with single or multiple subjects. With this workflow, you can produce mesmerizing audioreactive visual effects that perfectly sync with the rhythm of the music, offering an immersive experience. The workflow allows you to use it with a single subject or multiple subjects, all enhanced with audioreactive elements.
How to use Audioreactive Dancers Evolved Workflow:
- Upload a subject video in the Input section
- Select the desired width and height of the final video, along with how many frames of the input video should be skipped with “every_nth”. You can also limit the total number of frames to render with “frame_load_cap”.
- Fill out the positive and negative prompt. Set batch frame times to match when you’d like the scene transitions to occur.
- Upload images for each of the default IP Adapter subject mask colors:
- Red, Green, Blue = subject(s)
- Black = Background
- White = White audioreactive dilation mask
- Yellow, Magenta = Background Noise mask patterns
- Load a good LCM checkpoint (I use ParadigmLCM by Machine Delusions) in the “Models” section.
- Add any loras using the Lora stacker below the model loader
- Hit Queue Prompt
Video Guide
Node and Group Color
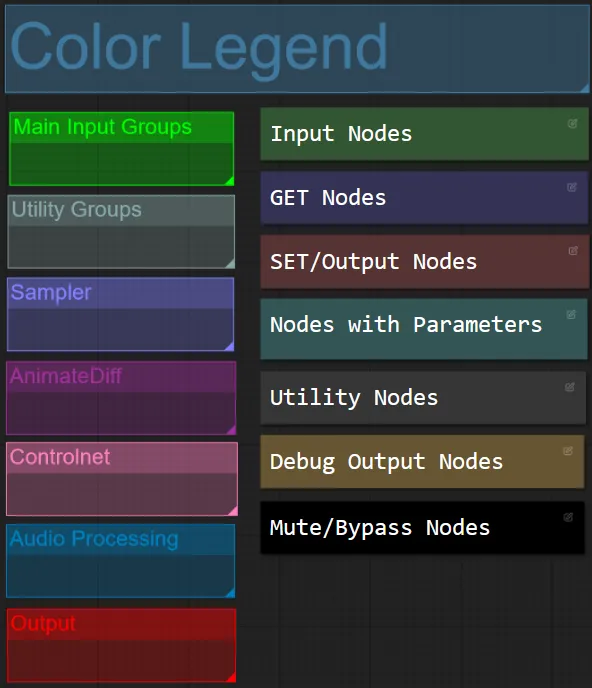
- For this workflow I have color-coordinated nodes based on their functionality within each group.
- Group Section titles are color coordinated for easier differentiation.
Input
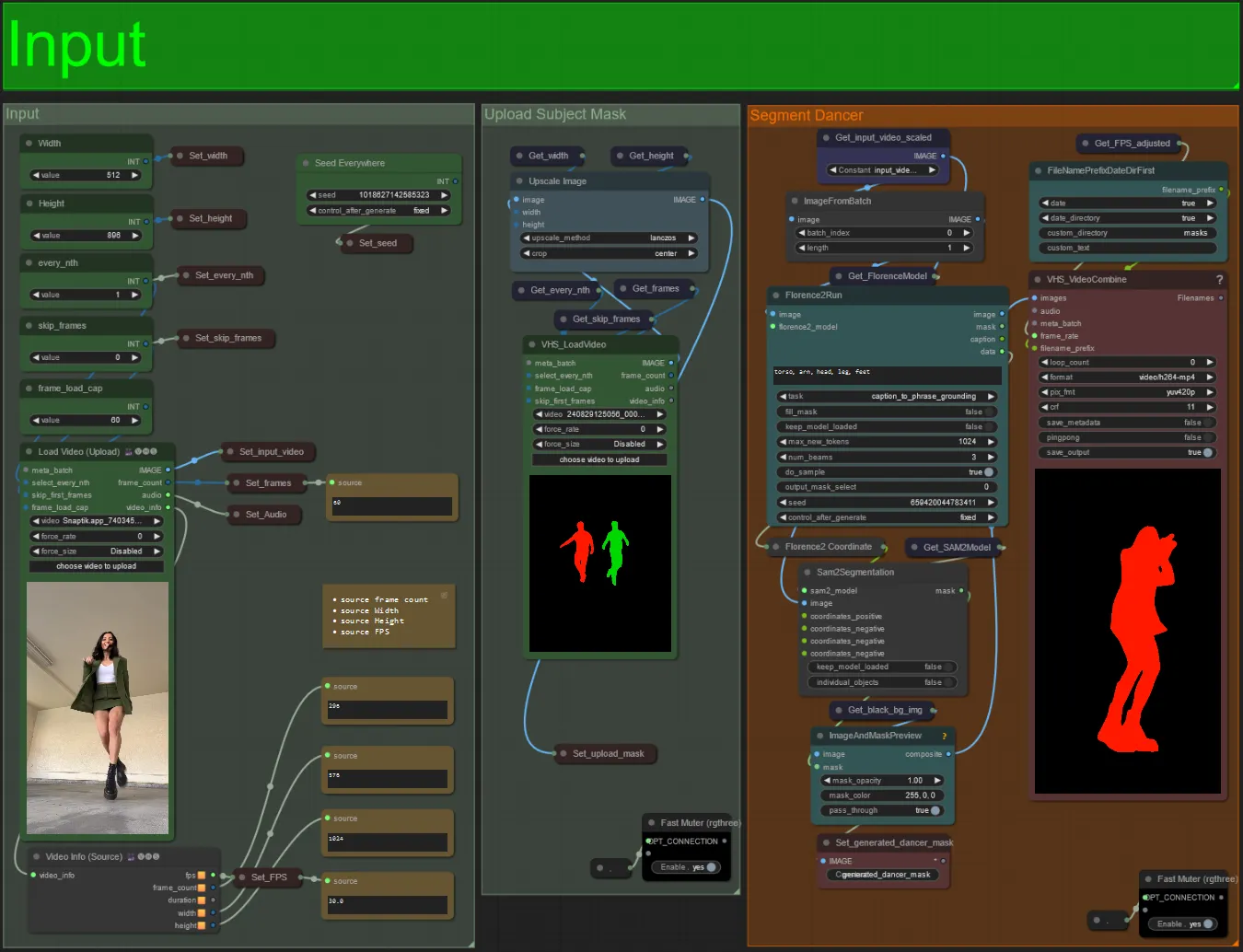
- Upload your desired subject video to the Load Video (Upload) node.
- You can adjust the output width and height using the top left two inputs.
- every_nth sets whether to use every other frame, every third frame and so on (2 = every other frame). Left at 1 by default.
- skip_frames is used to skip frames at the beginning of the video. (100 = skip the first 100 frames of the input video). Left at 0 by default.
- frame_load_cap is used to specify how many total frames of the input video should be loaded. Best to keep low when testing settings (30 - 60 for example) and then increase or set to 0 (no frame cap) when rendering the final video.
- The number fields in bottom right display info about the uploaded input video: total frames, width, height, and FPS from top to bottom.
- If you already have a mask video of the subject generated , you can un-mute the “Upload Subject Mask” section and upload the mask video. Optionally you can mute the “Segment Dancer” section to save some processing time.
- Sometimes the segmented subject will not be perfect, you can check the mask quality using the preview box in the bottom right seen above. If that is the case you can play around with the prompt in the “Florence2Run” node to target different body parts such as “head”, “chest”, “legs”, etc. and see if you get a better result.
Prompt
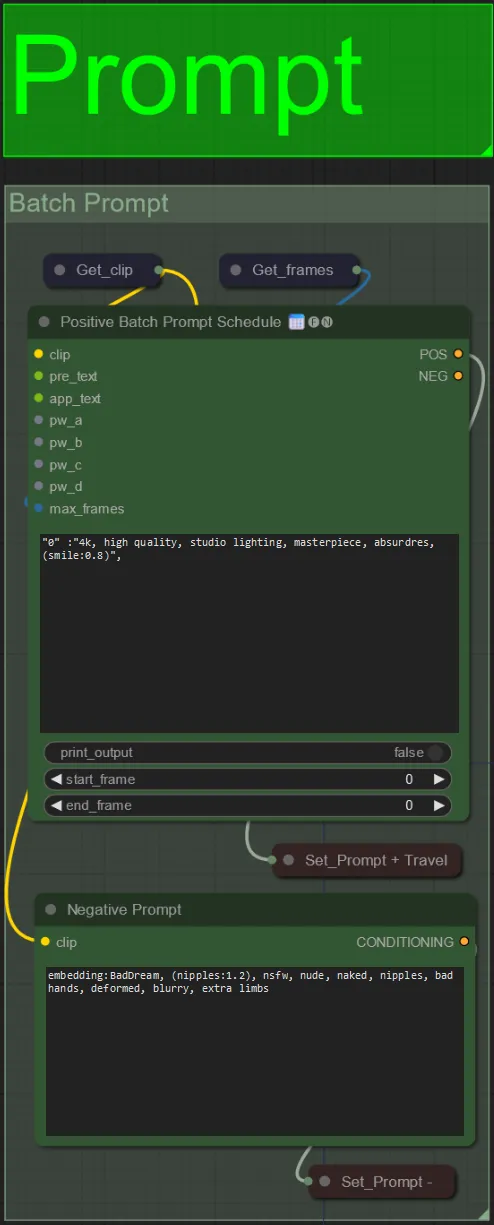
- Set the positive prompt using batch formatting:
- e.g. “0”: “4k, masterpiece, 1girl standing on the beach, absurdres”, “25”: “HDR, sunset scene, 1girl with black hair and a white jacket, absurdres”, …
- Negative prompt is normal format, you can add embeddings if desired.
Audio Processing
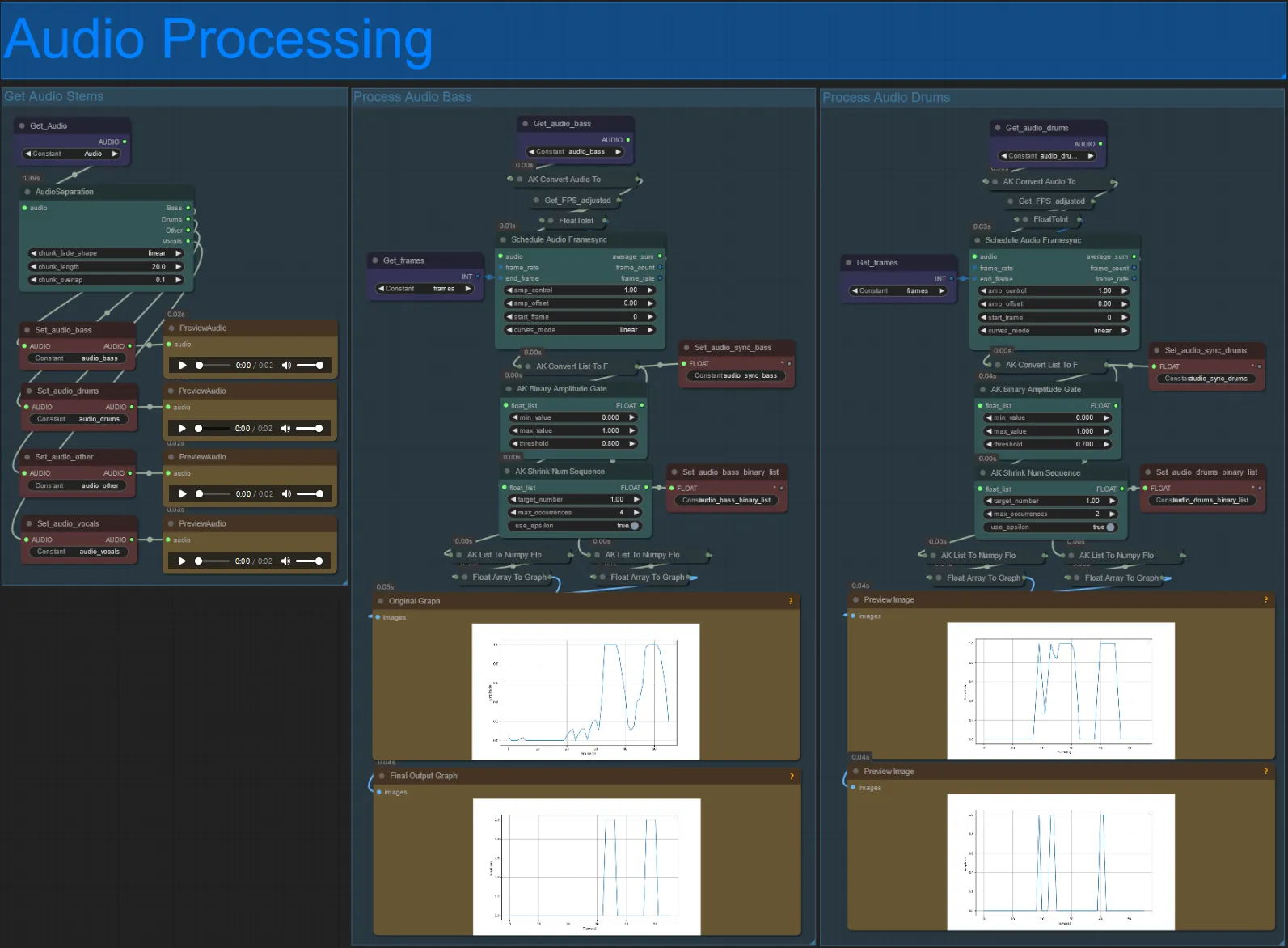
- This section takes in audio from the input video, extracts the stems (bass, drums, vocals, etc.) and then converts it to a normalized amplitude synced with the input video frames, to create audioreactive visuals.
- amp_control = total range the amplitude can travel.
- amp_offset = the minimum value the amplitude can take.
- Example: amp_control = 0.8 and amp_offset = 0.2 means the signal will travel between 0.2 and 1.0.
- Sometimes the Drums stem will have the actual Bass notes of the song, preview each to see which to use for your audioreactive masks.
- Use the graphs to get a good understanding of how the signal for that stem changes over the length of the video
Voronoi Generators
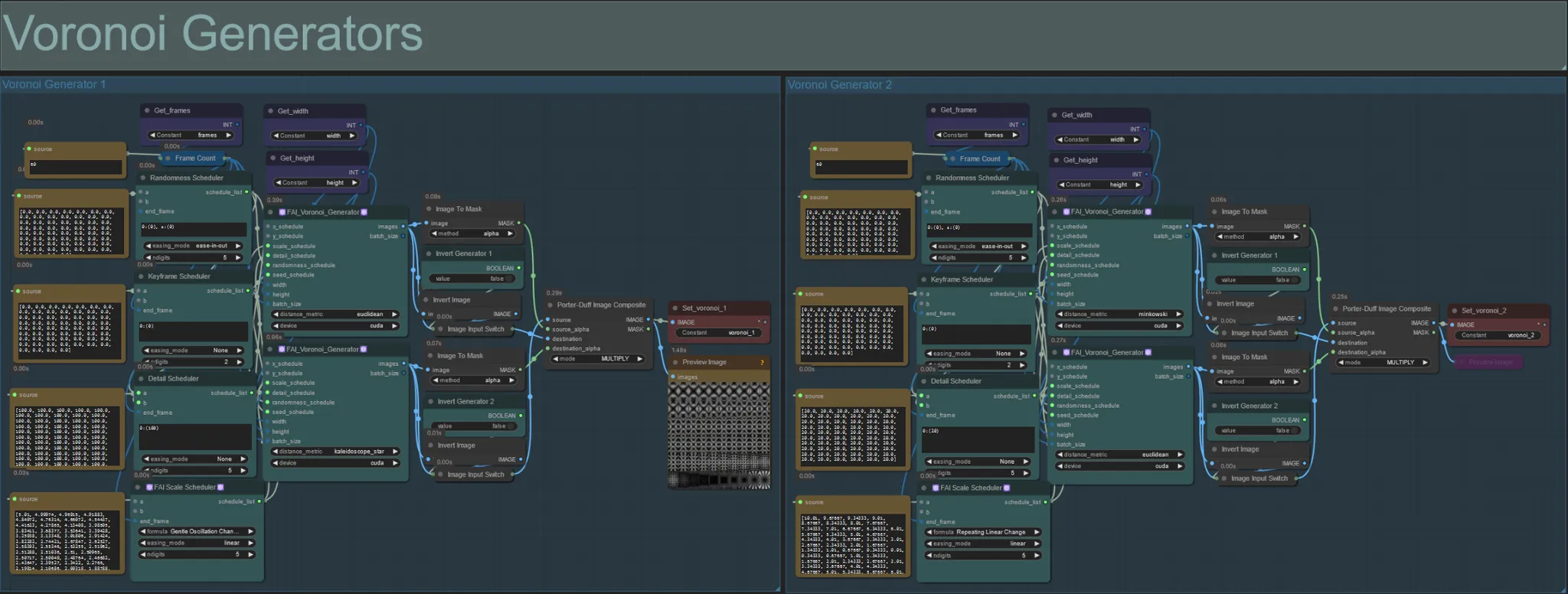
- This section generates Voronoi noise patterns using two FAI_Voronoi_Generator custom nodes per group which are composited together using a Multiply.
- You can increase the Randomness Scheduler values in the parenthesis from 0 to break up symmetrical patterns in the final output.
- Increase the Detail Scheduler value in the parenthesis to increase the detail count in the output noise patterns. Lower values results in lower noise differentiation.
- Change the “formula” parameters in the FAI Scale Scheduler node to have a large impact on the final noise pattern movement.
- You can also change the “distance_metric” function on the FAI_Voronoi_Generator nodes themselves to greatly affect the generated patterns and shapes of the resulting noise.
Audio Masks
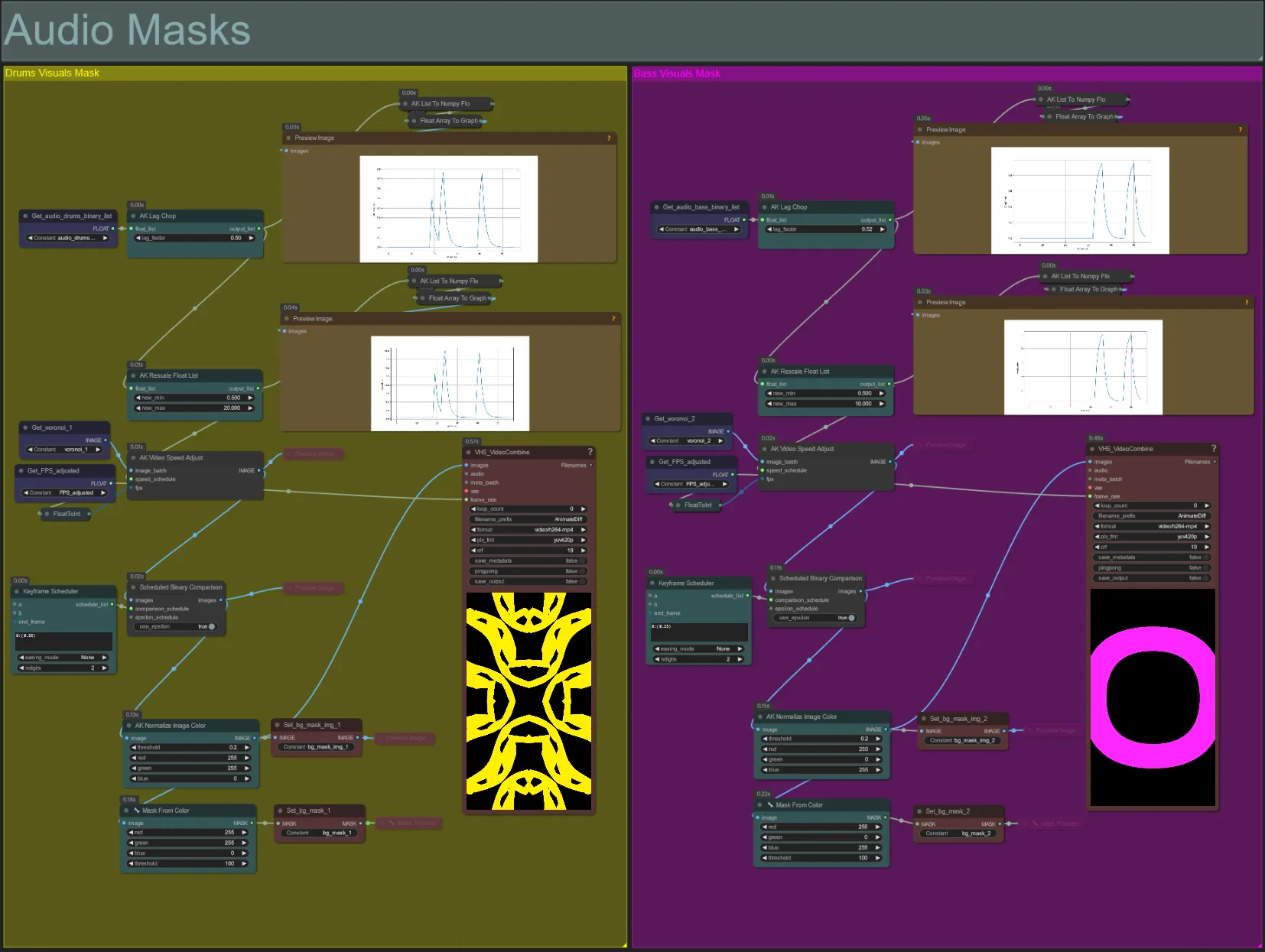
- This section is used to convert the voronoi noise image batches into colored masks to be composited with the subject, as well as synchronizes their movements with the beat of either the bass or drums audio stems. These masks are essential for creating audioreactive effects.
- Increase the “lag_factor” in the AK Lag Chop node to increase how “spiky” the final amplitude graphs will be. This will cause the output noise movement to speed up and slow down more suddenly, whereas a lower lag_factor will result in a more gradual deceleration of movement after each beat. This is used to avoid the noise mask animation from appearing too “jumpy” and rigid.
- The AK Rescale Float List is used to re-map the normalize amplitude values from 0-1 to new_min and new_max. A value of 1.0 represents 30FPS playback speed of the noise animation, whereas 0.5 represents 15FPS, 2.0 represents 60FPS, etc. Adjust this value to change how slow the audioreactive noise pattern animates off the beat (amplitude 0.0), and how fast it moves on the beat (amplitude 1.0).
- The Keyframe Scheduler has a large affect on the appearence of the mask. It creates a list of float values to specify the threshold of pixel brightness values to use for the noise input images which will result in part of the noise getting cropped and turned into the final mask. Lower this value to retain more of the input noise, and increase to retain less of the noise.
Dilate Masks
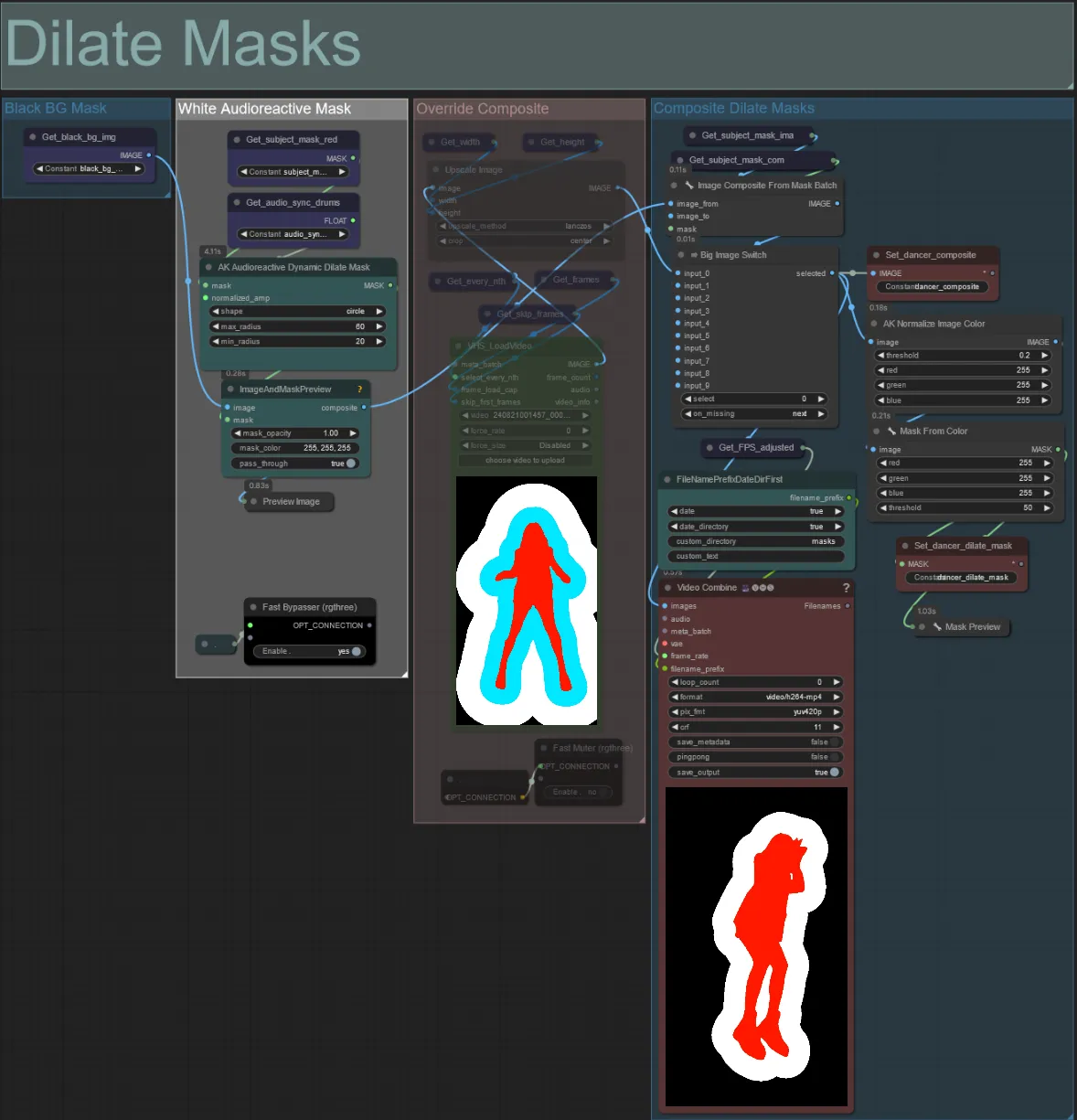
- Each colored group corresponds to the color of dilation mask that will be generated by it.
- You can set the min and max radius of the dilation mask, as well as the shape using the following node:
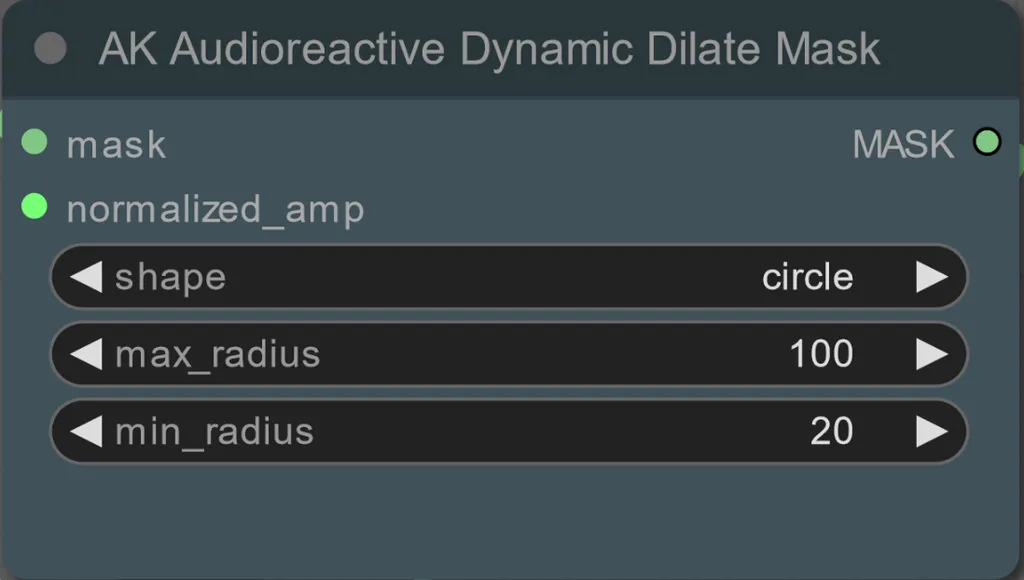
- shape: “circle” is the most accurate but takes longer to generate. Set this when you are ready to perform the final rendering. “square” is fast to compute but less accurate, best for testing out the workflow and deciding on IP adapter images.
- max_radius: The radius of the mask in pixels when the amplitude value is max (1.0).
- min_radius: The radius of the mask in pixels when the amplitude value is min (0.0).
- If you already have a composite mask video generated you can un-mute the “Override Composite Mask” group and upload it. It’s recommended to bypass the dilation mask groups if overriding to save on processing time.
Latent Noise Mask
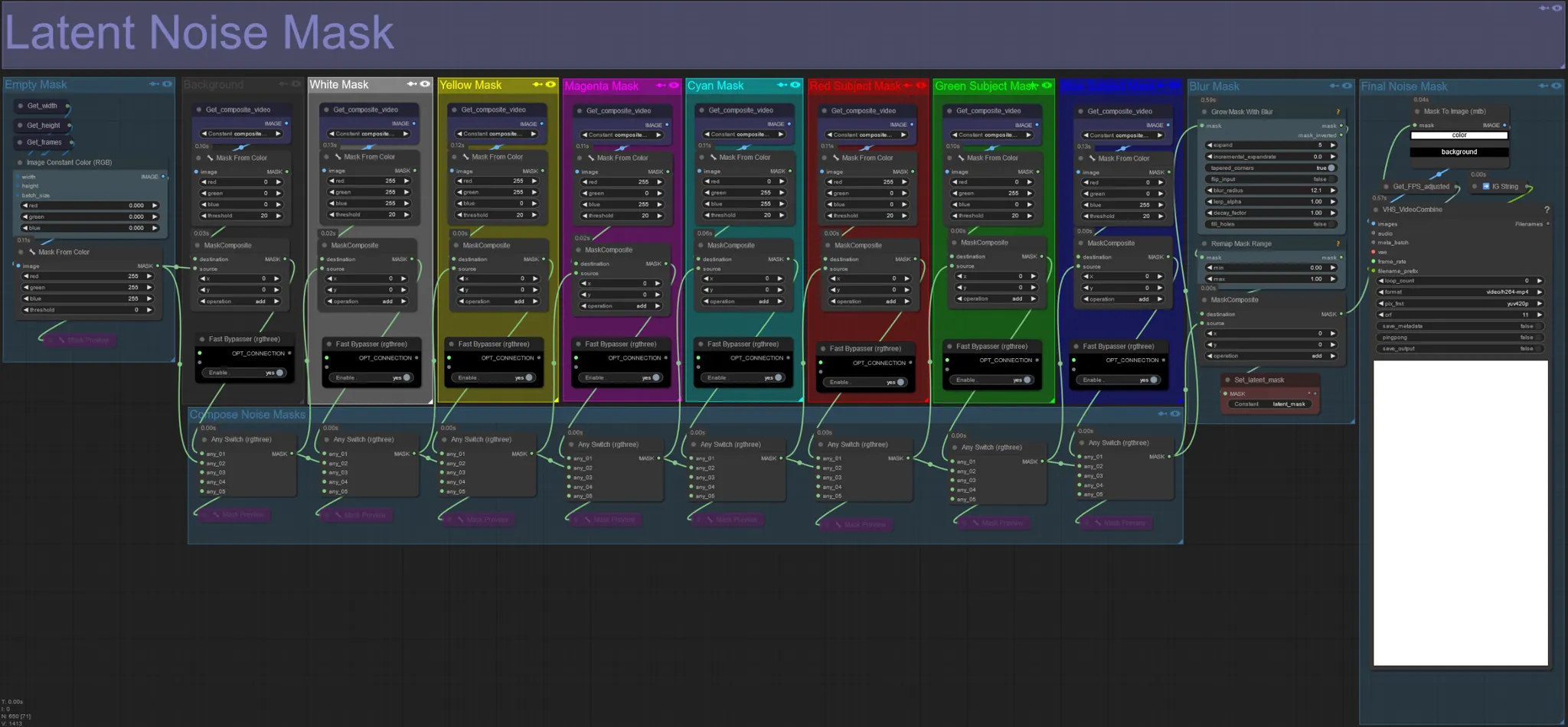
- Use latent noise masks to control which masks are actually diffused (dreamed over) by the ksampler. Bypass the group corresponding to the colored mask that you don’t want diffused (i.e. want to have elements from the original video appear on).
- Leaving all mask groups enabled results in a white final noise mask (everything will be diffused).
- Example: Bypass the Red Subject Mask group by clicking the Fast Bypasser node to have your dancer or subject appear in the final output.
Original Input Video:

Bypassing Red and Yellow Mask Groups:

Composite Mask
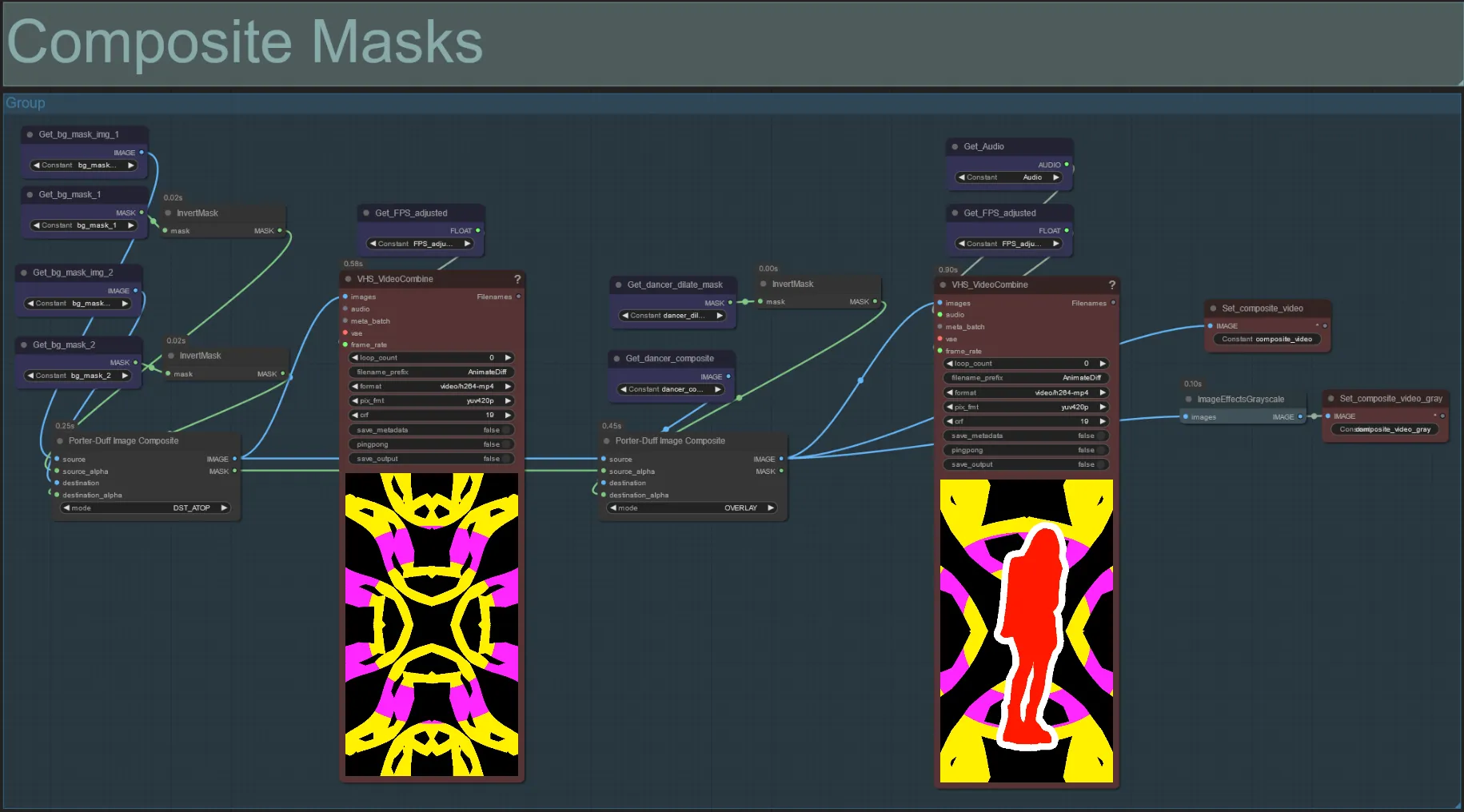
- This section creates the final composite of the voronoi noise masks with the subject mask (and audioreactive dilation mask if enabled).
Models
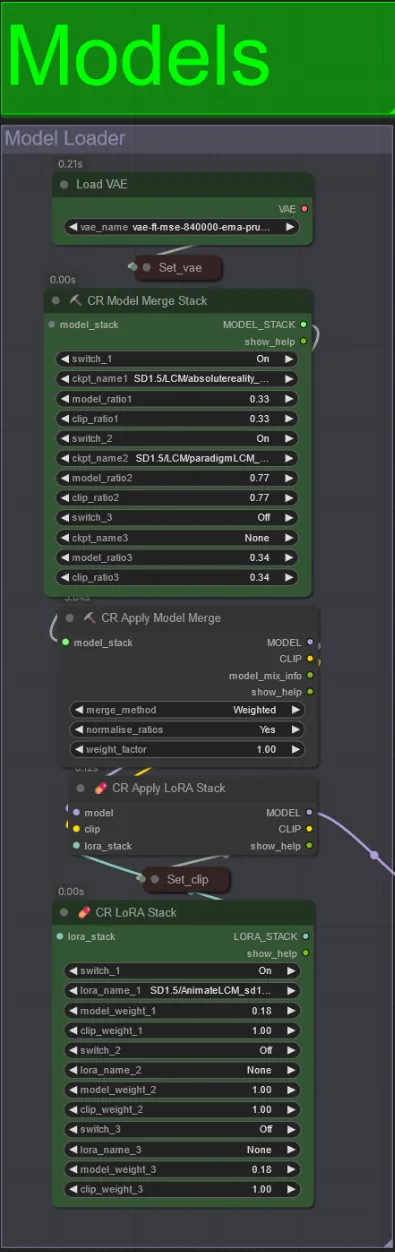
- Use a good LCM model for the checkpoint. I recommend ParadigmLCM by Machine Delusions.
- You can merge multiple models together using the Model Merge Stack to get various interesting effects. Make sure the weights add up to 1.0 for the enabled models.
- You can optionally specify the AnimateLCM_sd15_t2v_lora.safetensors with a low weight of 0.18 to further enhance the final result.
- Add any additional Loras to the model using the Lora stacker below the model loader.
AnimateDiff

- You can set a different Motion Lora instead of the one I used (LiquidAF-0-1.safetensors)
- Increase/decrease the Scale and Effect floats to increase/decrease the amount of motion in the output.
IP Adapters
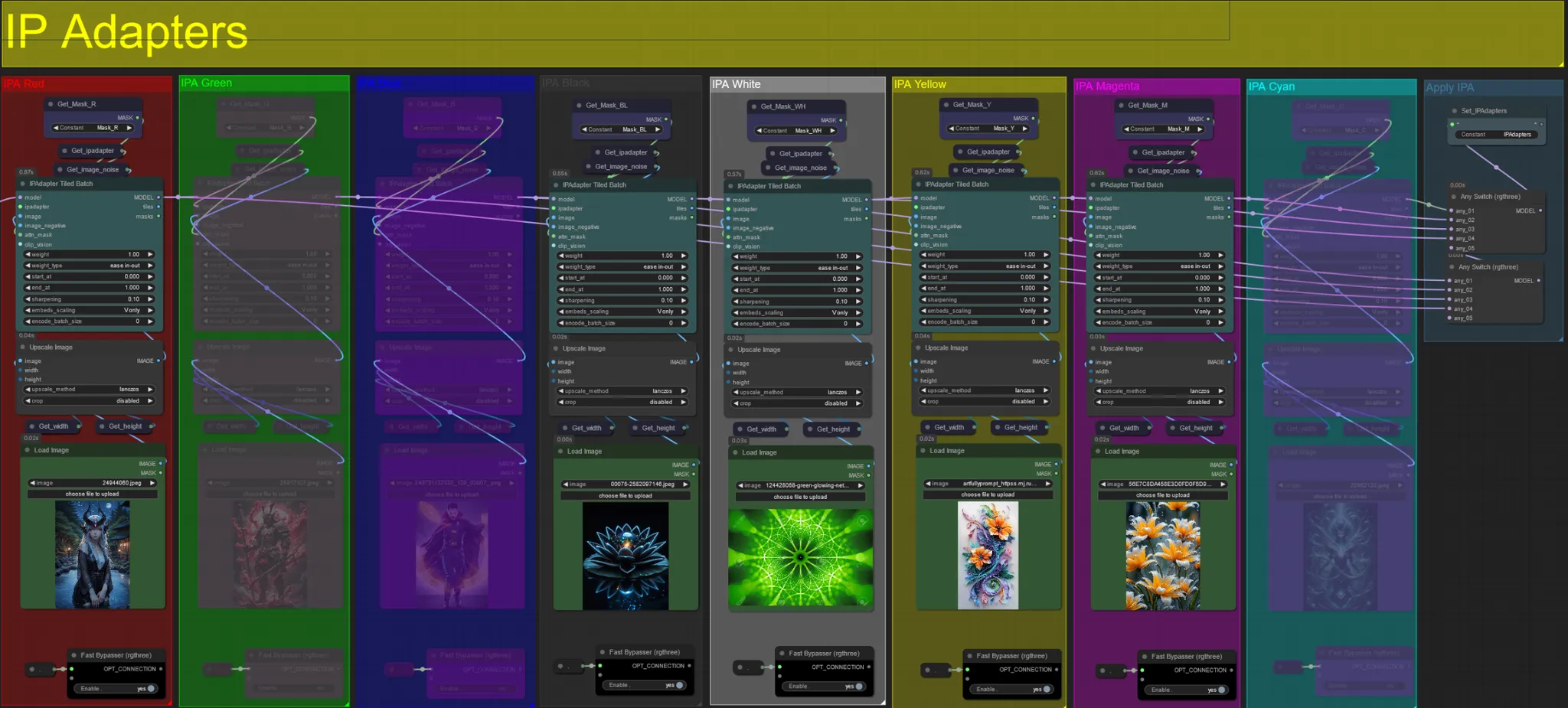
- Here you can specify the reference images that will be used to render the backgrounds for each of the dilation masks, as well as your video subject(s).
- The color of each group represents the mask it targets:
Red, Green, Blue:
- Subject mask reference images.
Black:
- Background mask image, upload a reference image for the background.
White:
- Dilation mask reference images, upload a reference image for each color dilation mask in use.
Yellow, Magenta
- Voronoi noise mask reference images.
ControlNet
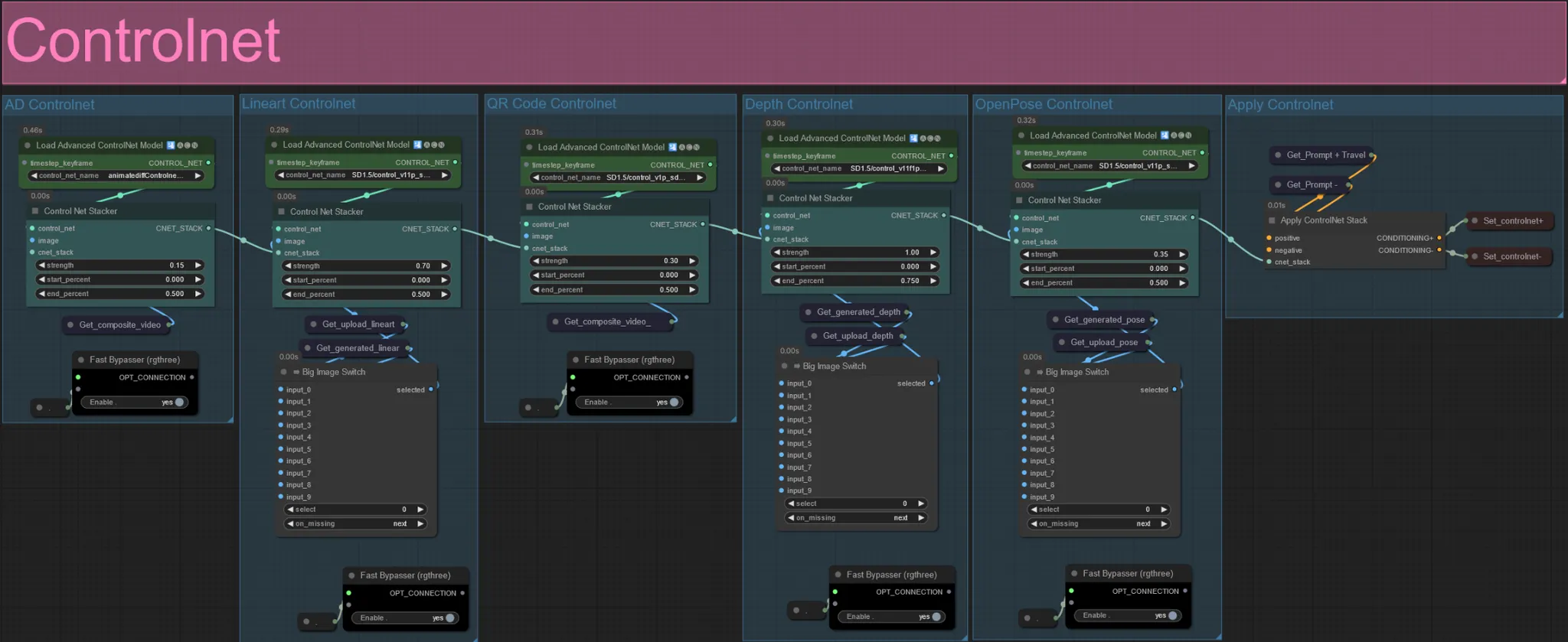
- This workflow makes use of 5 different controlnets, including AD, Lineart, QR Code, Depth, and OpenPose.
- All of the inputs to the controlnets are generated automatically
- You can choose to override the input video for the Lineart, Depth, and Openpose controlnets if desired by un-muting the “Override ” groups as seen below:
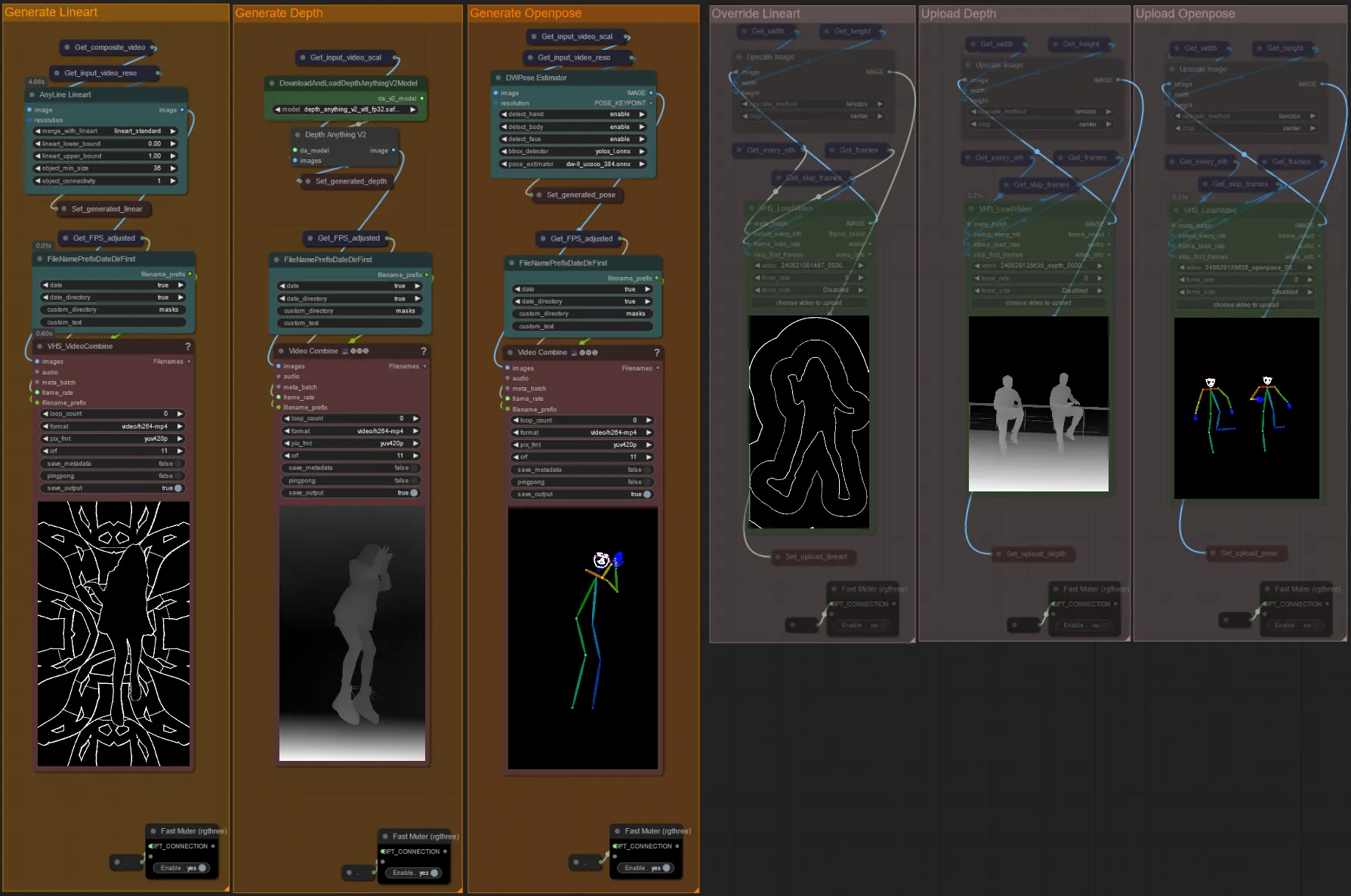
- It is recommended you also mute the “Generate” groups if overriding to save processing time.
Tip:
- Bypass the Ksampler and commence a render with your full input video. Once all the preprocessor videos are generated save them and upload them to the respective overrides. From now on when testing the workflow you will not have to wait for each preprocessor video to be generated individually.
Sampler
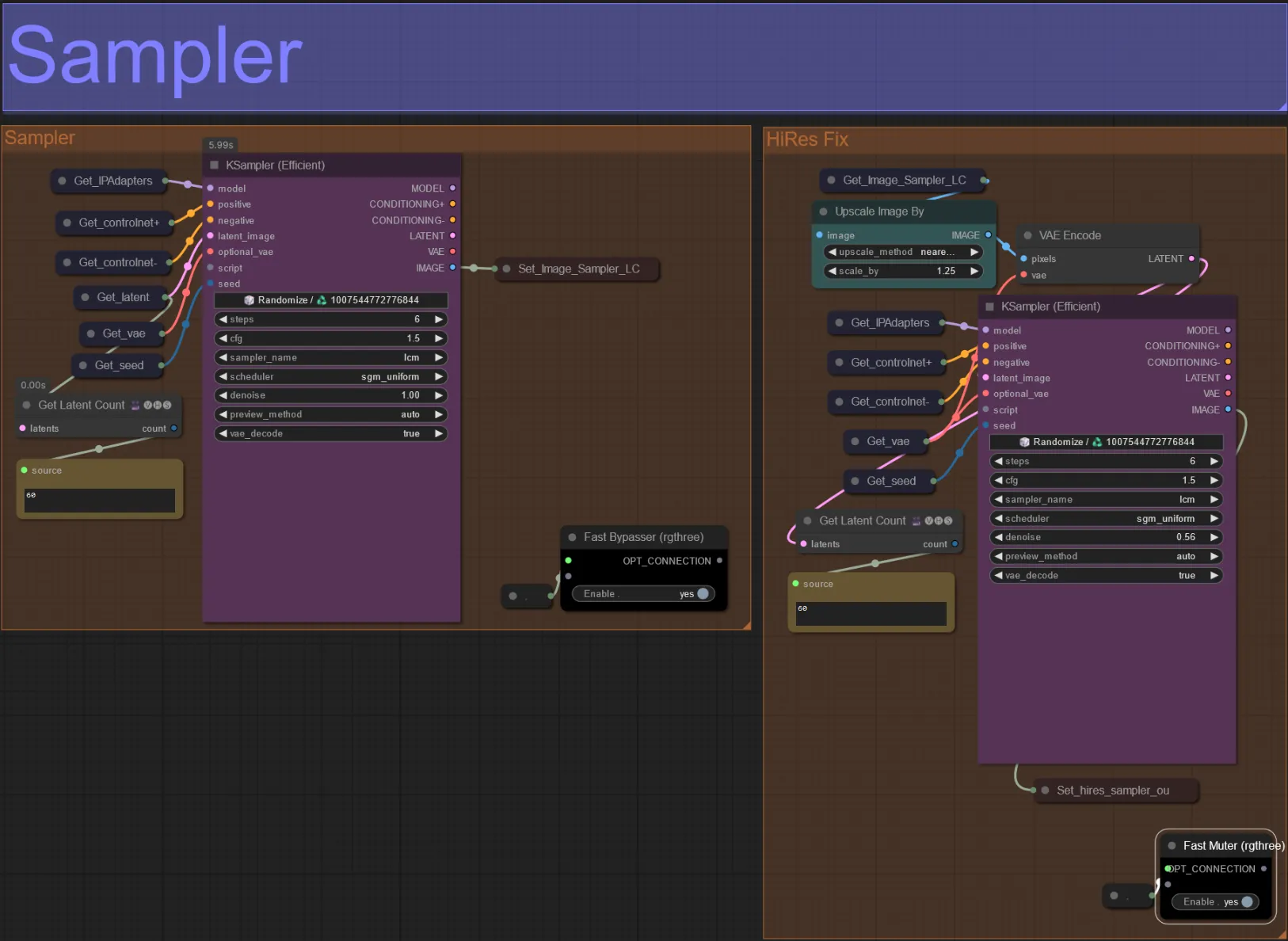
- By default the HiRes Fix sampler group will be muted to save processing time when testing
- I recommend bypassing the Sampler group as well when trying to experiment with dilation mask settings to save time.
- On final renders you can un-mute the HiRes Fix group which will upscale and add details to the final result.
Output
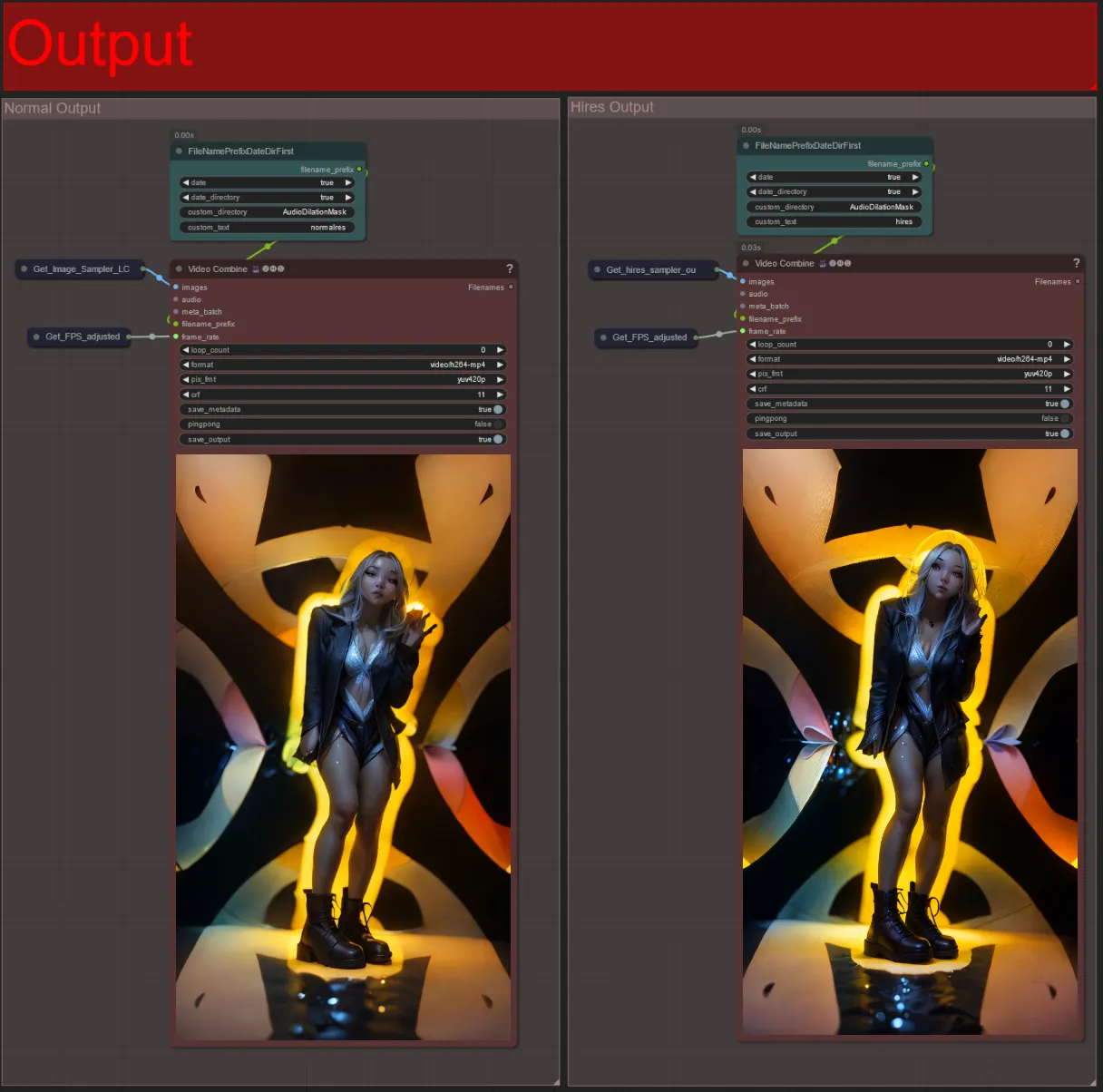
- There are two output groups: the left is for standard sampler output, and the right is for the HiRes Fix sampler output.
- You can change where files will be saved by changing the “custom_directory” string in the “FileNamePrefixDateDirFirst” nodes. By default this node will save output videos in a timestamped directory in the ComfyUI “output” directory
- e.g.
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- e.g.
Creating an audioreactive video can add immersive, pulsing energy to your subject, with every frame responding to the beat in real-time. So, dive into the world of audioreactive art and enjoy the rhythm-led transformations!
About Author
Akatz AI:
- Website:
Contacts:
- Email: akatzfey@sendysoftware.com

