
What Dance Video Transform ComfyUI Workflow Does
Dance Video Transform ComfyUI Workflow transforms dance videos into stunning new scenes with professional face swapping while preserving the original choreography and ensuring high-quality output. The process happens in stages, from motion analysis to face replacement, allowing quality checks at each step.
How Dance Video Transform ComfyUI Workflow Works
The workflow transforms your dance video by automating these complex transformations through several stages, requiring only your video, a face image, and scene description: Motion Analysis → Style Transfer → Face Replacement
- Analyzes dance movements and spatial information
- Transforms the scene according to your description
- Integrates new face while maintaining expressions
Key Features of Dance Video Transform ComfyUI Workflow
- Optimized for vertical format (9:16 aspect ratio)
- Triple ControlNet system for stable transformations
- Professional face swapping with natural blending
- Fast testing mode (process 50 frames in minutes)
- Support for high-resolution output (up to 896px height)
- Advanced motion preservation using AnimateDiff
- Dual output system for quality verification
Quick Start Guide
Step 1: Initial Setup
In respective nodes:
- Load Video (Upload):
- Upload 10-15 second dance video with a 9:16 aspect ratio
- If your video is not in 9:16, you will need to adjust parameters Width and Height to match your video.
- Frame Load Cap: 50 (render only the first 50 frames for quick test)
- Load Image:
- Upload clear, front-facing face photo
- Batch Prompt Schedule:
- Briefly describe the scene and any other aspects you want to transform ``
"0": "[person] in KC Chiefs jersey wearing bluejeans and a baseball cap dancing in the locker room"`` - Set negative prompt as needed <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme01.webp" alt="dance video transform" width="450"/> <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme02.webp" alt="dance video transform" width="450"/> <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme03.webp" alt="dance video transform" width="450"/>
- Briefly describe the scene and any other aspects you want to transform ``
Step 2: Quick Test Run
- Click "Queue Prompt"
- This processes ~2 seconds of video
- You'll see two outputs:
- First output: Scene transformation only
- Second output: With face swap applied

Step 3: Full Video Processing
Only after quick test looks good:
- Return to "Load Video" node
- Change Frame Load Cap to 0 for full video
- Click "Queue Prompt" for complete processing (This will take significantly longer)
Author's Tips for Beginners
- Follow the Notes: Look for any notes in the interface—they will guide you step-by-step
- Don't Worry About Advanced Settings: Most of the time, you don't need to adjust anything beyond what is mentioned here
- Aspect Ratio Importance: Ensure the aspect ratio is correct, otherwise the video may look stretched or cropped
Key Nodes Reference
AnimateDiff Settings
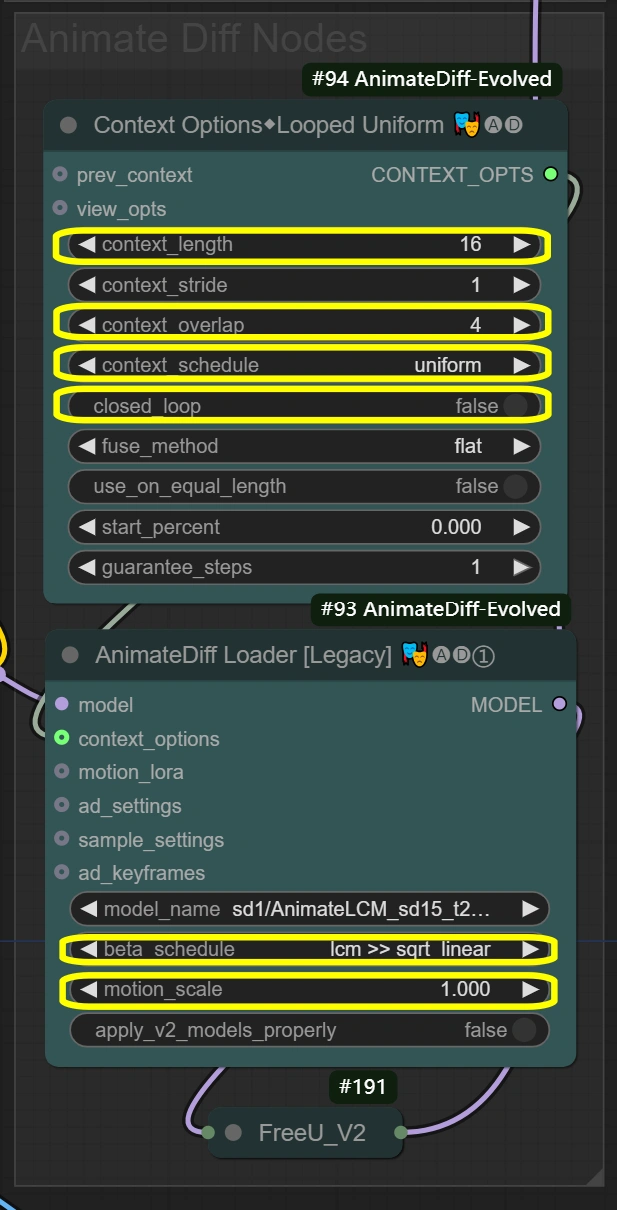
Nodes here create smooth motion preservation throughout the video transformation. Context Options defines how frames should be grouped and processed, feeding these settings to AnimateDiff Loader, which then applies the actual motion preservation. Context length and overlap settings directly affect how AnimateDiff Loader maintains movement consistency.
- Context Options Node (#94): Achieves frame grouping and temporal processing control for consistent motion.
- context_length:
- Controls how many frames are processed together
- Higher = smoother but more VRAM usage
- Lower = faster but may lose motion coherence
- context_overlap:
- Handles frame transition smoothness
- Higher = better blending but slower processing
- Lower = faster but may show transition gaps
- context_schedule:
- Controls frame distribution
- "uniform" best for dance motion
- Don't change unless specific needs
- closed_loop:
- Controls video loop behavior
- True only for perfectly looping videos
- context_length:
- AnimateDiff Loader Node (#93): Implements the motion preservation using AnimateDiff model and applies temporal consistency.
- motion_scale:
- Controls motion strength
- Higher: Exaggerated movement
- Lower: Subdued movement
- beta_schedule: lcm >> sqrt_linear
- Controls sampling behavior
- Optimized for this workflow
- Don't modify unless necessary
- motion_scale:
ControlNet Stack
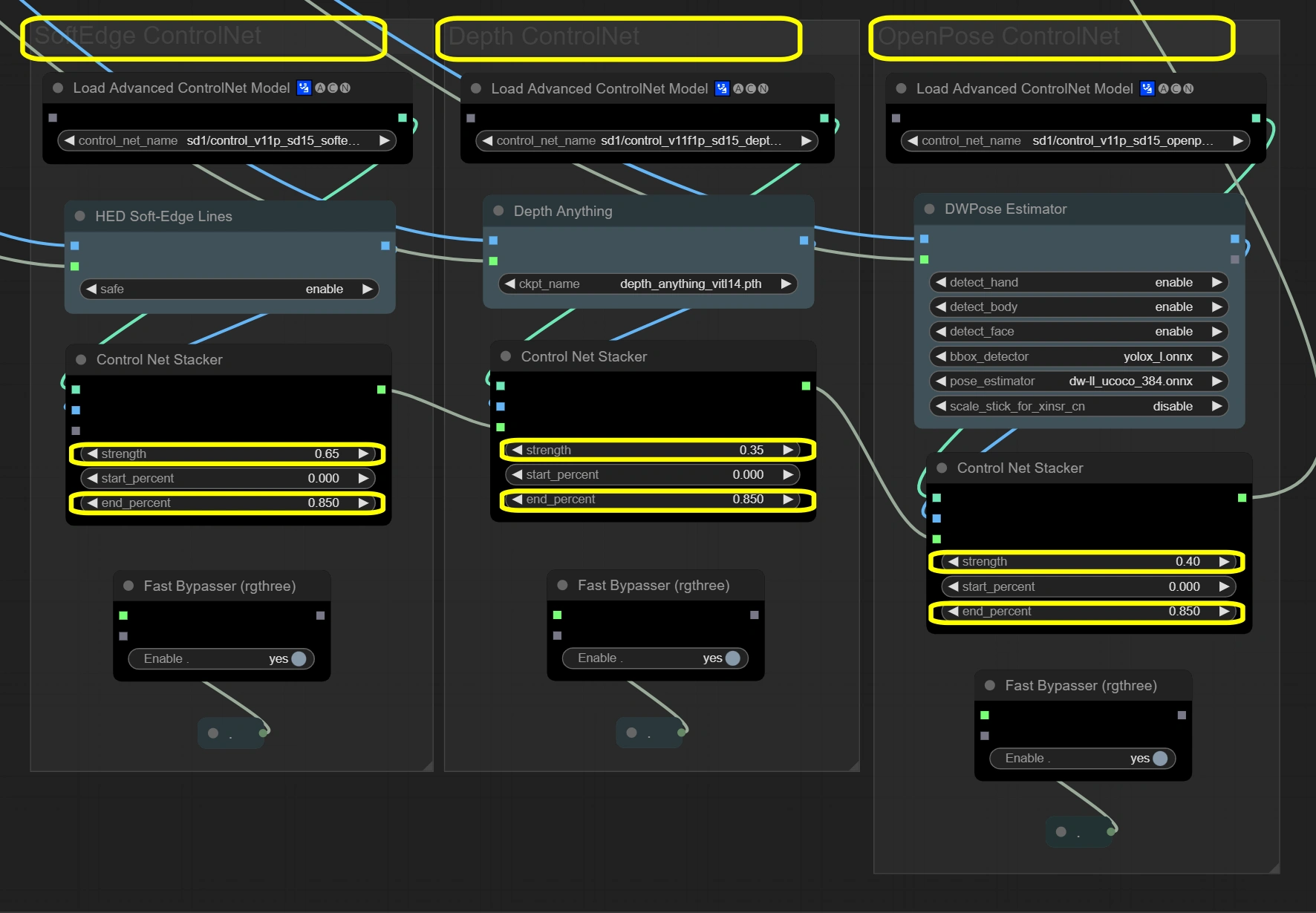
Nodes here maintain video integrity through three-layer guidance system. The three ControlNets process input frames simultaneously, each focusing on different aspects. Soft Edge provides basic structure, Depth adds spatial understanding, and OpenPose ensures movement accuracy. Results combine through stackers with total strength not exceeding 1.4 for stability.
- Soft Edge ControlNet: Extracts and preserves structural elements and shapes from original frames.
- Strength:
- Controls structural preservation
- Higher = stronger adherence to original shapes
- Lower = more creative freedom in shape modification
- End percent:
- When control influence stops
- Higher = longer influence throughout process
- Lower = allows more deviation in later steps
- Strength:
- Depth ControlNet: Processes spatial relationships and maintains 3D consistency.
- Strength:
- Controls spatial awareness
- Higher = stronger 3D consistency
- Lower = more artistic freedom with space
- End percent:
- Maintains depth influence duration
- Should match Soft Edge for consistency
- Strength:
- OpenPose ControlNet: Captures and transfers pose information for accurate movement.
- Strength:
- Controls pose preservation
- Higher = stricter pose following
- Lower = more flexible pose interpretation
- End percent:
- Maintains pose influence
- Keeps movement natural throughout process
- Strength:
Face Processing
Nodes here handle face replacement and enhancement for natural results. The process works in two stages: FaceRestore first enhances the original face quality, then ReActor performs the swap using the enhanced face as reference. This two-stage process ensures natural integration while preserving expressions.
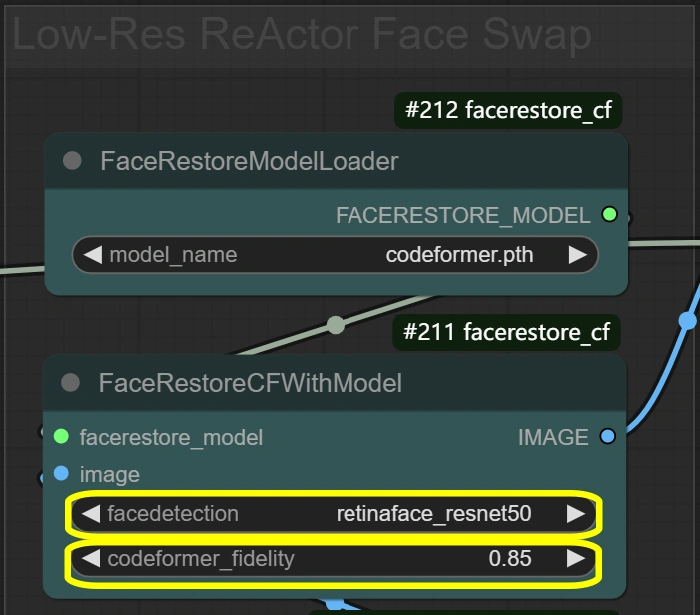
- FaceRestore System: Enhances facial details and prepares for swapping.
- Fidelity:
- Controls detail preservation in restoration
- Higher = more detailed but potential artifacts
- Lower = smoother but may lose details
- Detection:
- Face detection model choice
- Reliable for most scenarios
- Don't change unless faces aren't detected
- Fidelity:
- ReActor Face Swap: Performs face replacement and blending with preserved expressions.
- Visibility:
- Controls swap visibility
- Higher = stronger face swap effect
- Lower = more subtle blending
- Weight:
- Face feature preservation balance
- Higher = stronger source face features
- Lower = better blending with target
- Console log level:
- Controls debugging information
- Higher = more detailed logs
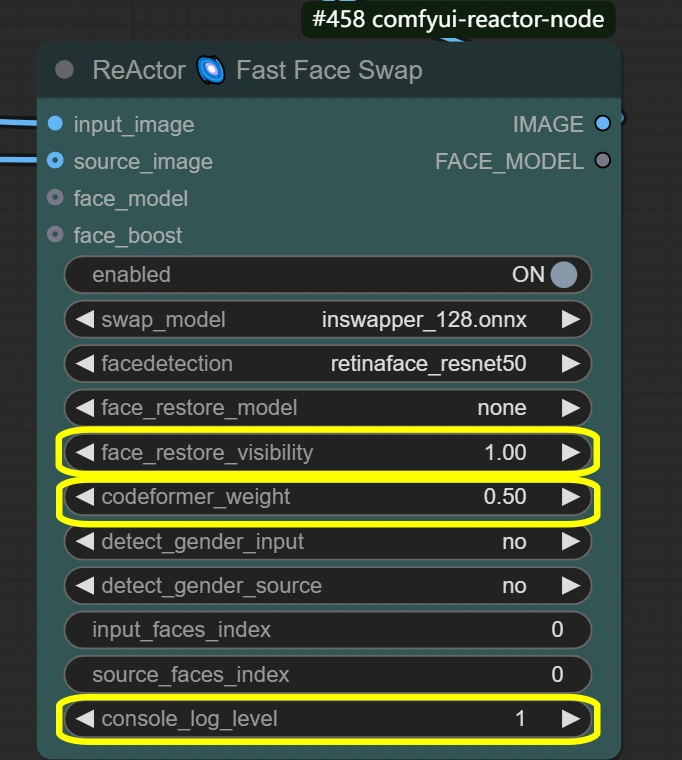
- Visibility:
Additional Node Details
Input & Preprocessing
Purpose: Loads video, adjusts dimensions, and prepares VAE model for processing.
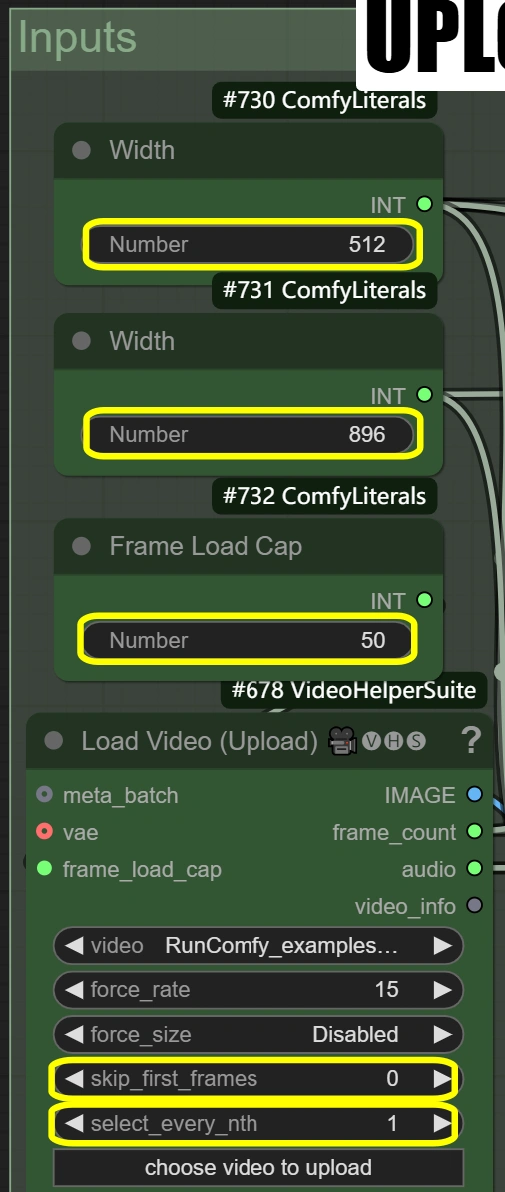
- Load Video:
- Frame Load Cap:
- Controls number of frames to process
- 50 = quick test (processes ~2 seconds)
- 0 = process entire video
- Affects total processing time
- Skip First Frames:
- Defines starting point in video
- Higher = starts later in video
- Useful for skipping intros
- Select Every Nth:
- Controls frame sampling rate
- Higher numbers skip frames
- 1 = use every frame
- 2 = use every second frame, etc.
- Frame Load Cap:
- Image Scale:
- Width: 512
- Controls output frame width
- Must maintain 9:16 ratio with height
- Height: 896
- Controls output frame height
- Must maintain 9:16 ratio with width
- Method: nearest-exact
- Best for maintaining sharpness
- Alternatives may blur content
- Recommended for dance videos
- Don't change unless specific needs
- Width: 512
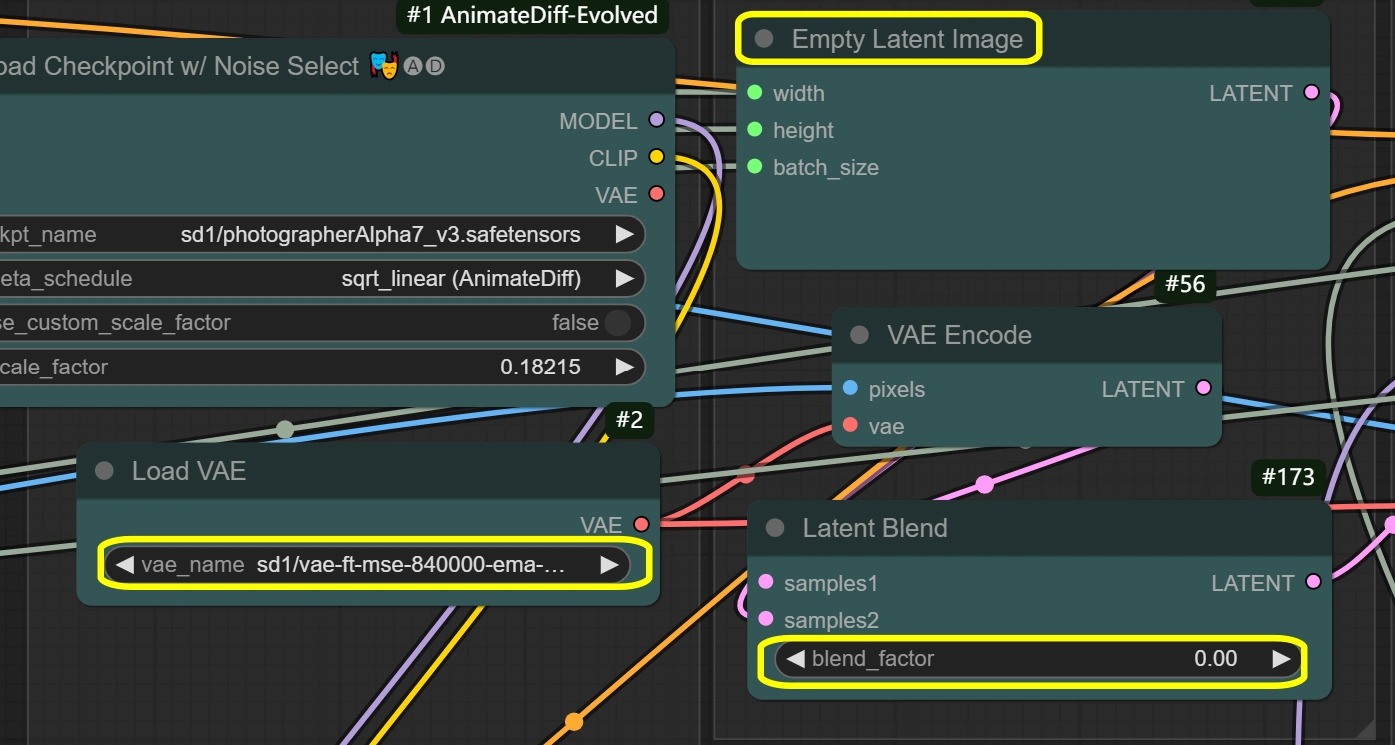
- VAE Loader:
- Model: vae-ft-mse-840000-ema-pruned
- Optimized for stability and quality
- Handles image encoding/decoding
- Balanced compression ratio
- Don't change unless specific needs
- VAE Mode: Don't change
- Optimized for current workflow
- Affects encoding quality
- Model: vae-ft-mse-840000-ema-pruned
Latent Processing
Purpose: Handles all latent space operations and transformations.
- Empty Latent Image:
- Width/Height: matches input
- Must match Image Scale dimensions
- Affects memory usage directly
- Larger sizes need more VRAM
- Can't be smaller than input
- Batch Size: from video frames
- Set automatically from frame count
- Affects processing speed and VRAM
- Higher = more memory needed
- Width/Height: matches input
- VAE Encode:
- VAE Model: from VAE Loader
- Uses settings from VAE Loader
- Maintains consistency
- Decode: enabled
- Controls decoding quality
- Disable only if VRAM limited
- Affects output quality
- VAE Model: from VAE Loader
- Latent Blend:
- Blend Factor:
- Controls mixing of latent spaces
- 0 = full source content
- Higher = more empty latent influence
- Affects style transfer strength
- Blend Factor:
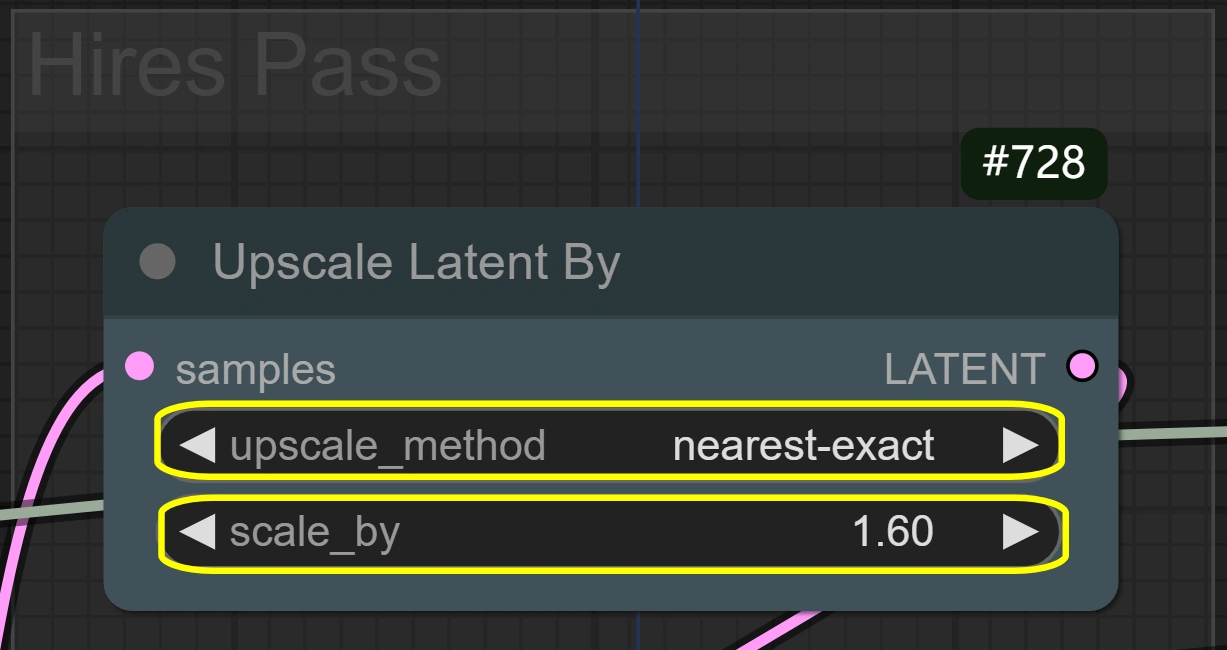
- Latent Upscale By:
- Method: nearest-exact
- Best for maintaining sharpness
- Alternative methods may blur
- Preserves motion details
- Scale:
- Controls size increase
- Higher = better detail but more VRAM
- Lower = faster processing
- 1.6 optimal for most cases
- Method: nearest-exact
Sampling & Refinement
Purpose: Two-stage sampling process for quality transformation.
- KSampler (First Pass):
- Steps:
- Number of denoising steps
- Higher = better quality but slower
- 6 optimal for lcm sampler
- CFG:
- Controls prompt influence
- Higher = stronger style adherence
- Lower = more freedom
- Sampler: lcm
- Optimized for speed
- Good quality/speed balance
- Scheduler: sgm_uniform
- Works best with lcm
- Maintains temporal consistency
- Denoise:
- Full strength for first pass
- Controls transformation intensity
- Steps:
- KSampler (Hires Pass):
- Steps:
- Matches first pass for consistency
- Higher not needed for refinement
- CFG:
- Maintains style consistency
- Balanced detail preservation
- Sampler: lcm
- Same as first pass
- Maintains consistency
- Scheduler: sgm_uniform
- Maintains consistency with first pass
- Good for detail refinement
- Denoise:
- Lower than first pass
- Preserves more original detail
- Good balance for refinement
- Steps:
Output Processing
Purpose: Creates final video outputs with and without face swap.
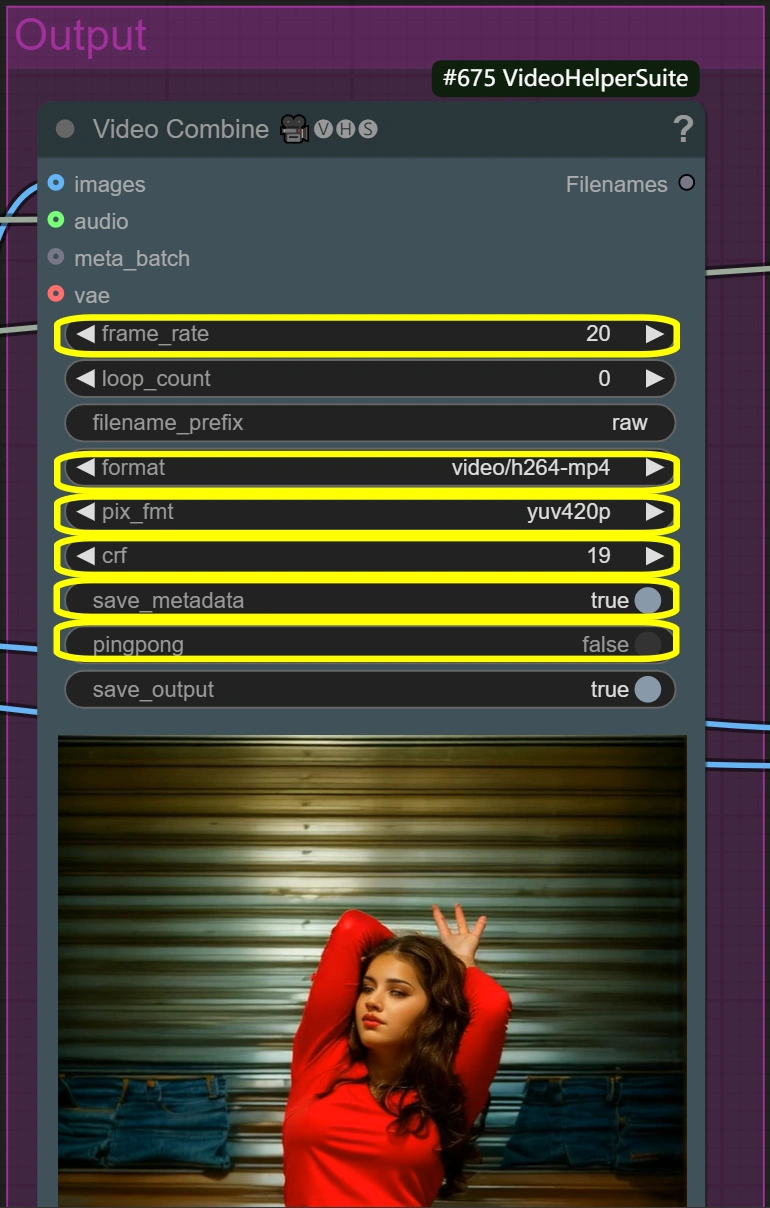
- Video Combine (Raw):
- Frame Rate:
- Standard video frame rate
- Controls playback speed
- Lower = smaller file size
- Higher = smoother motion
- Format: video/h264-mp4
- Standard format for compatibility
- Good balance of quality/size
- Widely supported
- CRF:
- Controls compression quality
- Lower = better quality but larger file
- Higher = smaller file but lower quality
- 19 is high quality setting
- Pixel Format: yuv420p
- Standard format for compatibility
- Don't change unless needed
- Ensures wide playback support
- Frame Rate:
- Video Combine (Face Swap):
- Same parameters as raw output
- Uses identical settings for consistency
- Adds face swap integration
- Maintains video quality settings
Optimization Tips
Quality vs Speed Trade-offs
- Resolution Balance:
- Standard: 512x896
- Faster processing
- Good for most uses
- High Quality: 768x1344
- Better detail
- 2-3x longer processing time
- Standard: 512x896
- Face Swap Quality:
- Standard: Default settings
- Natural integration
- Balanced processing time
- Maximum Quality:
- Increase codeformer_fidelity to 0.9
- Slower but more detailed faces
- Standard: Default settings
- Motion Smoothness:
- Faster Processing:
- Reduce context_overlap to 2
- Slightly less smooth transitions
- Better Motion:
- Increase overlap to 6
- Uses more VRAM, slower processing
- Faster Processing:
Common Issues & Solutions
- Face Blending:
- Issue: Unnatural face transition
- Solution: Adjust codeformer_weight
- Try range 0.4-0.7
- Lower = better blending
- Higher = more facial details
- Style Strength:
- Issue: Weak style transfer
- Solution: Increase cfg
- Try range 7-8
- Higher = stronger style
- May affect motion quality
- Memory Management:
- Issue: VRAM limitations
- Solutions:
- Enable VAE slicing
- Reduce resolution
- Process shorter segments
More Information
For additional details and amazing creations, please visit junkboxai's Instagram.
