Flux & 10 In-Context LoRA Models
This Flux In-Context LoRA (IC-LoRA) workflow offers 10 powerful LoRA models for task-agnostic image generation using diffusion transformers. These models cover a wide range of creative applications, including couple profile design, film storyboarding, font design, home decoration, portrait illustration and photography, PPT templates, visual effects (sandstorm and sparklers), and visual identity design. Each model leverages DiTs' in-context learning capabilities and requires only small datasets for efficient task-specific tuning.ComfyUI Flux In-Context LoRA Workflow
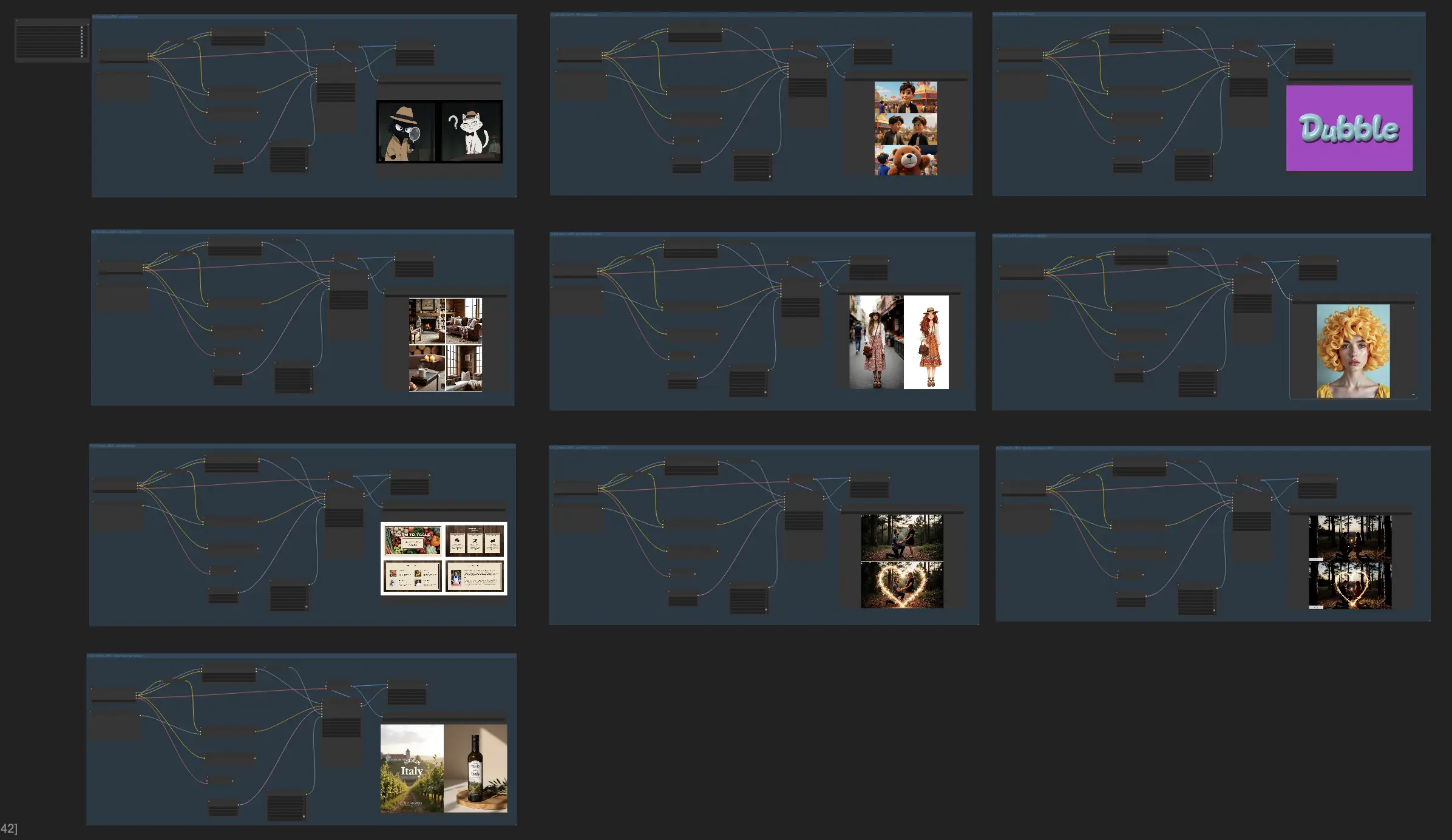
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI Flux In-Context LoRA Examples











ComfyUI Flux In-Context LoRA Description
The In-Context LoRA (IC-LoRA) project, developed by Lianghua Huang, Wei Wang, Zhi-Fan Wu, and their collaborators at Tongyi Lab, represents a groundbreaking approach to task-agnostic image generation using diffusion transformers (DiTs). Their innovative framework leverages DiTs’ in-context generation capabilities by introducing minimal tuning and a streamlined pipeline, allowing for efficient task-specific tuning with small datasets. To learn more about their work and access their resources, visit the official repository at .
1. About In-Context LoRA (IC-LoRA)
In-Context LoRA (IC-LoRA) is a powerful and flexible framework that enables existing text-to-image diffusion transformer models to perform a wide variety of image generation tasks with minimal additional training. The key idea behind In-Context LoRA is to leverage the inherent in-context learning capabilities of these models by providing them with carefully curated training data and using a simple yet effective fine-tuning approach.
Here's how In-Context LoRA works in a nutshell:
- Image Concatenation: Instead of generating individual images, IC-LoRA concatenates a set of related items into a single large composite. This allows the model to learn the relationships and consistency required across the set..
- Prompt Engineering: The text prompts for the set are also concatenated into a single prompt. This prompt starts with an overall description of the set, followed by specific details for each individual item. By crafting the prompt this way, the model can understand the high-level task as well as the low-level requirements.
- Low-Rank Adaptation (LoRA): Rather than fine-tuning the entire diffusion model, which would be computationally expensive, IC-LoRA uses LoRA to adapt the model to each specific task. LoRA only trains a small set of auxiliary parameters, keeping the original model weights frozen. This makes the fine-tuning process much more efficient.
- Small Training Datasets: Another key insight of IC-LoRA is that you don't need massive datasets to trigger the in-context learning capabilities. Just 20-100 high-quality image sets per task are sufficient to achieve impressive results. This greatly reduces the data collection and computation burden.
The beauty of In-Context LoRA is that it is a task-agnostic framework. The same approach can be applied to a wide range of tasks, such as storyboard generation, font design, product design, visual effects, and more. By providing task-specific training data, IC-LoRA can adapt to each task without requiring any change to the model architecture itself.
2. 10 In-Context LoRA models and their recommend settings
| Task | Model | Recommend Settings | Example Prompt |
|---|---|---|---|
| 1. Couple Profile Design | couple-profile.safetensors | width: 2048, height: 1024 | This two-part image portrays a couple of cartoon cats in detective attire; [LEFT] a black cat in a trench coat and fedora holds a magnifying glass and peers to the right, while [RIGHT] a white cat with a bow tie and matching hat raises an eyebrow in curiosity, creating a fun, noir-inspired scene against a dimly lit background. |
| 2. Film Storyboard | film-storyboard.safetensors | width: 1024, height: 1536 | [MOVIE-SHOTS] In a vibrant festival, [SCENE-1] we find <Leo>, a shy boy, standing at the edge of a bustling carnival, eyes wide with awe at the colorful rides and laughter, [SCENE-2] transitioning to him reluctantly trying a daring game, his friends cheering him on, [SCENE-3] culminating in a triumphant moment as he wins a giant stuffed bear, his face beaming with pride as he holds it up for all to see. |
| 3. Font Design | font-design.safetensors | width: 1792, height: 1216 | The four-panel image showcases a playful bubble font in a vibrant pop-art style. [TOP-LEFT] displays "Pop Candy" in bright pink with a polka dot background; [TOP-RIGHT] shows "Sweet Treat" in purple, surrounded by candy illustrations; [BOTTOM-LEFT] has "Yum!" in a mix of bright colors; [BOTTOM-RIGHT] shows "Delicious" against a striped background, perfect for fun, kid-friendly products. |
| 4. Home Decoration | home-decoration.safetensors | width: 1344, height: 1728 | This four-panel image showcases a rustic living room with warm wood tones and cozy decor elements; [TOP-LEFT] features a large stone fireplace with wooden shelves filled with books and candles; [TOP-RIGHT] shows a vintage leather sofa draped in plaid blankets, complemented by a mix of textured cushions; [BOTTOM-LEFT] displays a corner with a wooden armchair beside a side table holding a steaming mug and a classic book; [BOTTOM-RIGHT] captures a cozy reading nook with a window seat, a soft fur throw, and decorative logs stacked neatly. |
| 5. Portrait Illustration | portrait-illustration.safetensors | width: 1152, height: 1088 | This two-panel image presents a transformation from a realistic portrait to a playful illustration, capturing both detail and artistic flair; [LEFT] the photograph shows a woman standing in a bustling marketplace, wearing a wide-brimmed hat, a flowing bohemian dress, and a leather crossbody bag; [RIGHT] the illustration panel exaggerates her accessories and features, with the bohemian dress depicted in vibrant patterns and bold colors, while the background is simplified into abstract market stalls, giving the scene an animated and lively feel. |
| 6. Portrait Photography | portrait-photography.safetensors | width: 1344, height: 1728 | This [FOUR-PANEL] image illustrates a young artist's creative process in a bright and inspiring studio; [TOP-LEFT] she stands before a large canvas, brush in hand, adding vibrant colors to a partially completed painting, [TOP-RIGHT] she sits at a cluttered wooden table, sketching ideas in a notebook with various art supplies scattered around, [BOTTOM-LEFT] she takes a moment to step back and observe her work, adjusting her glasses thoughtfully, and [BOTTOM-RIGHT] she experiments with different textures by mixing paints directly on the palette, her focused expression showcasing her dedication to her craft. |
| 7. PPT Template | ppt-templates.safetensors | width: 1984, height: 1152 | This four-panel image showcases a rustic-themed PowerPoint template for a culinary workshop; [TOP-LEFT] introduces "Farm to Table Cooking" in warm, earthy tones; [TOP-RIGHT] organizes workshop sections like "Ingredients," "Preparation," and "Serving"; [BOTTOM-LEFT] displays ingredient lists for seasonal produce; [BOTTOM-RIGHT] includes chef profiles with short bios. |
| 8. Sandstorm Visual Effect | sandstorm-visual-effect.safetensors | width: 1408, height: 1600 | [SANDSTORM-PSA] This two-part image showcases the transformation of a cyclist through a sandstorm visual effect; [TOP] the upper panel features a cyclist in vibrant gear pedaling steadily on a clear, open road with a serene sky in the background, highlighting focus and determination, [BOTTOM] the lower panel transforms the scene as the cyclist becomes enveloped in a fierce sandstorm, with sand particles swirling intensely around the bike and rider against a stormy, darkened backdrop, emphasizing chaos and power. |
| 9. Sparklers Visual Effect | sparklers-visual-effect.safetensors | width: 960, height: 1088 | [REAL-SPARKLERS-OVERLAYS] The two-part image vividly illustrates a woodland proposal transformed by sparkler overlays; [TOP] the first panel depicts a man kneeling on one knee with an engagement ring before his partner in a forest clearing at dusk, with warm, natural lighting, [BOTTOM] while the second panel introduces glowing sparklers that form a heart shape around the couple, amplifying the romance and joy of the moment. |
| 10. Visual Identity Design | visual-identity-design.safetensors | width: 1472, height: 1024 | The two-panel image showcases the joyful identity of a produce brand, with the left panel showing a smiling pineapple graphic and the brand name “Fresh Tropic” in a fun, casual font on a light aqua background; [LEFT] while the right panel translates the design onto a reusable shopping tote with the pineapple logo in black, held by a person in a market setting, emphasizing the brand’s approachable and eco-friendly vibe. |
3. Use Flux and In-Context LoRA in ComfyUI
This Flux and In-Context LoRA workflow utilizes the powerful combination of the Flux model and the In-Context LoRA to generate a set of related images based on a text prompt. Let's break down how it works step by step.
3.1. Preloaded Flux and In-Context LoRA Models for Efficient Workflow
Our platform already has the Flux model and 10 In-Context LoRA models ready for you to use. This makes your workflow easier and saves you time. Just choose the group you want and start creating.
3.2. Crafting the Perfect Prompt based on the preset prompts
The most important part of this workflow is the text description that captures the main idea you want to create. We have already written prompts for each In-Context LoRA model in the list mentioned earlier. When you write your own prompt, please use these examples as a guide.
3.3. Customizing Resolution and Dimensions
To create visuals that fit your needs perfectly, change the width and height settings to match the size you want. We have also provided recommended sizes of each In-Context LoRA model for you to use as a starting point.
3.4. Flux Sampler
The Flux Sampler node manages the Flux sampling process and optimizes generation parameters for better results. Key parameters include:
- Seed (1): The seed value ensures consistent outputs under the same settings. Adjusting the seed allows the Flux generation to produce varied results.
- Steps (50): This parameter defines the number of steps in the Flux sampling process. Higher step counts enhance quality but require more processing time. Here, 50 steps offer a balanced option.
- Guidance (3): Determines guidance strength. Higher values (e.g., 3) align the Flux-generated output more closely with input prompts, ensuring accurate representations of your intent.
- Max Shift (null): This parameter defines the maximum displacement or transformation range. A "null" setting indicates default or unlimited range usage.
- Base Shift (null): Similar to max shift, it adjusts the base transformation strength. Setting it to "null" applies the default configuration.
- Denoise (1): Adjusts denoising strength during Flux generation. A value of 1 applies light denoising, effectively removing minor inconsistencies while retaining clarity.
The combination of Flux and In-Context LoRA opens up a world of possibilities for creating interesting visual content. Try out these new models and unleash your creativity like never before.
License
View license files:
The FLUX.1 [dev] Model is licensed by Black Forest Labs. Inc. under the FLUX.1 [dev] Non-Commercial License. Copyright Black Forest Labs. Inc.
IN NO EVENT SHALL BLACK FOREST LABS, INC. BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH USE OF THIS MODEL.


