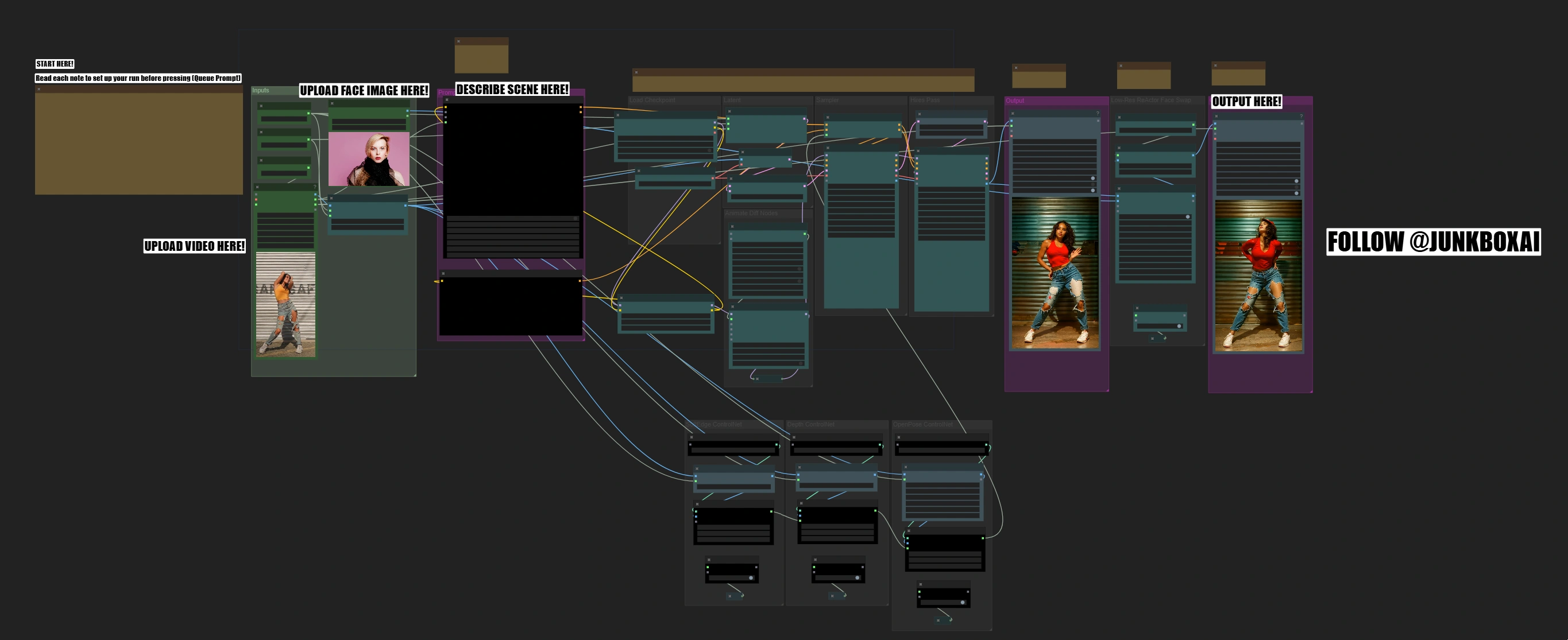
Dance Video Transform | Szenenanpassung & Face Swap
Dieser Dance Video Transform-Workflow kombiniert das SD1.5-Modell, AnimateDiff, ControlNet und ReActor Gesichtstausch, um hochwertige Choreografie-Transformationen zu liefern. Er bewahrt die Bewegung des Tänzers durch dreifache ControlNet-Steuerung (Edge, Depth und OpenPose), während ReActor und CodeFormer für einen präzisen Gesichtstausch mit erhöhter Treue sorgen. Der Workflow unterstützt die dynamische Szenensteuerung durch Batch-Prompt-Planung, die eine frame-spezifische Anpassung ermöglicht. Mit den Kontextoptionen von AnimateDiff und der adaptiven Bewegungsanpassung wird eine reibungslose und natürliche Bewegungserhaltung während der gesamten Transformation gewährleistet.ComfyUI Dance Video Transform Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Dance Video Transform Beispiele
ComfyUI Dance Video Transform Beschreibung
Was der Dance Video Transform ComfyUI Workflow macht
Der Dance Video Transform ComfyUI Workflow verwandelt Tanzvideos in atemberaubende neue Szenen mit professionellem Gesichtstausch, während die ursprüngliche Choreografie erhalten bleibt und eine hohe Ausgabequalität sichergestellt wird. Der Prozess erfolgt in Phasen, von der Bewegungsanalyse bis zum Gesichtsaustausch, sodass in jedem Schritt Qualitätskontrollen durchgeführt werden können.
Wie der Dance Video Transform ComfyUI Workflow funktioniert
Der Workflow verwandelt Ihr Tanzvideo, indem er diese komplexen Transformationen in mehreren Phasen automatisiert, wobei nur Ihr Video, ein Gesichtsbild und eine Szenenbeschreibung erforderlich sind: Bewegungsanalyse → Stiltransfer → Gesichtsaustausch
- Analysiert Tanzbewegungen und räumliche Informationen
- Verwandelt die Szene gemäß Ihrer Beschreibung
- Integriert neues Gesicht unter Beibehaltung der Gesichtsausdrücke
Hauptmerkmale des Dance Video Transform ComfyUI Workflow
- Optimiert für vertikales Format (9:16 Seitenverhältnis)
- Dreifaches ControlNet-System für stabile Transformationen
- Professioneller Gesichtstausch mit natürlicher Integration
- Schneller Testmodus (verarbeitet 50 Frames in Minuten)
- Unterstützung für hochauflösende Ausgaben (bis zu 896px Höhe)
- Fortschrittliche Bewegungserhaltung mit AnimateDiff
- Duales Ausgabesystem zur Qualitätsüberprüfung
Schnellstartanleitung
Schritt 1: Erste Einrichtung
In den jeweiligen Knoten:
-
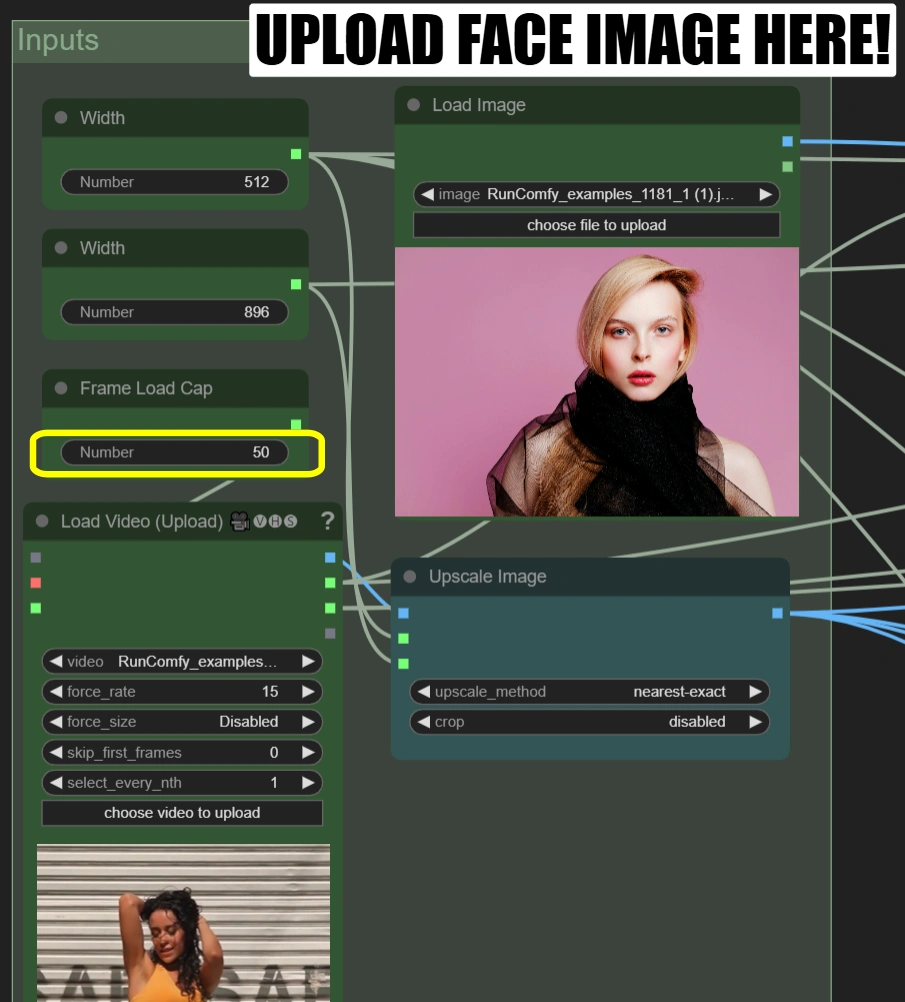
Video laden (Hochladen):
- Laden Sie ein 10-15 Sekunden langes Tanzvideo mit einem 9:16 Seitenverhältnis hoch
- Wenn Ihr Video nicht im 9:16-Format vorliegt, müssen Sie die Parameter Breite und Höhe an Ihr Video anpassen.
- Frame-Ladegrenze: 50 (rendern Sie nur die ersten 50 Frames für einen schnellen Test)
-
Bild laden:
- Laden Sie ein klares, frontal aufgenommenes Gesichtsfoto hoch
-
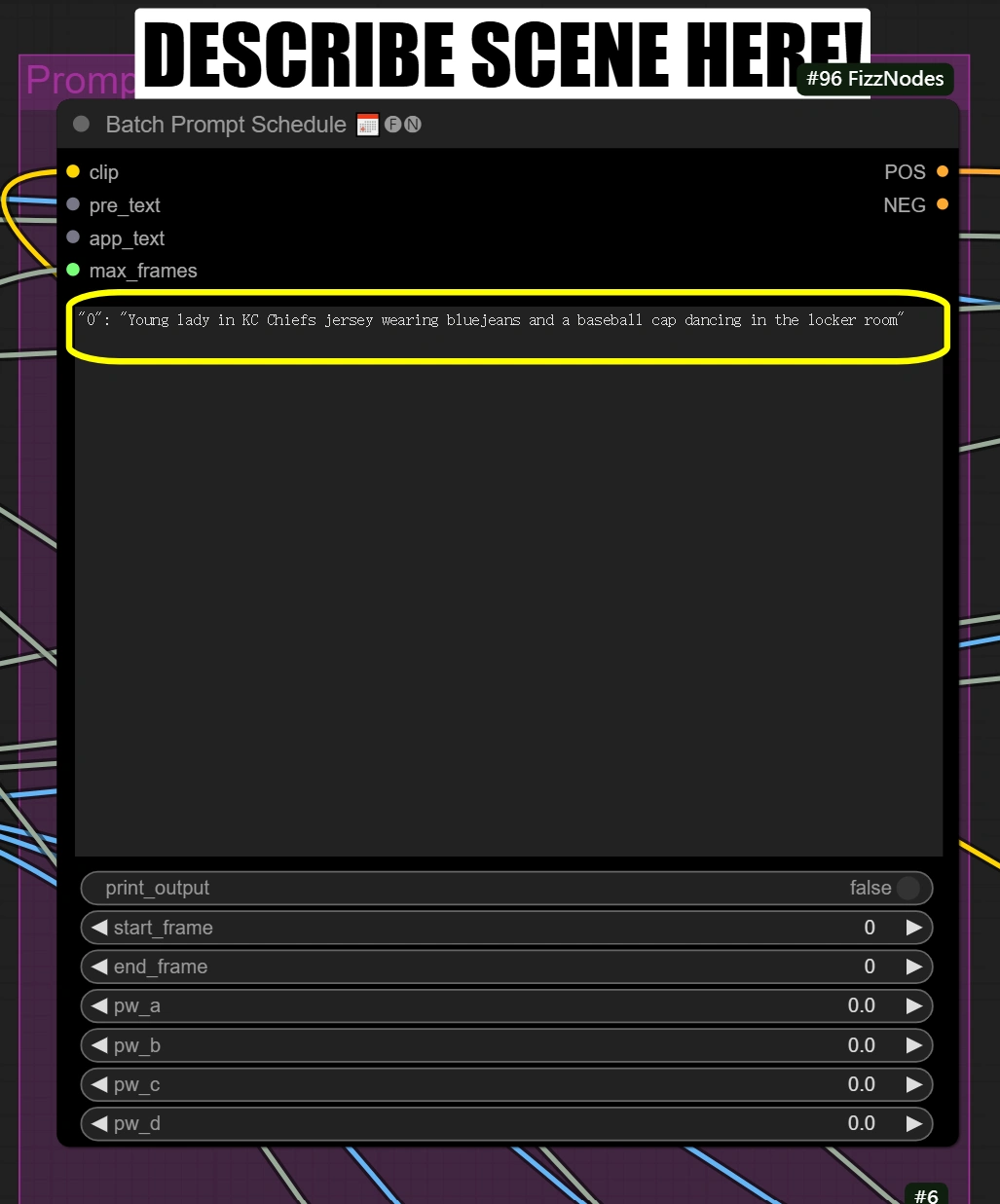
Batch-Prompt-Planung:
- Beschreiben Sie die Szene und alle anderen Aspekte, die Sie transformieren möchten
"0": "[person] in KC Chiefs jersey wearing bluejeans and a baseball cap dancing in the locker room"
- Setzen Sie gegebenenfalls einen negativen Prompt
Schritt 2: Schneller Testlauf
- Klicken Sie auf "Queue Prompt"
- Dies verarbeitet ~2 Sekunden des Videos
- Sie erhalten zwei Ausgaben:
- Erste Ausgabe: Nur Szenentransformation
- Zweite Ausgabe: Mit Gesichtstausch angewendet

Schritt 3: Vollständige Videobearbeitung
Nur wenn der schnelle Test gut aussieht:
- Gehen Sie zurück zum "Video laden"-Knoten
- Ändern Sie die Frame-Ladegrenze auf 0 für das gesamte Video
- Klicken Sie auf "Queue Prompt" für die vollständige Verarbeitung (Dies dauert erheblich länger)
Tipps für Anfänger
- Folgen Sie den Notizen: Achten Sie auf alle Notizen in der Benutzeroberfläche – sie führen Sie schrittweise
- Sorgen Sie sich nicht um erweiterte Einstellungen: Meistens müssen Sie nichts über das hier Erwähnte hinaus anpassen
- Wichtigkeit des Seitenverhältnisses: Stellen Sie sicher, dass das Seitenverhältnis korrekt ist, sonst könnte das Video verzerrt oder beschnitten aussehen
Referenz für Hauptknoten
AnimateDiff-Einstellungen
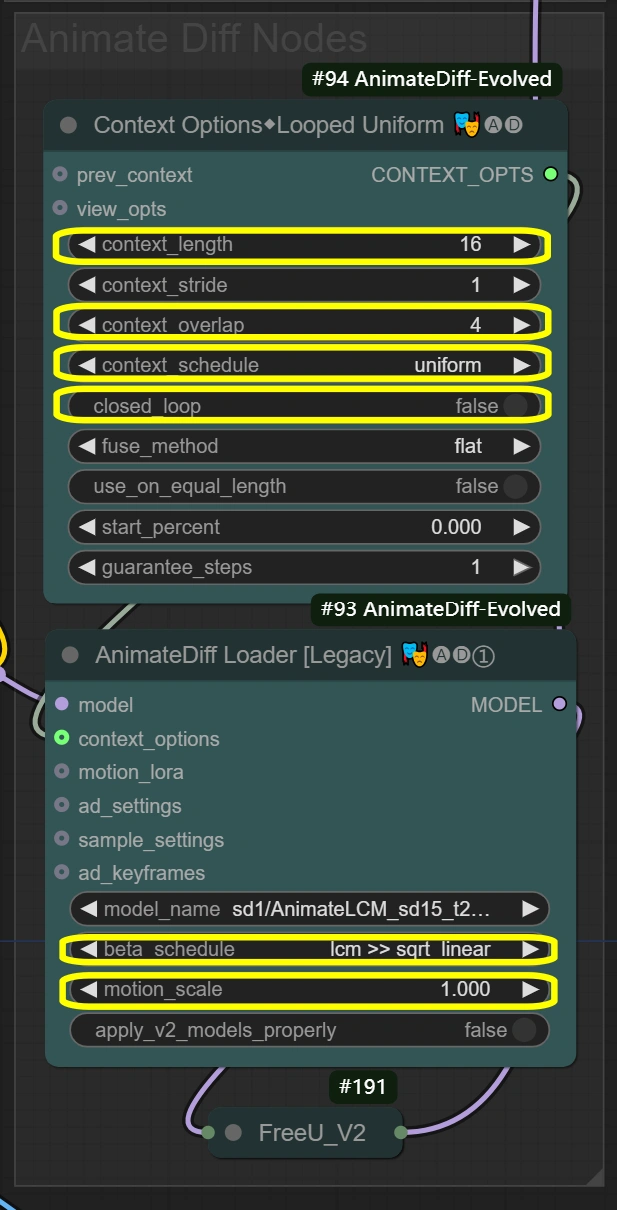
Hier definieren die Knoten eine reibungslose Bewegungserhaltung während der Videotransformation. Kontextoptionen bestimmen, wie Frames gruppiert und verarbeitet werden sollen, und übergeben diese Einstellungen an den AnimateDiff Loader, der dann die eigentliche Bewegungserhaltung anwendet. Die Einstellungen für Kontextlänge und Überlappung beeinflussen direkt, wie der AnimateDiff Loader die Bewegungsbeständigkeit aufrechterhält.
- Kontextoptionen-Knoten (#94): Erreicht die Gruppierung von Frames und die Kontrolle der zeitlichen Verarbeitung für konsistente Bewegungen.
- context_length:
- Bestimmt, wie viele Frames zusammen verarbeitet werden
- Höher = glatter, aber mehr VRAM-Nutzung
- Niedriger = schneller, aber möglicherweise Verlust der Bewegungskoherenz
- context_overlap:
- Behandelt die Glätte von Frame-Übergängen
- Höher = bessere Integration, aber langsamere Verarbeitung
- Niedriger = schneller, aber kann Übergangslücken zeigen
- context_schedule:
- Kontrolliert die Frame-Verteilung
- "uniform" am besten für Tanzbewegungen
- Nicht ändern, es sei denn, es gibt spezifische Bedürfnisse
- closed_loop:
- Steuert das Verhalten der Videoschleife
- True nur für perfekt schleifende Videos
- context_length:
- AnimateDiff Loader-Knoten (#93): Implementiert die Bewegungserhaltung mit dem AnimateDiff-Modell und wendet zeitliche Konsistenz an.
- motion_scale:
- Steuert die Bewegungsstärke
- Höher: Übertriebene Bewegung
- Niedriger: Gedämpfte Bewegung
- beta_schedule: lcm >> sqrt_linear
- Steuert das Abtastverhalten
- Optimiert für diesen Workflow
- Nicht ändern, es sei denn, es ist notwendig
- motion_scale:
ControlNet-Stack
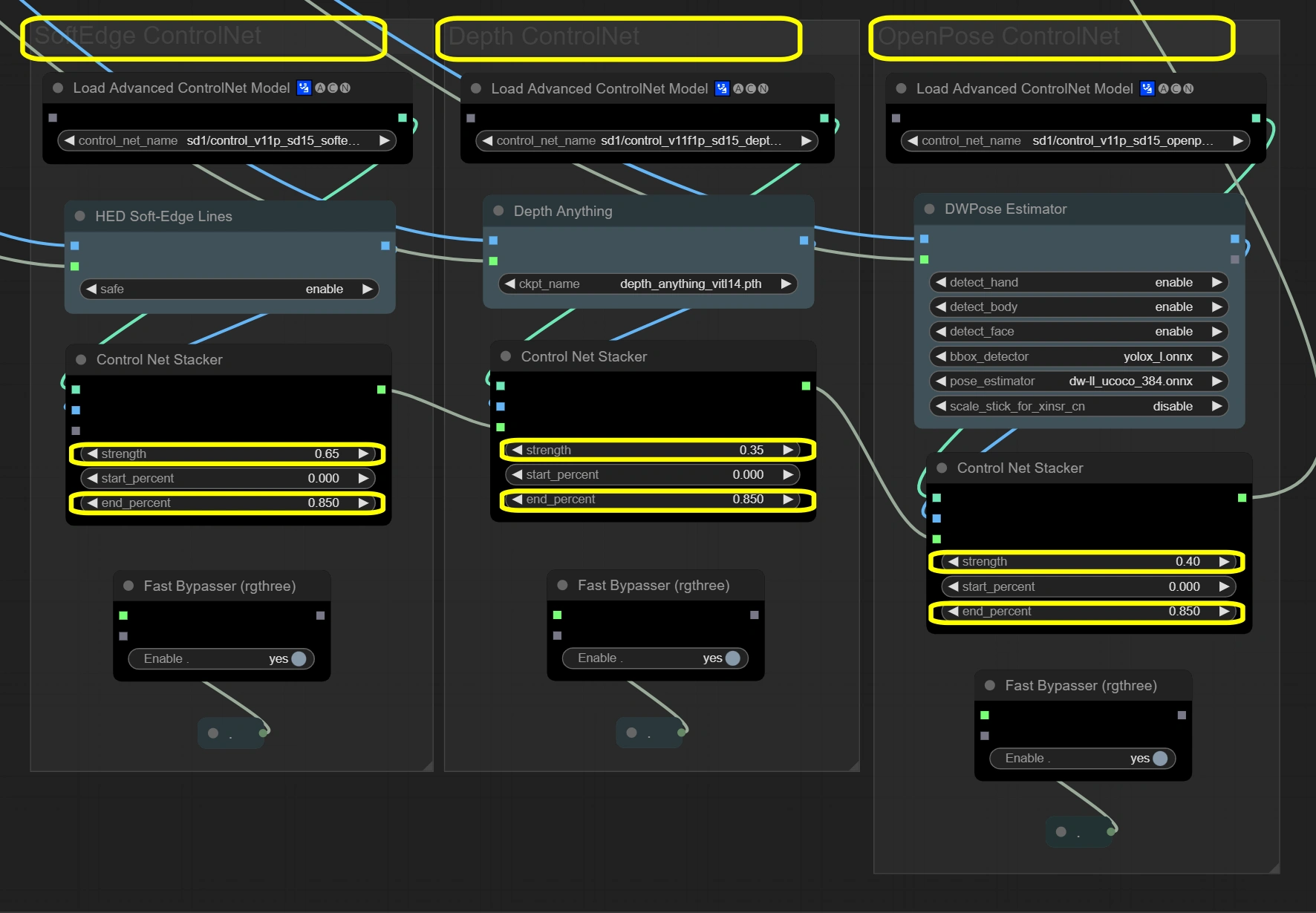
Die Knoten hier erhalten die Video-Integrität durch ein dreilagiges Steuerungssystem. Die drei ControlNets verarbeiten Eingabeframes gleichzeitig, wobei sich jedes auf verschiedene Aspekte konzentriert. Soft Edge bietet grundlegende Struktur, Depth fügt räumliches Verständnis hinzu, und OpenPose sorgt für Bewegungsgenauigkeit. Die Ergebnisse werden durch Stapler kombiniert, wobei die Gesamtstärke 1,4 für Stabilität nicht überschreiten darf.
- Soft Edge ControlNet: Extrahiert und bewahrt strukturelle Elemente und Formen aus den Originalframes.
- Stärke:
- Steuert die strukturelle Erhaltung
- Höher = stärkere Einhaltung der Originalformen
- Niedriger = mehr kreative Freiheit bei der Formänderung
- Endprozentsatz:
- Wann der Einfluss der Steuerung endet
- Höher = längerer Einfluss während des Prozesses
- Niedriger = erlaubt mehr Abweichung in späteren Schritten
- Stärke:
- Depth ControlNet: Verarbeitet räumliche Beziehungen und erhält 3D-Konsistenz.
- Stärke:
- Steuert das räumliche Bewusstsein
- Höher = stärkere 3D-Konsistenz
- Niedriger = mehr künstlerische Freiheit im Raum
- Endprozentsatz:
- Erhält die Dauer des Tiefeneinflusses
- Sollte mit Soft Edge für Konsistenz übereinstimmen
- Stärke:
- OpenPose ControlNet: Erfasst und überträgt Poseninformationen für genaue Bewegungen.
- Stärke:
- Steuert die Poseerhaltung
- Höher = striktere Pose-Verfolgung
- Niedriger = flexiblere Pose-Interpretation
- Endprozentsatz:
- Erhält die Posenbeeinflussung
- Hält die Bewegung während des Prozesses natürlich
- Stärke:
Gesichtsbearbeitung
Die Knoten hier kümmern sich um Gesichtsaustausch und -verbesserung für natürliche Ergebnisse. Der Prozess funktioniert in zwei Phasen: FaceRestore verbessert zuerst die ursprüngliche Gesichtqualität, dann führt ReActor den Austausch durch, wobei das verbesserte Gesicht als Referenz dient. Dieser zweistufige Prozess sorgt für eine natürliche Integration, während die Gesichtsausdrücke erhalten bleiben.
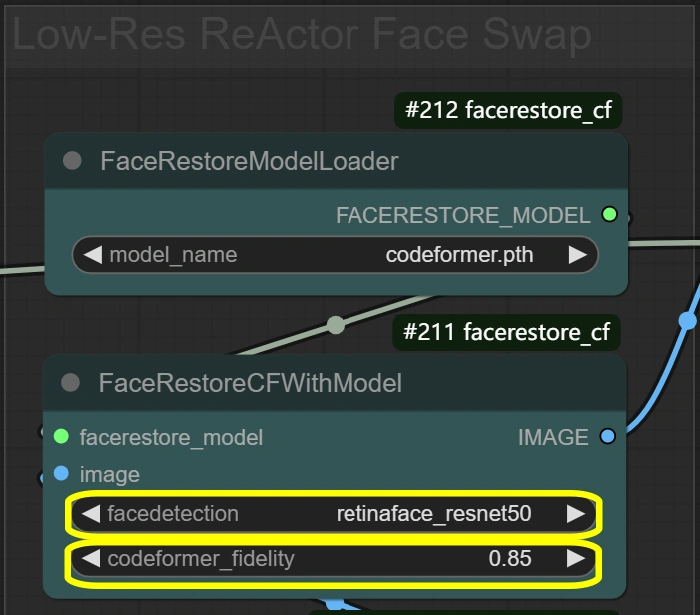
- FaceRestore-System: Verbessert die Gesichtsdetails und bereitet den Austausch vor.
- Treue:
- Steuert die Detailerhaltung bei der Wiederherstellung
- Höher = detaillierter, aber potentielle Artefakte
- Niedriger = glatter, aber möglicherweise Verlust von Details
- Erkennung:
- Wahl des Gesichtsdetektionsmodells
- Zuverlässig für die meisten Szenarien
- Nicht ändern, es sei denn, Gesichter werden nicht erkannt
- Treue:
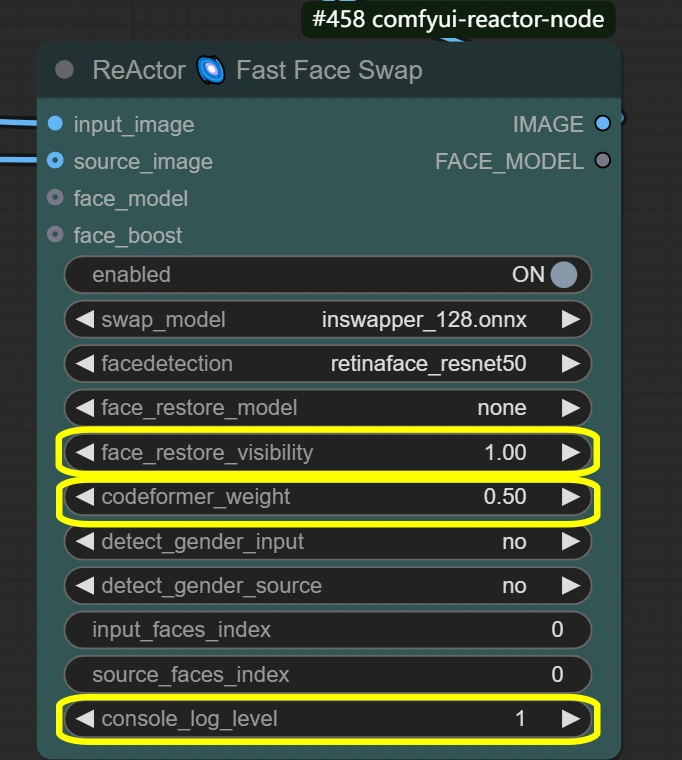
- ReActor Gesichtstausch: Führt den Gesichtsaustausch und die Integration mit erhaltenen Ausdrücken durch.
- Sichtbarkeit:
- Steuert die Sichtbarkeit des Austauschs
- Höher = stärkerer Gesichtstauscheffekt
- Niedriger = subtilere Integration
- Gewicht:
- Gleichgewicht der Gesichtszüge
- Höher = stärkere Quellgesichtszüge
- Niedriger = bessere Integration mit dem Ziel
- Konsolenprotokollstufe:
- Steuert Debug-Informationen
- Höher = detailliertere Protokolle
- Sichtbarkeit:
Zusätzliche Knotendetails
Eingabe & Vorverarbeitung
Zweck: Lädt Video, passt Abmessungen an und bereitet das VAE-Modell für die Verarbeitung vor.
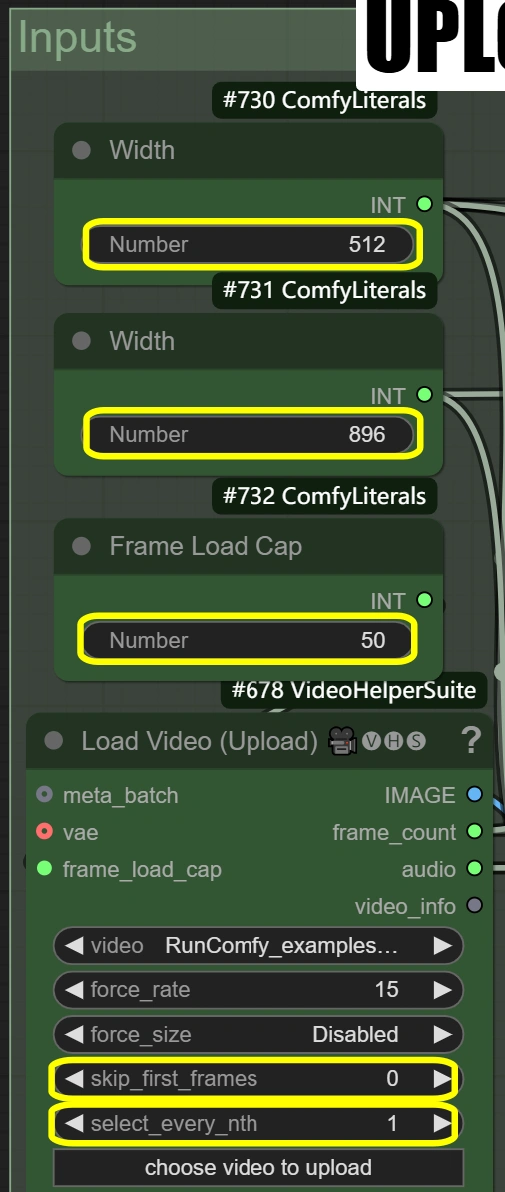
- Video laden:
- Frame-Ladegrenze:
- Steuert die Anzahl der zu verarbeitenden Frames
- 50 = schneller Test (verarbeitet ~2 Sekunden)
- 0 = verarbeitet das gesamte Video
- Beeinflusst die gesamte Verarbeitungszeit
- Erste Frames überspringen:
- Definiert den Startpunkt im Video
- Höher = beginnt später im Video
- Nützlich zum Überspringen von Intros
- Jeden N-ten auswählen:
- Steuert die Frame-Sampling-Rate
- Höhere Zahlen überspringen Frames
- 1 = jeden Frame verwenden
- 2 = jeden zweiten Frame verwenden, usw.
- Frame-Ladegrenze:
- Bildskalierung:
- Breite: 512
- Steuert die Breite des Ausgabe-Frames
- Muss das 9:16-Verhältnis mit der Höhe beibehalten
- Höhe: 896
- Steuert die Höhe des Ausgabe-Frames
- Muss das 9:16-Verhältnis mit der Breite beibehalten
- Methode: nearest-exact
- Am besten zur Beibehaltung der Schärfe
- Alternativen können Inhalte verwischen
- Empfohlen für Tanzvideos
- Nicht ändern, es sei denn, es gibt spezifische Bedürfnisse
- Breite: 512
- VAE Loader:
- Modell: vae-ft-mse-840000-ema-pruned
- Optimiert für Stabilität und Qualität
- Handhabt Bildcodierung/-decodierung
- Ausgewogenes Kompressionsverhältnis
- Nicht ändern, es sei denn, es gibt spezifische Bedürfnisse
- VAE-Modus: Nicht ändern
- Optimiert für aktuellen Workflow
- Beeinflusst die Codierungsqualität
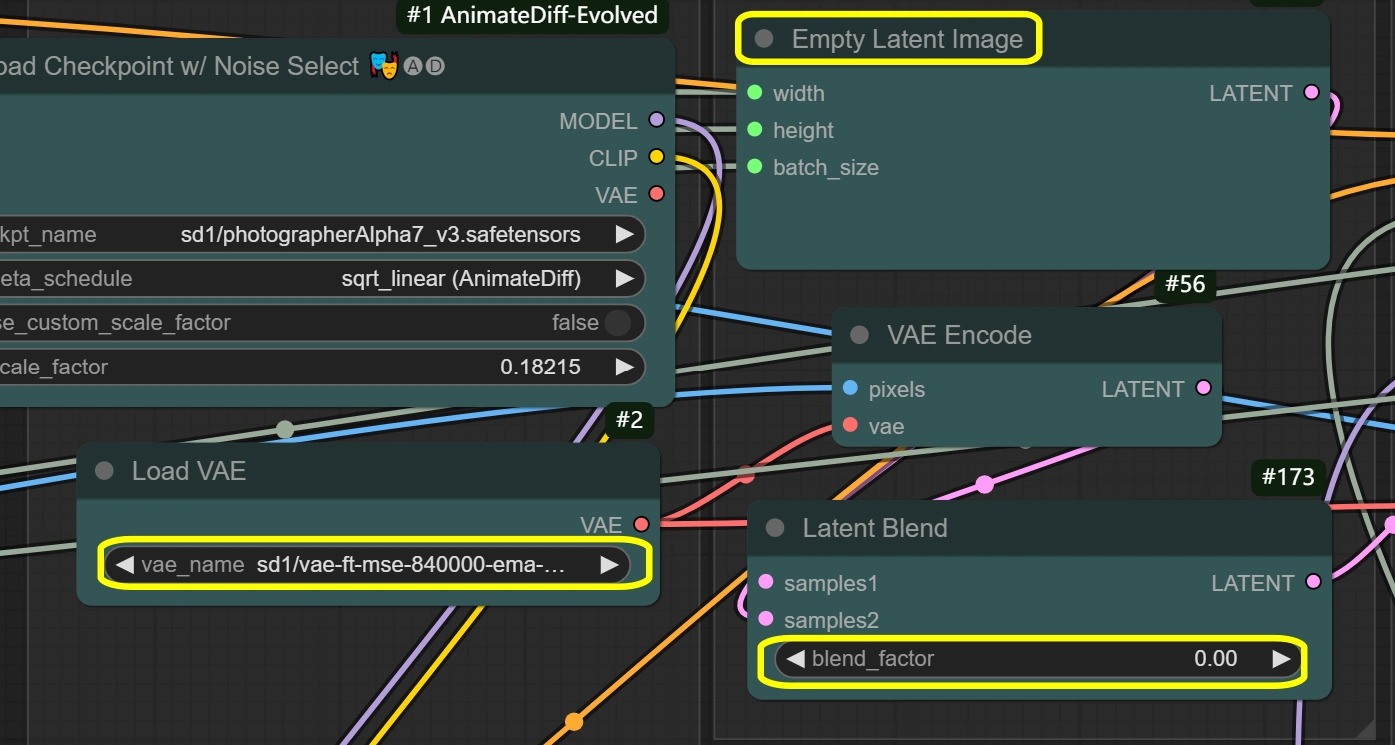
- Modell: vae-ft-mse-840000-ema-pruned
Latente Verarbeitung
Zweck: Handhabt alle Operationen und Transformationen im latenten Raum.
- Leeres latentes Bild:
- Breite/Höhe: entspricht der Eingabe
- Muss den Abmessungen der Bildskalierung entsprechen
- Beeinflusst direkt die Speichernutzung
- Größere Größen benötigen mehr VRAM
- Darf nicht kleiner als die Eingabe sein
- Batch-Größe: von Videoframes
- Automatisch aus der Frame-Anzahl gesetzt
- Beeinflusst Verarbeitungszeit und VRAM
- Höher = mehr Speicherbedarf
- Breite/Höhe: entspricht der Eingabe
- VAE-Codierung:
- VAE-Modell: aus dem VAE Loader
- Verwendet Einstellungen des VAE Loaders
- Bewahrt Konsistenz
- Decodierung: aktiviert
- Steuert die Decodierungsqualität
- Nur deaktivieren, wenn VRAM begrenzt
- Beeinflusst die Ausgabequalität
- VAE-Modell: aus dem VAE Loader
- Latente Mischung:
- Mischfaktor:
- Steuert die Mischung der latenten Räume
- 0 = vollständiger Quellinhalt
- Höher = mehr Einfluss des leeren Latenten
- Beeinflusst die Stärke des Stiltransfers
- Mischfaktor:
- Latente Hochskalierung durch:
- Methode: nearest-exact
- Am besten zur Beibehaltung der Schärfe
- Alternative Methoden können verwischen
- Bewahrt Bewegungsdetails
- Skalierung:
- Steuert die Größenvergrößerung
- Höher = bessere Details, aber mehr VRAM
- Niedriger = schnellere Verarbeitung
- 1.6 optimal für die meisten Fälle
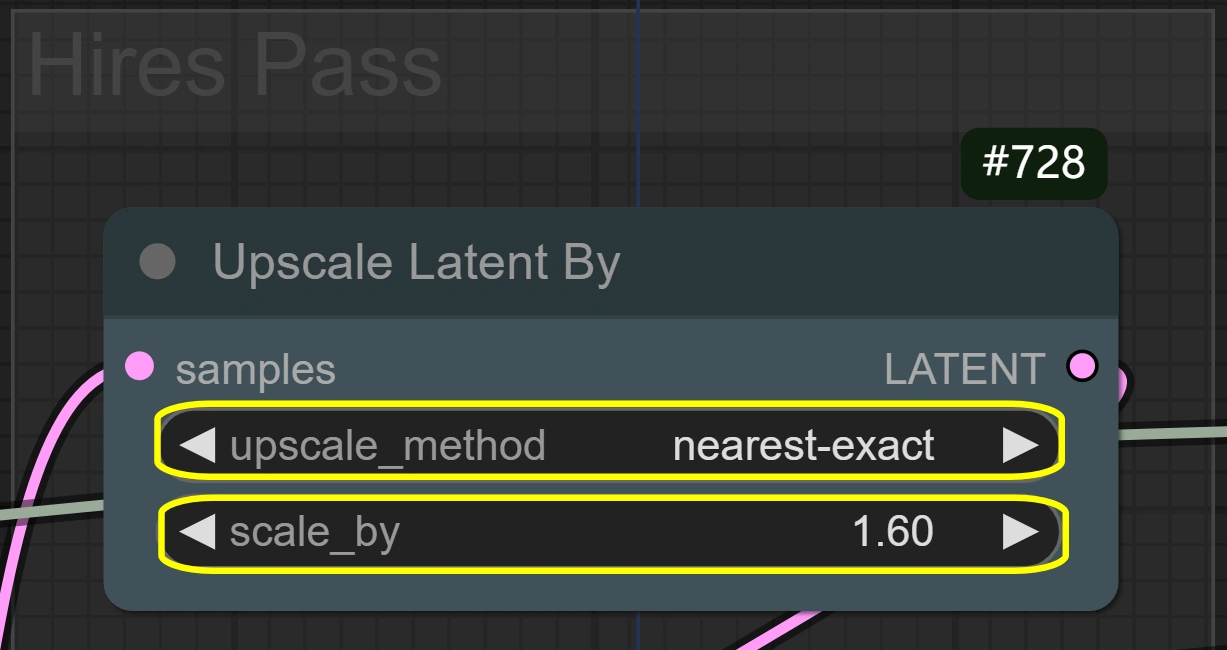
- Methode: nearest-exact
Abtastung & Verfeinerung
Zweck: Zweistufiger Abtastprozess für qualitativ hochwertige Transformation.
- KSampler (Erster Durchgang):
- Schritte:
- Anzahl der Entrauschungsschritte
- Höher = bessere Qualität, aber langsamer
- 6 optimal für lcm-Sampler
- CFG:
- Steuert den Einfluss des Prompts
- Höher = stärkere Stileinhaltung
- Niedriger = mehr Freiheit
- Sampler: lcm
- Optimiert für Geschwindigkeit
- Gute Balance zwischen Qualität und Geschwindigkeit
- Scheduler: sgm_uniform
- Funktioniert am besten mit lcm
- Bewahrt zeitliche Konsistenz
- Entrauschen:
- Volle Stärke für den ersten Durchgang
- Steuert die Intensität der Transformation
- Schritte:
- KSampler (Hires-Durchgang):
- Schritte:
- Entspricht dem ersten Durchgang für Konsistenz
- Höher nicht notwendig für Verfeinerung
- CFG:
- Bewahrt Stilkonsistenz
- Ausgewogene Detailerhaltung
- Sampler: lcm
- Gleich wie im ersten Durchgang
- Bewahrt Konsistenz
- Scheduler: sgm_uniform
- Bewahrt Konsistenz mit dem ersten Durchgang
- Gut für Detailverfeinerung
- Entrauschen:
- Niedriger als im ersten Durchgang
- Bewahrt mehr ursprüngliche Details
- Gute Balance für Verfeinerung
- Schritte:
Ausgabeverarbeitung
Zweck: Erstellt endgültige Videoausgaben mit und ohne Gesichtstausch.
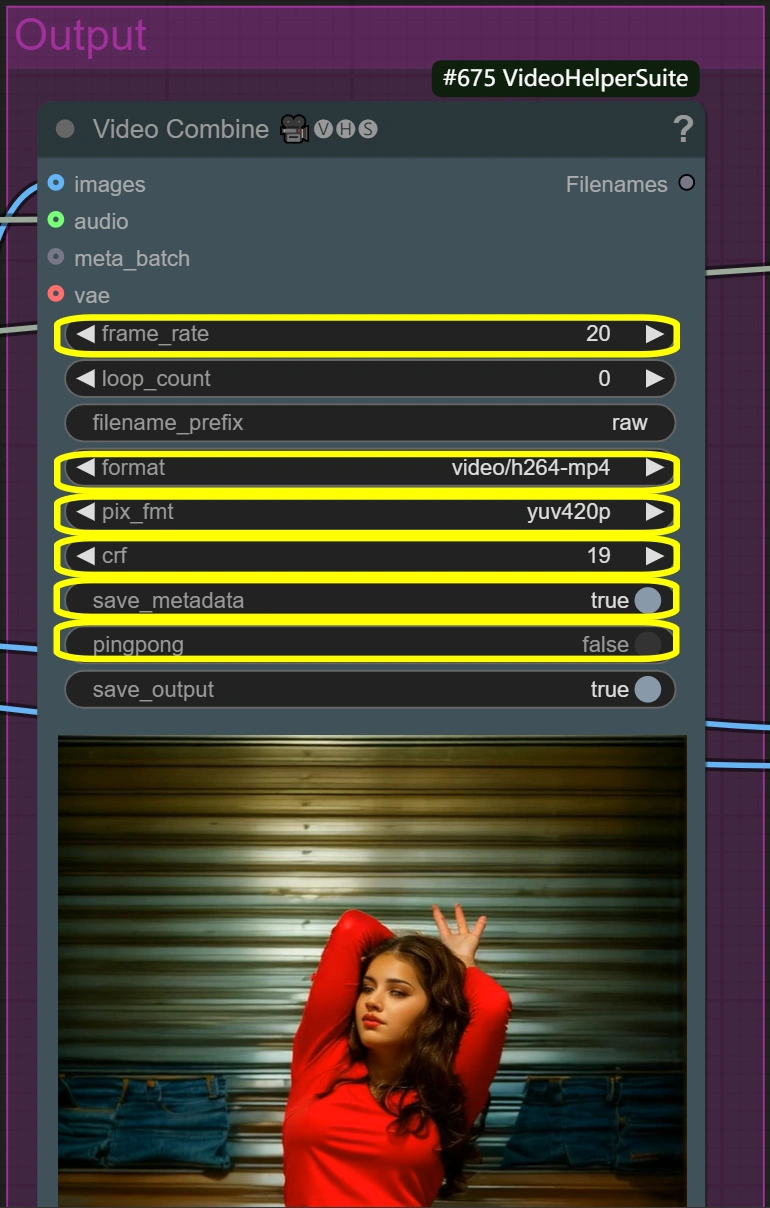
- Video Combine (Roh):
- Bildrate:
- Standard-Bildrate für Videos
- Steuert die Wiedergabegeschwindigkeit
- Niedriger = kleinere Dateigröße
- Höher = flüssigere Bewegung
- Format: video/h264-mp4
- Standardformat für Kompatibilität
- Gute Balance zwischen Qualität und Größe json
- Weit verbreitet unterstützt
- CRF:
- Steuert die Kompressionsqualität
- Niedriger = bessere Qualität, aber größere Datei
- Höher = kleinere Datei, aber geringere Qualität
- 19 ist eine hochwertige Einstellung
- Pixelformat: yuv420p
- Standardformat für Kompatibilität
- Nicht ändern, es sei denn, erforderlich
- Gewährleistet breite Wiedergabeunterstützung
- Bildrate:
- Video Combine (Gesichtstausch):
- Gleiche Parameter wie bei der Roh-Ausgabe
- Verwendet identische Einstellungen für Konsistenz
- Fügt Gesichtstausch-Integration hinzu
- Bewahrt Videoqualitätseinstellungen
Optimierungstipps
Qualität vs. Geschwindigkeit Kompromisse
- Auflösungsbalance:
- Standard: 512x896
- Schnellere Verarbeitung
- Gut für die meisten Anwendungen
- Hohe Qualität: 768x1344
- Bessere Details
- 2-3x längere Verarbeitungszeit
- Standard: 512x896
- Gesichtstausch-Qualität:
- Standard: Standardeinstellungen
- Natürliche Integration
- Ausgewogene Verarbeitungszeit
- Maximale Qualität:
- Erhöhen Sie codeformer_fidelity auf 0.9
- Langsamer, aber detailliertere Gesichter
- Standard: Standardeinstellungen
- Bewegungsglätte:
- Schnellere Verarbeitung:
- Reduzieren Sie context_overlap auf 2
- Etwas weniger glatte Übergänge
- Bessere Bewegung:
- Erhöhen Sie die Überlappung auf 6
- Benötigt mehr VRAM, langsamere Verarbeitung
- Schnellere Verarbeitung:
Häufige Probleme & Lösungen
- Gesichtsintegration:
- Problem: Unnatürlicher Gesichtübergang
- Lösung: Passen Sie codeformer_weight an
- Versuchen Sie den Bereich 0.4-0.7
- Niedriger = bessere Integration
- Höher = mehr Gesichtsdetails
- Stil-Stärke:
- Problem: Schwacher Stiltransfer
- Lösung: Erhöhen Sie cfg
- Versuchen Sie den Bereich 7-8
- Höher = stärkerer Stil
- Kann die Bewegungsqualität beeinflussen
- Speicherverwaltung:
- Problem: VRAM-Beschränkungen
- Lösungen:
- VAE-Slicing aktivieren
- Auflösung reduzieren
- Kürzere Segmente verarbeiten
Weitere Informationen
Für zusätzliche Details und erstaunliche Kreationen besuchen Sie bitte .

